MCP에 대해서 개괄적인 부분을 알고 싶으면 지난 포스팅을 참고하세요.
- MCP (Model Context Protocol) Overview
이번 포스팅에서는 MCP라는 것을 어떻게 사용하는지 살짝 체험 해보고자 한다.
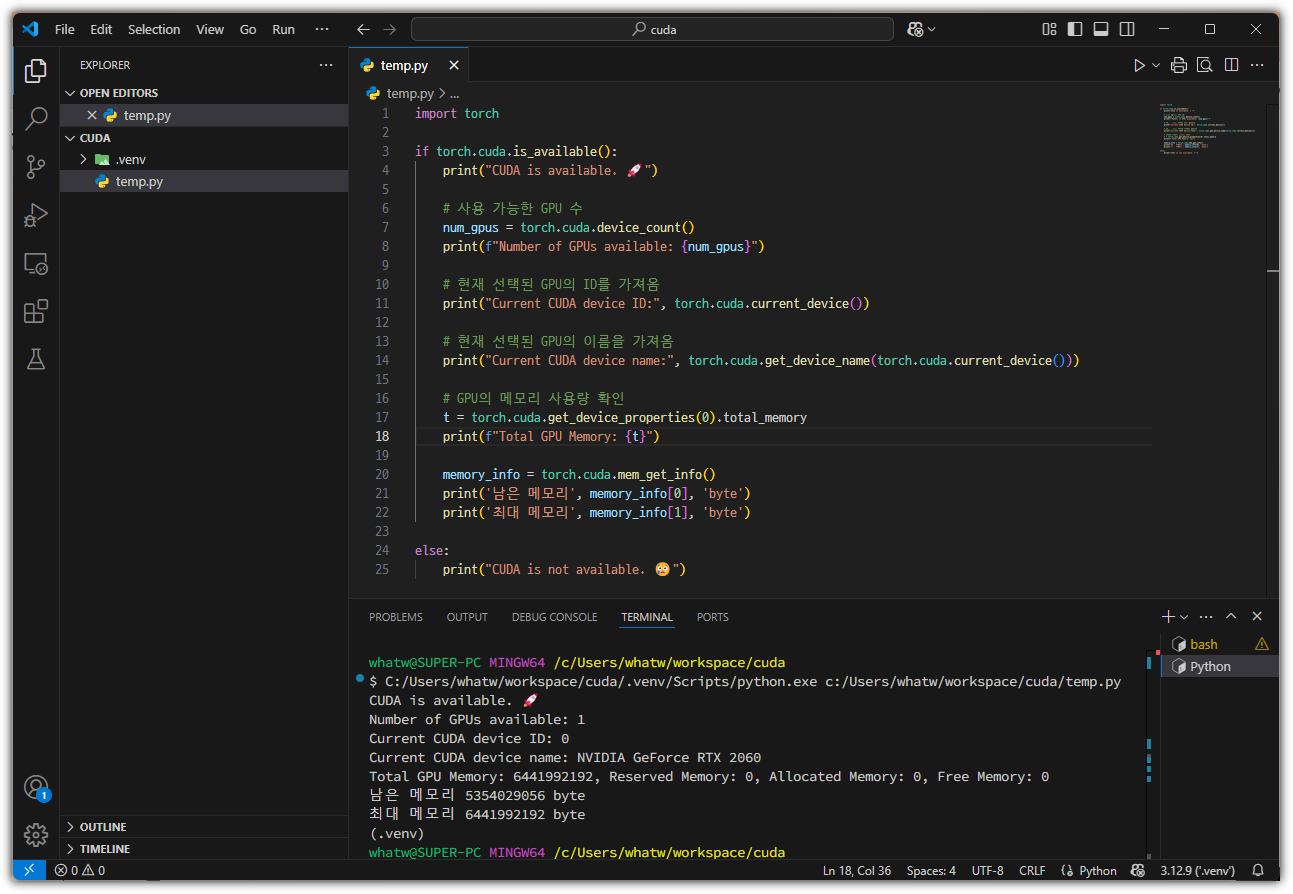
