Pandas가 너무 유명하다보니
수 많은 alternative 라이브러리들이 쏟아지고 있으며 특히, 속도를 개선한 유형이 많다.
그러다가 Pandas 보다 100배 더 빠르다는 불오리를 발견하게 되었다.
- https://hwisnu.bearblog.dev/fireducks-pandas-but-100x-faster

응?! FireDocks가 대체 뭔데, 이런 성능을 보여준다는거지?!
- https://fireducks-dev.github.io/

성능이 너무 잘 나와서인지 최근 엄청난 뉴스들이 쏟아지고 있다.
성능도 성능이지만, 기존에 Pandas로 작성한 코드를 그대로 사용할 수 있다는 점도 또 하나의 매력이다.
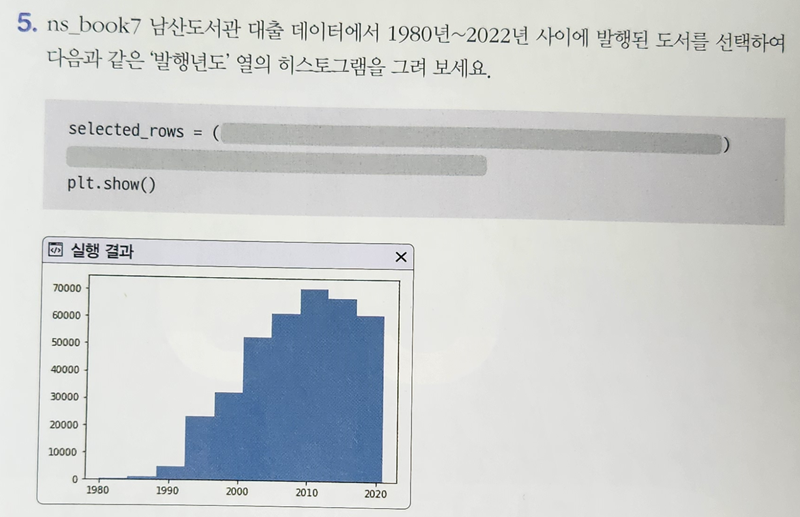
실제 측정한 성능은 어떻게 될까?
- https://fireducks-dev.github.io/docs/benchmarks/

자기들이 측정한 것이라 믿지 못할 수도 있겠지만,
실험한 환경 및 코드를 모두 공개하고 있으니 거짓말은 아닐 것이다 ^^
직접 코드를 한 번 돌려봤다.
테스트 환경은 Google Colab을 사용했다.
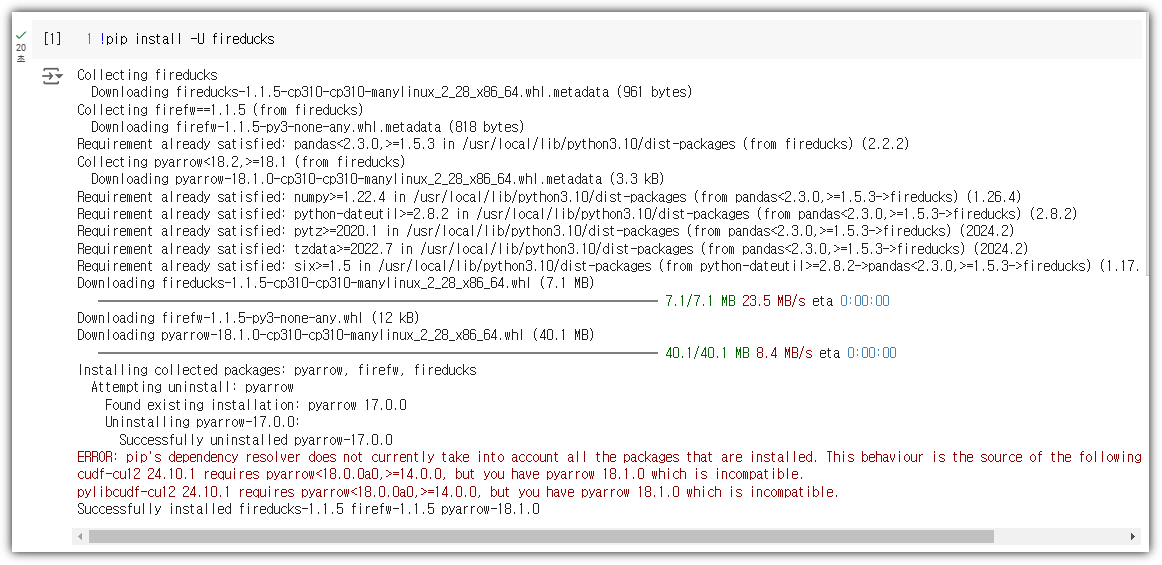
현재 최신 버전은 v1.1.5 이다.
테스트를 하기 위한 데이터를 생성하고,
실제 groupby 및 mean 실행을 통해 연산을 하는 소요 시간 측정 코드를 작성했다.

