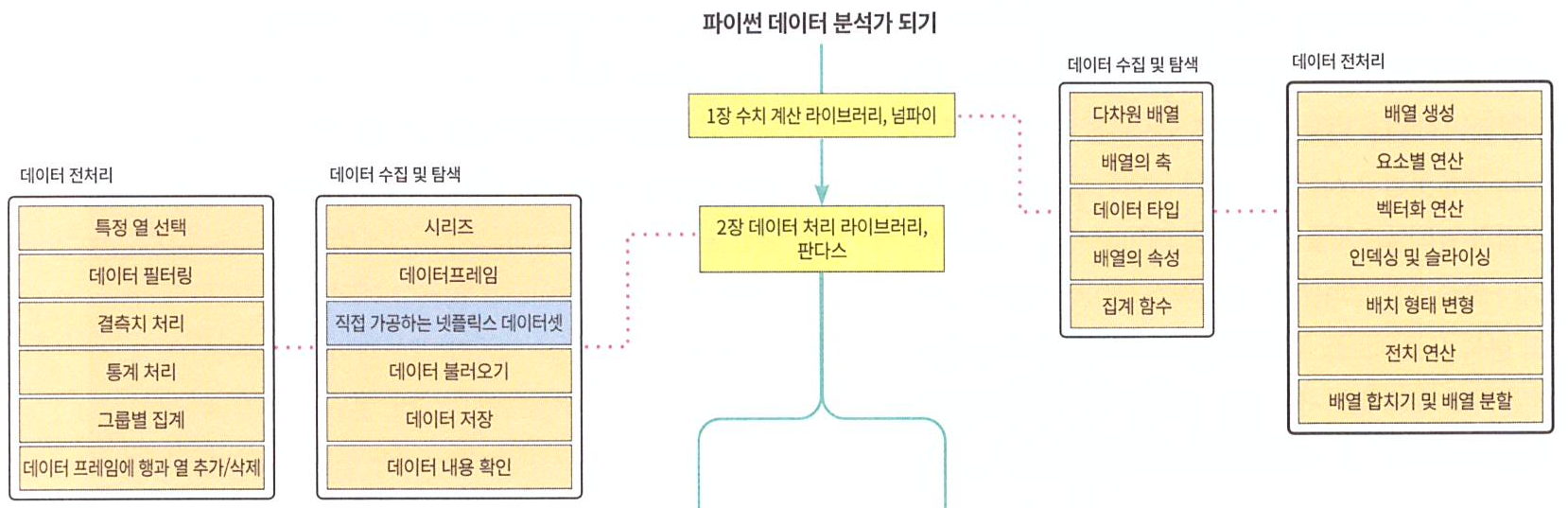
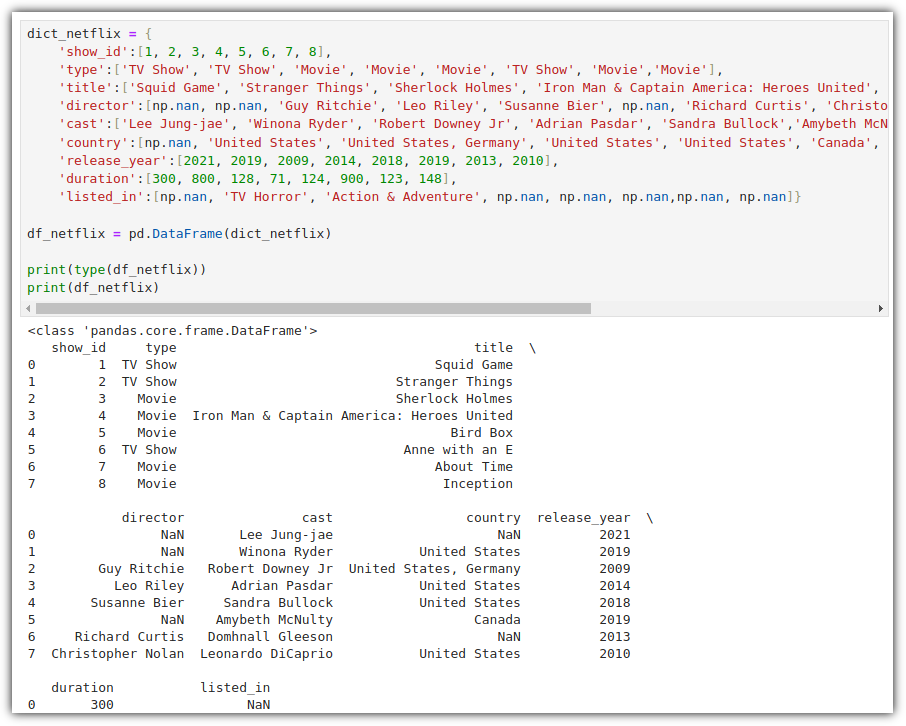
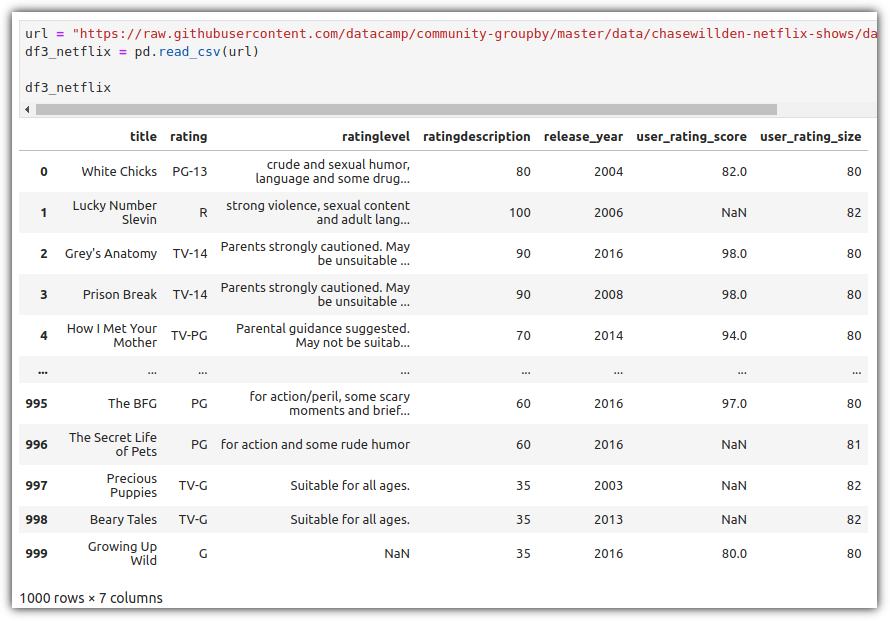