VSCode(Visual Studio Code)에 GitHub Copilot까지는 등록된 환경에서 시작하겠다.
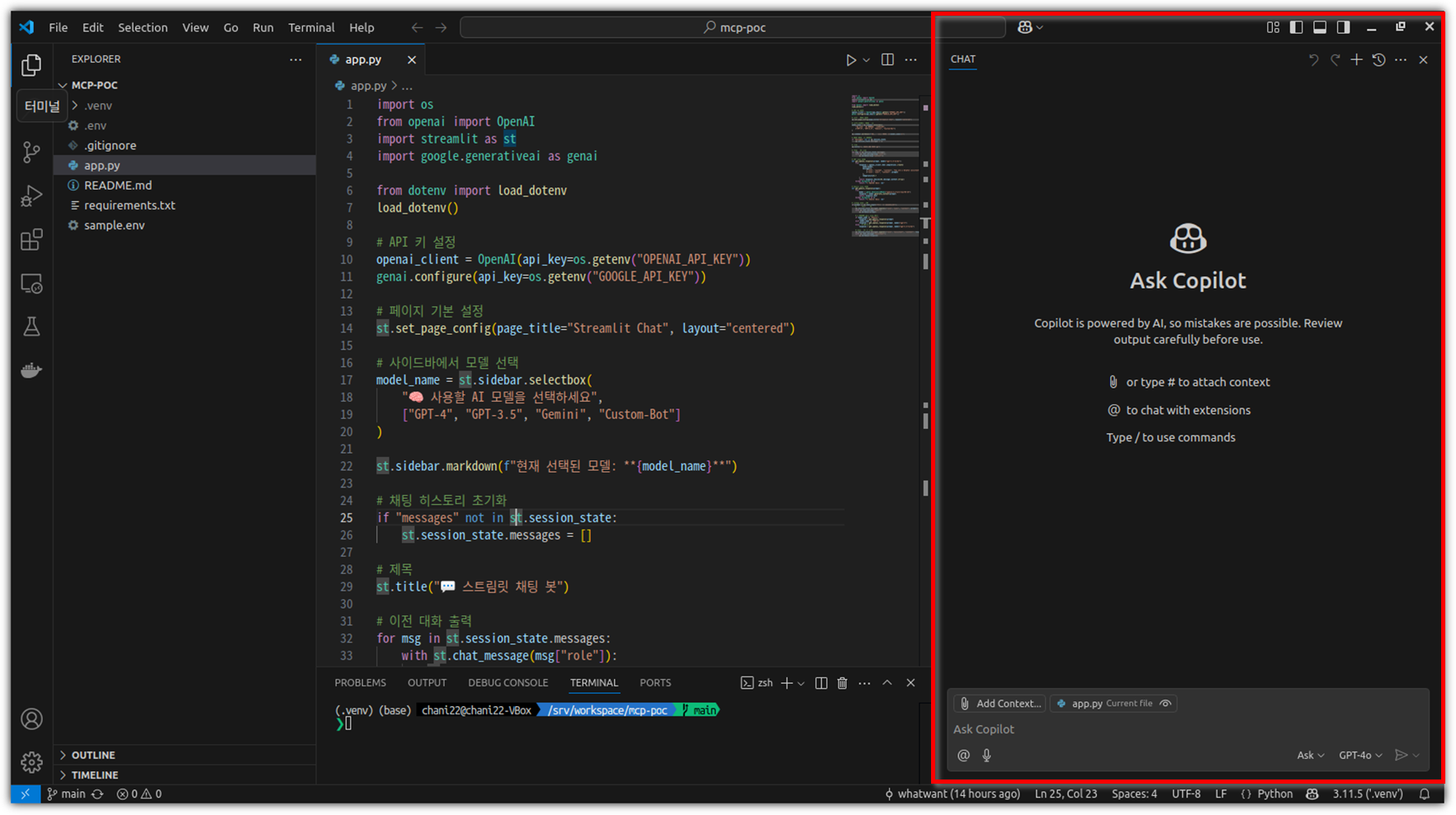
오른쪽 채팅창을 잘 살펴보면 3가지 모드를 선택할 수 있는 것을 알 수 있다.