Pandas로 실행을 했을 때엔 3초의 시간이 소요되었는데,
FireDucks는 눈 깜짝 할 사이에 실행이 되어버리는 것을 볼 수 있다.

라이브러리 호출 부분만 변경했을 뿐인데, 성능이 좋아진다면 사용하지 않을 이유가 없을 것 같다.
라이선스는 "the 3-Clause BSD License (the Modified BSD License)"이다.
- https://github.com/fireducks-dev/fireducks
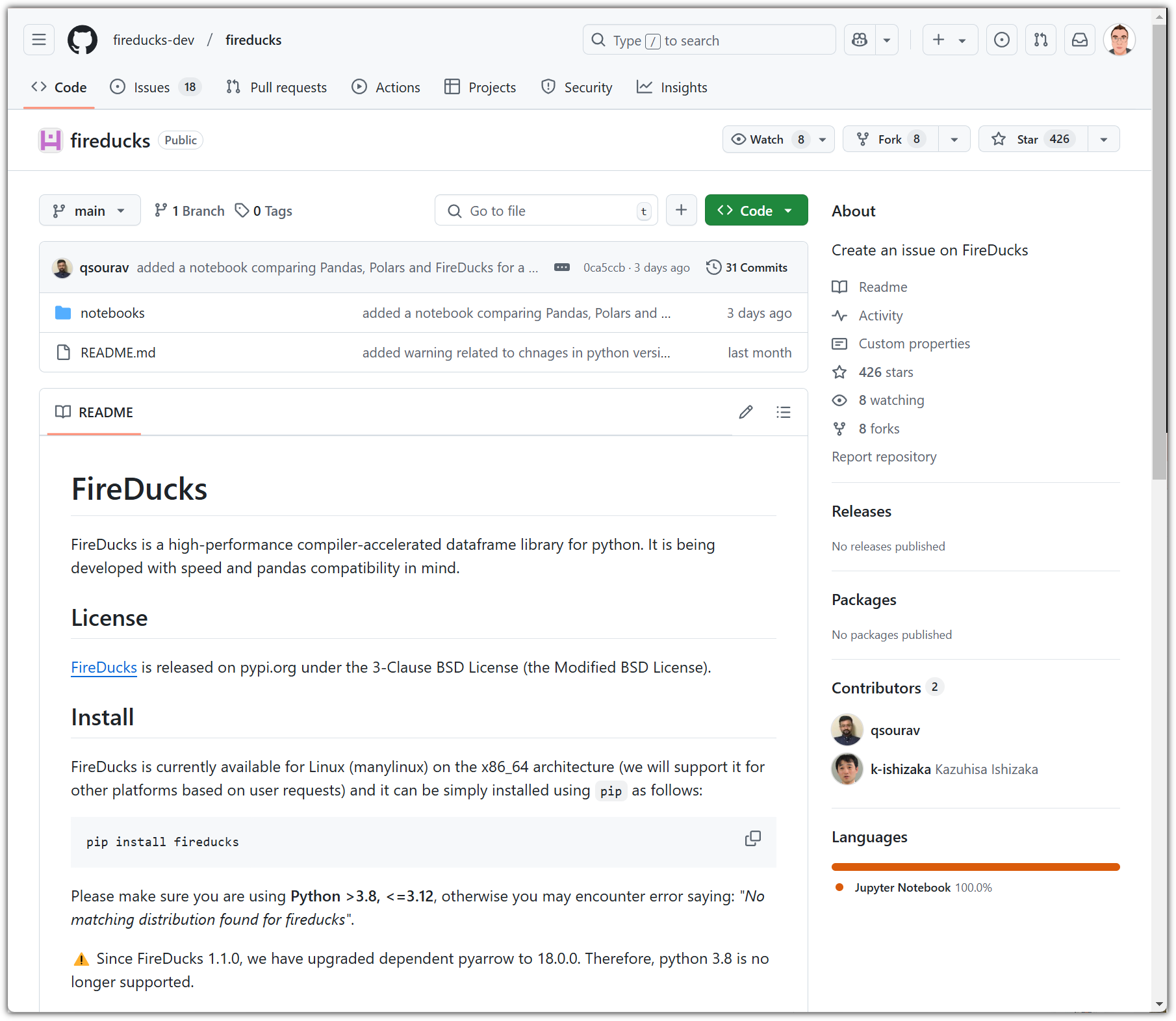
이렇게 훌륭한 라이브러리를 누가 만들었을까!?
- https://www.nec.com/en/press/202310/global_20231019_01.html
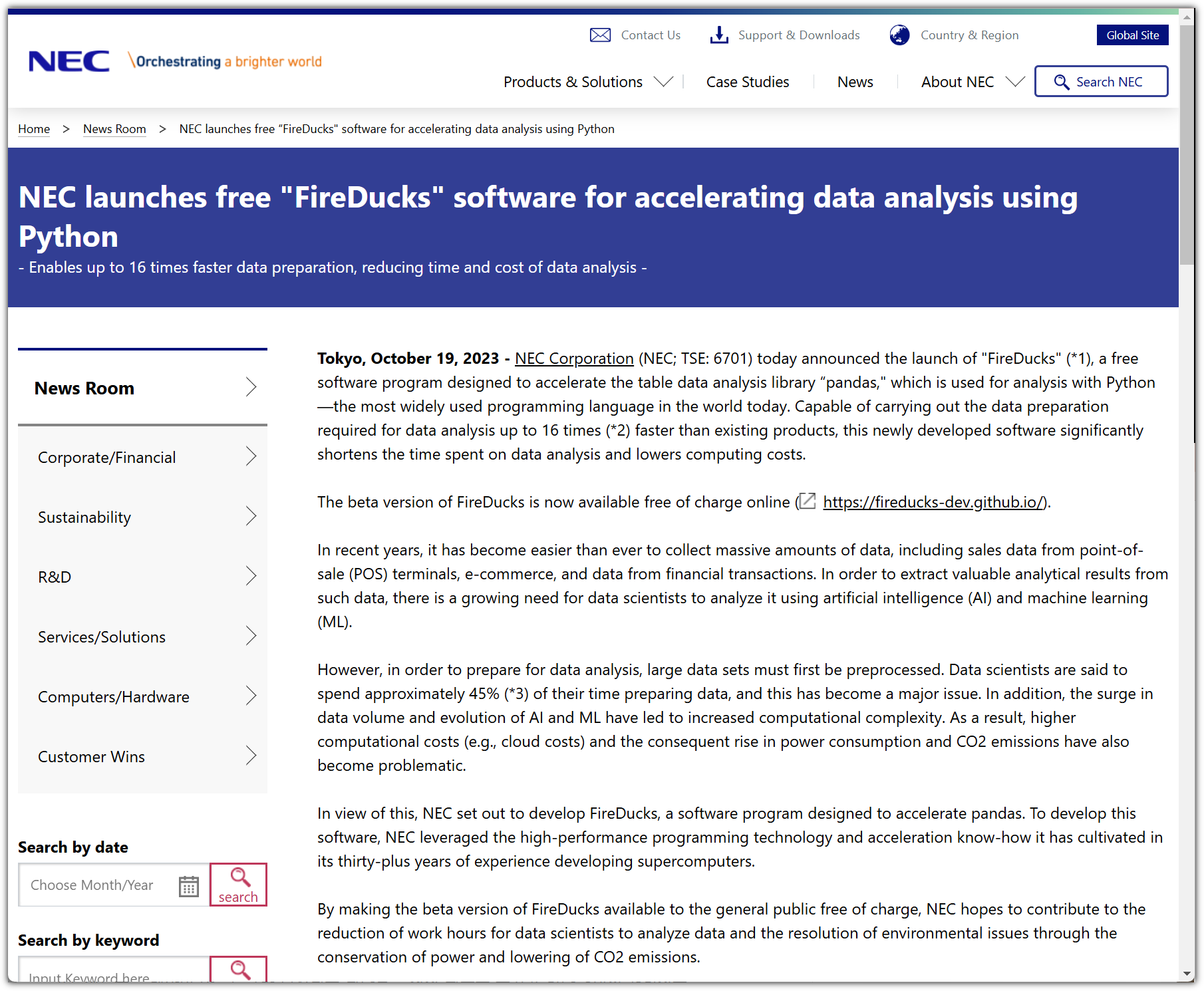
응?! 여기에서 갑자기 NEC ?!
어쩐지 공식 홈페이지에서 지원하는 언어가 English 외에 Japanese가 있더라니...
한 때는 가전제품도 생산을 해서 가끔 눈에 띄이곤 했는데,
요즘은 B2B 사업이나 통신 설비 등에 주력해서인지 주변에서 잘 보이진 않는다.
하지만, 11만명 이상의 임직원이 있는 글로벌한 기업이다.
AI 및 클라우드 사업도 한다고 하던데,
이런 훌륭한 라이브러리도 만들어서 공개하고.... 괜찮은데!?
'Programming > Python' 카테고리의 다른 글
| 응 아저씨와 함께하는 파이썬 공부 (AI Python for Beginners) (1) | 2024.12.29 |
|---|---|
| NAVER API를 이용해서 블로그 검색하기 (with Python) (0) | 2024.11.23 |
| 문서 파일을 데이터로 만들어주는 Docling (0) | 2024.11.18 |
| FastHTML - 파이썬으로 웹앱 만들기 (0) | 2024.09.23 |
| 날씨 정보 API 활용하기 (Python) (0) | 2024.08.11 |