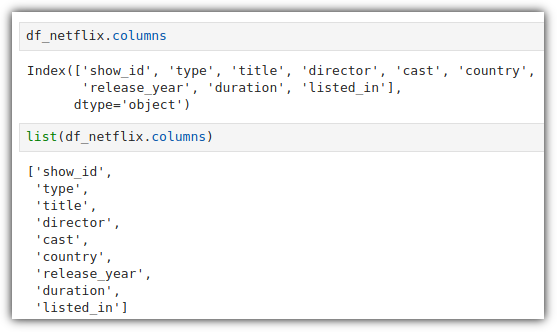
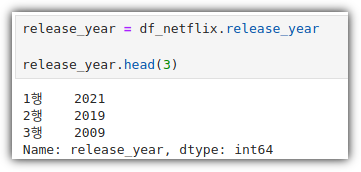
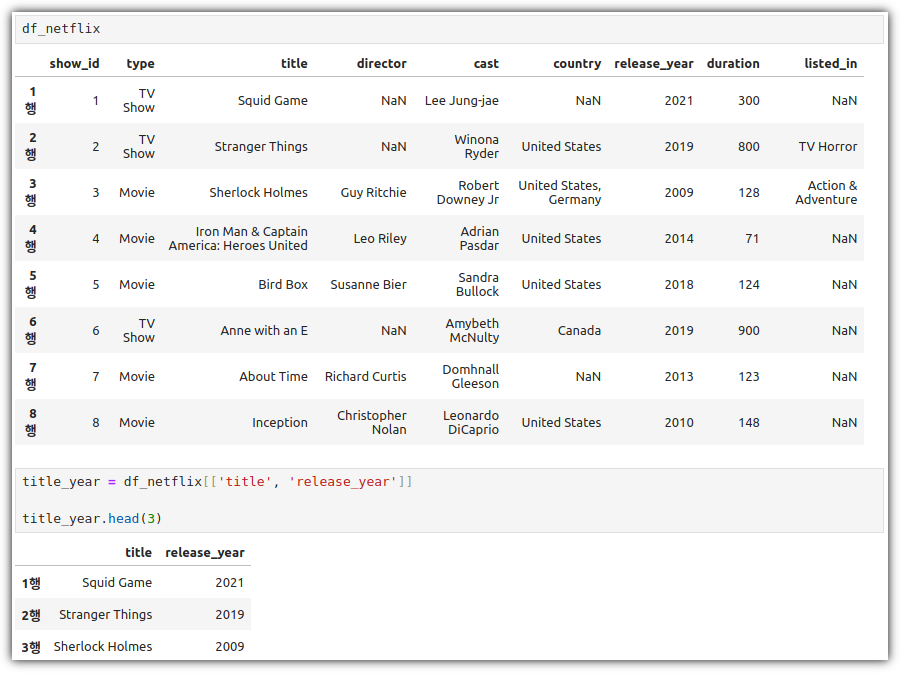