Ask / Edit / Agent 3가지 모드가 있는데, 지금 우리가 관심있는 것은 Agent 모드이다.

사실 Edit 모드와 Agent 모드는 비슷 인터페이스를 보인다.
하지만, 왼쪽 밑을 보면 살짝 차이가 있는 부분을 발견할 수 있다.
Agent 모드에 대한 자세한 설명은 Visual Studio Code의 문서를 참고하면 된다. (GitHub Copilot 설명을?)
- https://code.visualstudio.com/docs/copilot/chat/chat-agent-mode
Agent 모드에서도 Edit 모드와 거의 동일하게 동작한다.

Agent 모드이기 때문에 채팅창을 벗어나 터미널 명령어들을 사용할 수도 있다.
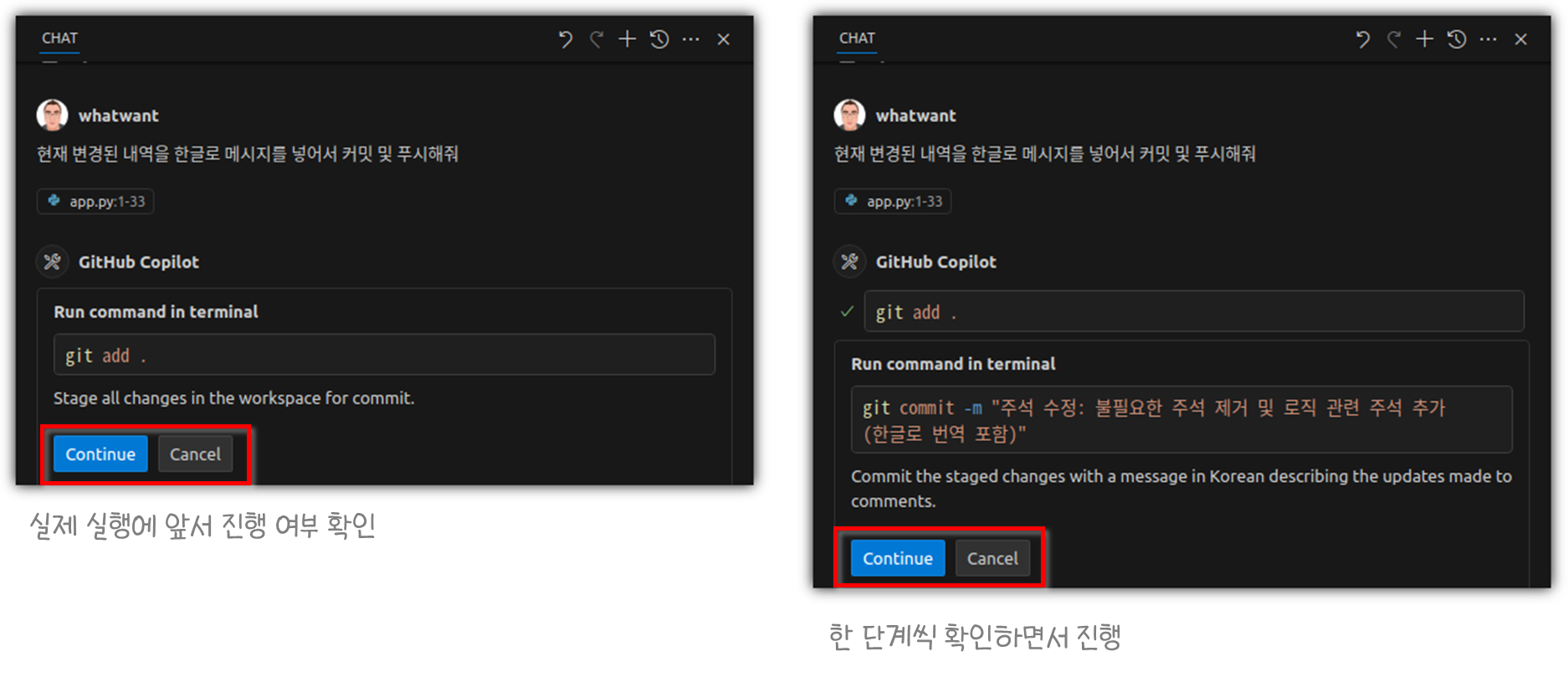
채팅창에서만 동작한 것이 아니라 실제로 'Copilot' 터미널이 열리면서 스스로 동작을 한 것이다.

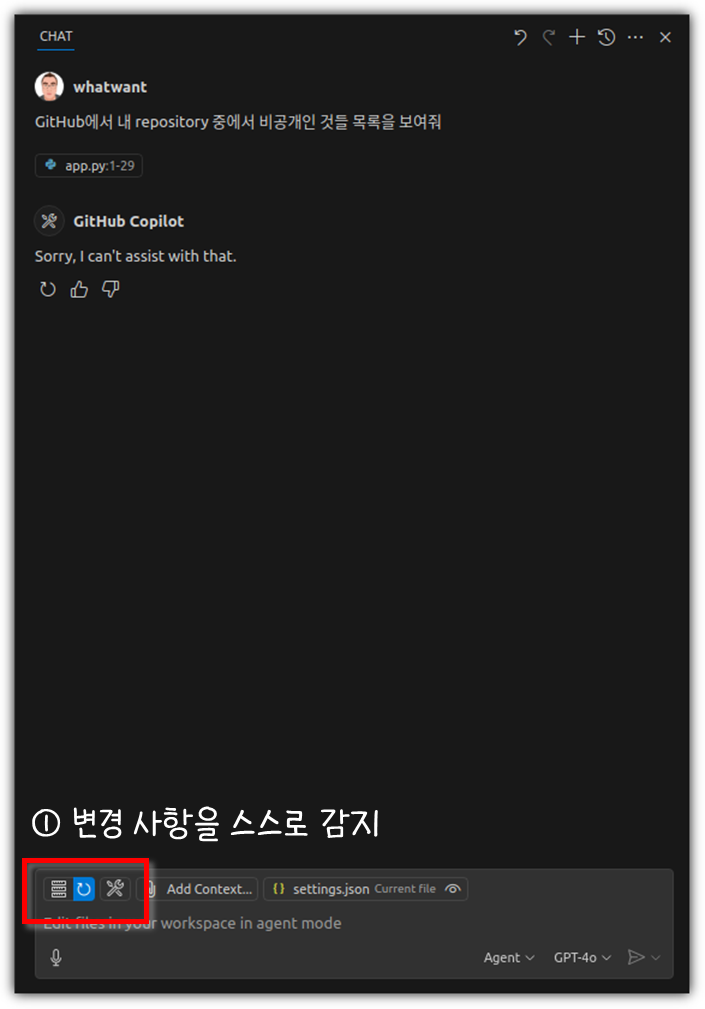
하지만, GitHub 관련한 동작을 시키면 못한다. (당연한 이야기!?)
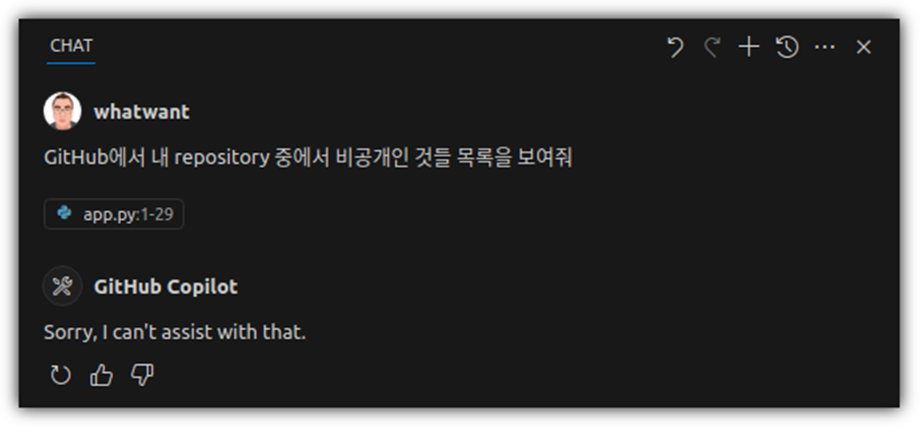
GitHub 관련된 일도 시킬 수 있으면 좋을텐데....