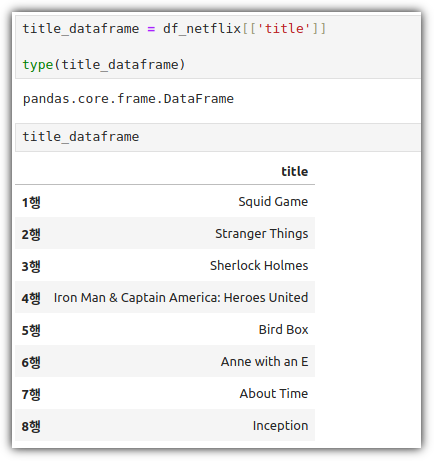
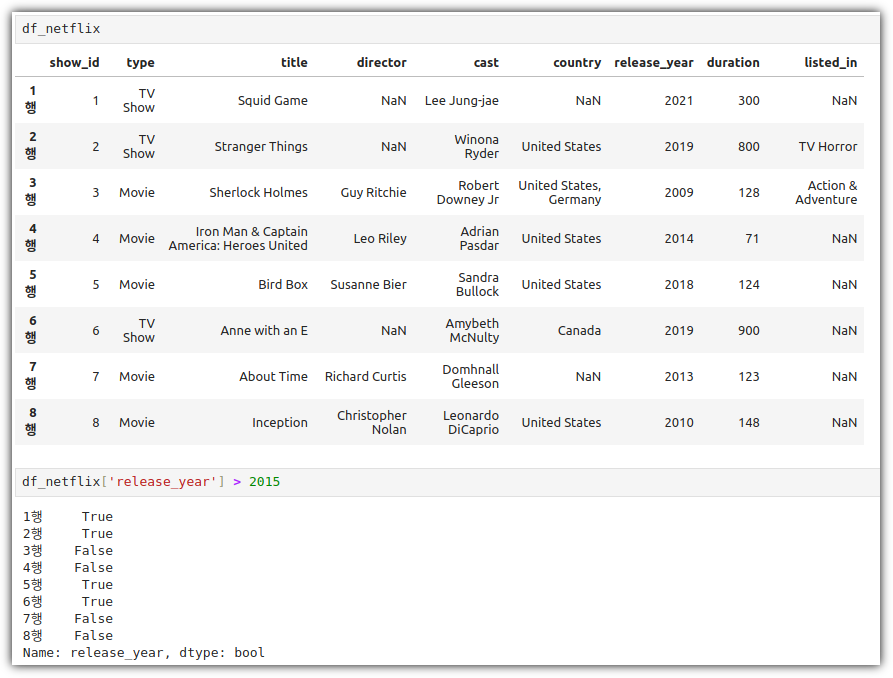
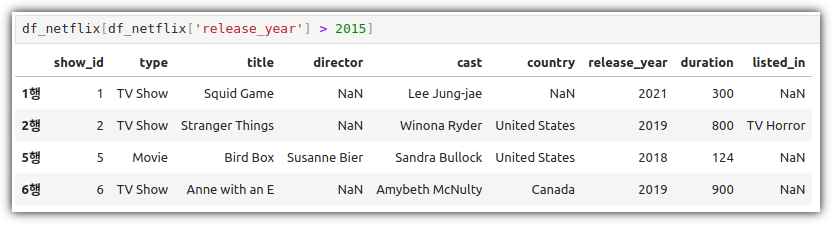
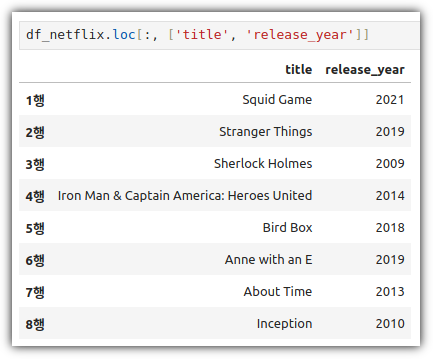