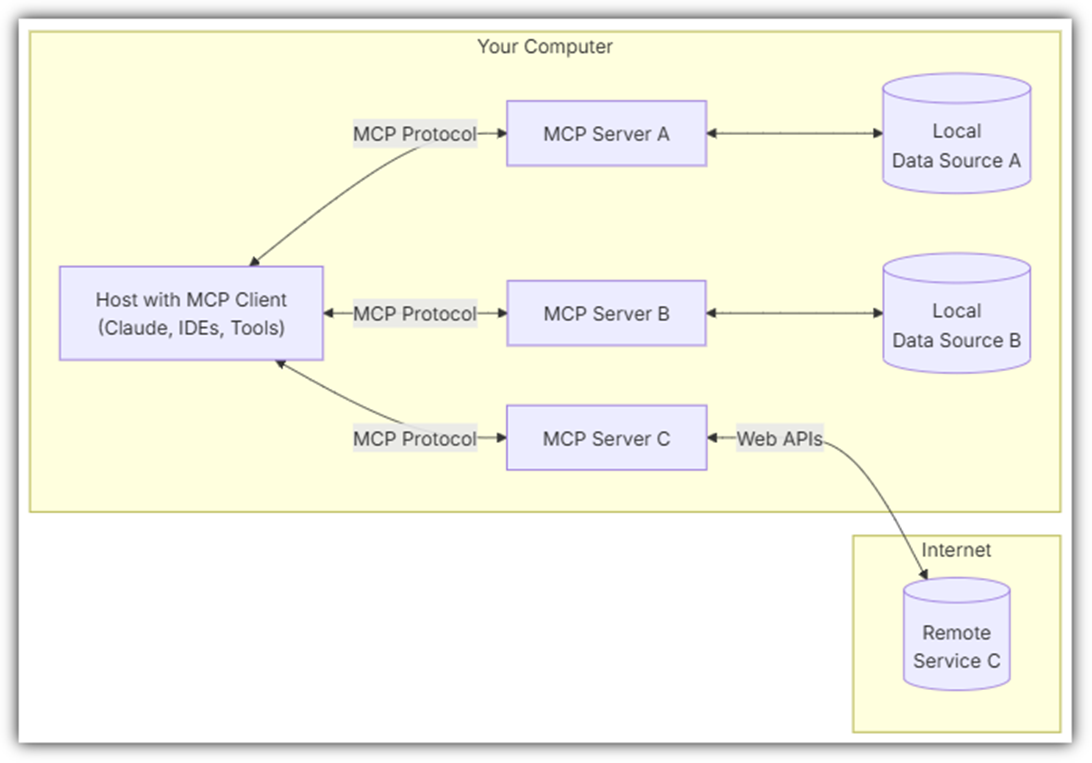
이럴 때 필요한 것이 MCP Server 이다 !!!
GitHub에서 공식으로 공개한 GitHub MCP Server를 찾아보자.
- https://github.com/github/github-mcp-server

사전에 준비해야할 사항들이 보인다.
Docker를 사용할 수 있는 환경이어야 하는데, 이미 설치되어 있다 ^^

GitHub Personal Access Token도 있어야 한다니,
GitHub에 접속해서 내 token을 미리 생성하고 복사해 두자.

이제 GitHub MCP Server를 설치하면 되는데,
GitHub 페이지에서 보이는 Badge를 클릭하면 바로 설치가 되기는 하지만... 직접 설치해보자.
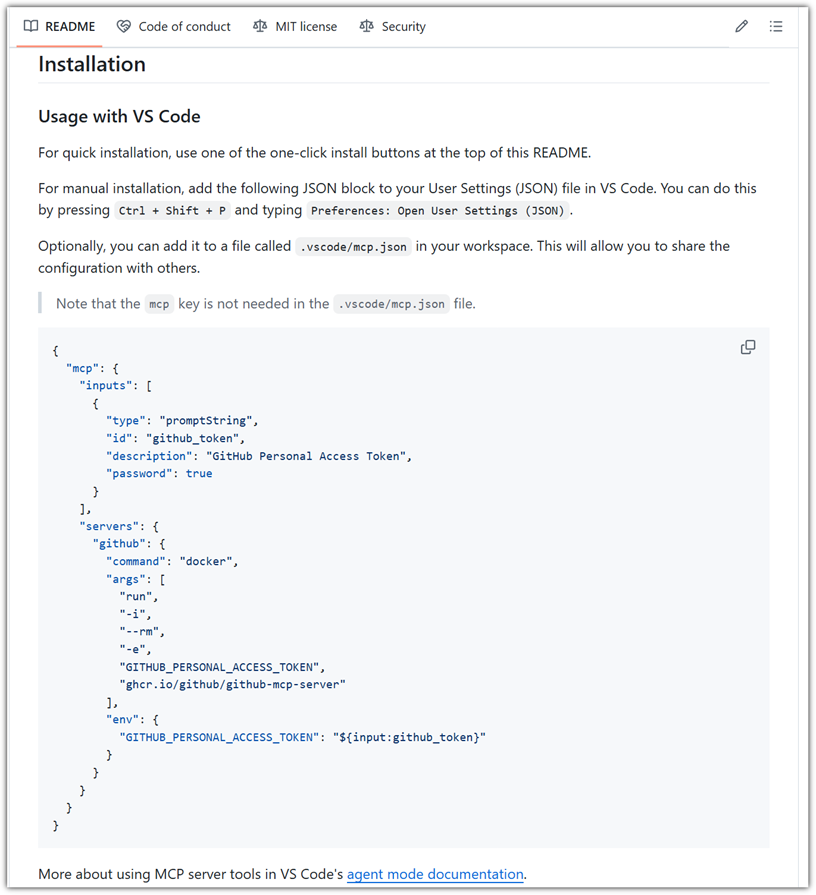
설치 방법을 잘 살펴보자.
- https://github.com/github/github-mcp-server?tab=readme-ov-file#installation
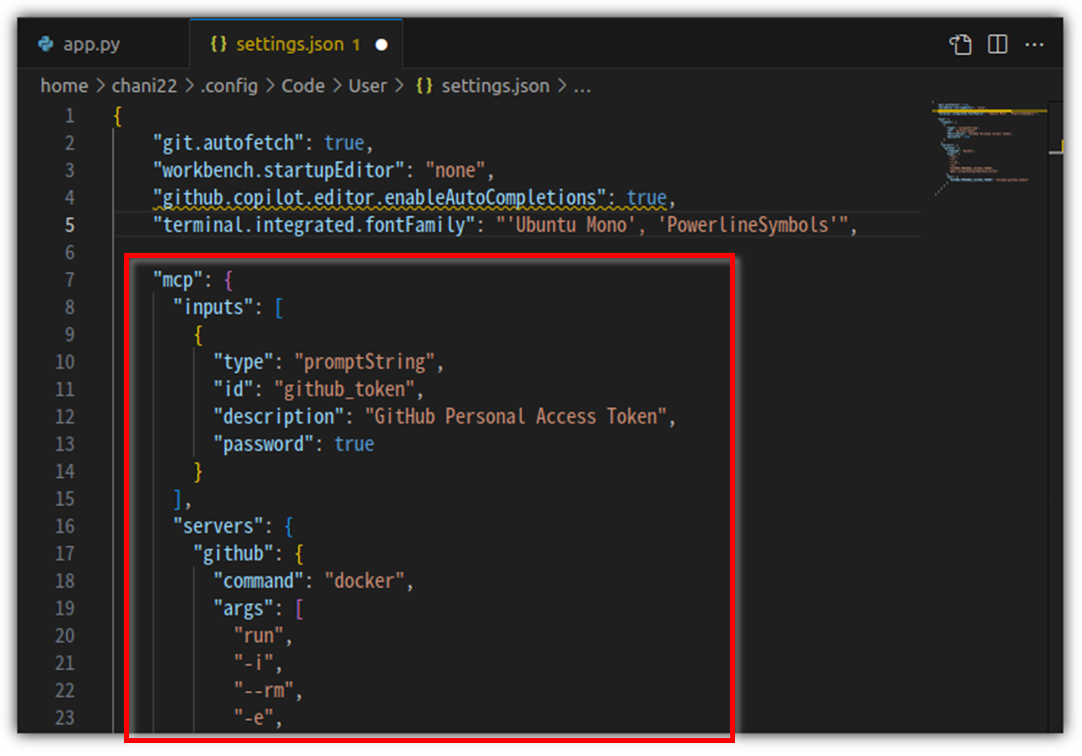
VSCode에서 "Ctrl + Shift + P" 단축키를 눌러서 나오는 화면에서
"Preferences: Open User Settings (JSON)"를 선택하자.

편집탭에 "settings.json" 파일이 열려있을텐데,
GitHub Installation 부분에 나와있는 json 내역을 추가해주면 된다. (기존 내용이 있으면 그 안에 덧붙이기)
그리고 저장을 하면 Copilot 채팅창의 왼쪽 밑에 뭔가 변화가 보일 것이다.
그리고 Personal Access Token 값을 넣으라는 창이 나타날 것이다.

미리 복사해둔 내용을 붙여넣기 하고 엔터를 치면 된다.
그러면, 도구 정보를 잘 읽어온 것을 볼 수 있을 것이다.
무려 30개의 도구를 읽어온 것이 보일텐데, 어떤 도구들이 있는지 궁금하면 클릭해보면 된다.
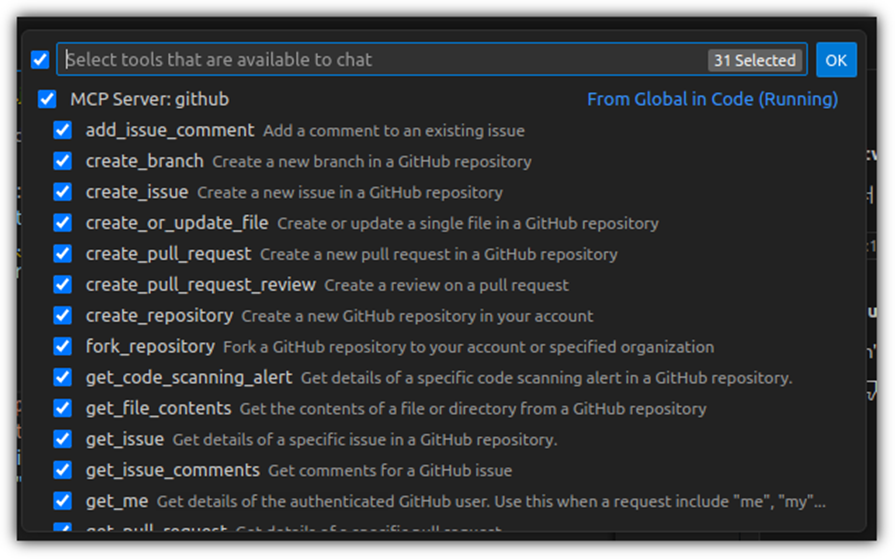
그러면 이제 GitHub MCP Server를 활용하는 사례를 진행해보자.

github.com의 내 정보를 알려달라고 했더니, "get_me"라는 도구를 찾아서 사용해도 되는지를 묻는다.

이슈 정보를 불러오게 할 수도 있다.

MCP Server는 어디에 있는 것일까?

내 local pc에 docker가 하나 돌고 있는 것을 확인할 수 있다.
뭔가 기분 나쁨?!
나중에 이거 뒤처리 내가 해야할 것 같은데!?
'AI_ML' 카테고리의 다른 글
| MCP (Model Context Protocol) Overview (0) | 2025.04.14 |
|---|---|
| 주피터 노트북의 여러 도우미 (Jupyter Notebook's Helper) (0) | 2024.02.12 |
| Copilot 말고 GPT Pilot 으로 코딩해보자. (2) | 2023.11.11 |
| Kubeflow 설치 (in Kubernetes) (0) | 2023.08.23 |
| 건방진 GPT를 아시나요? - BratGPT (0) | 2023.07.16 |