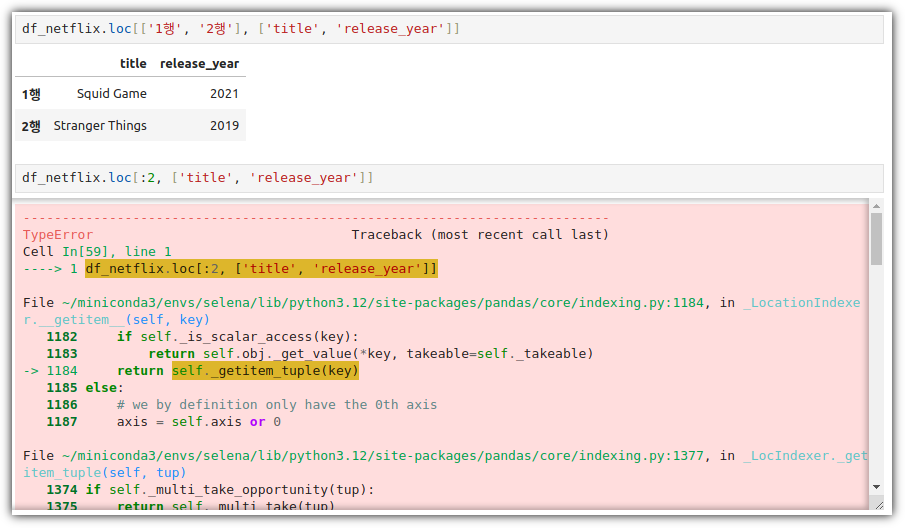
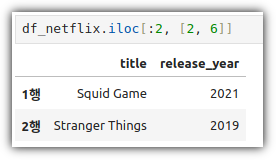
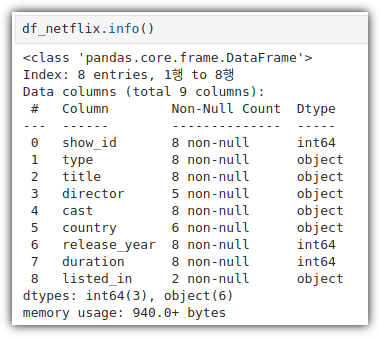
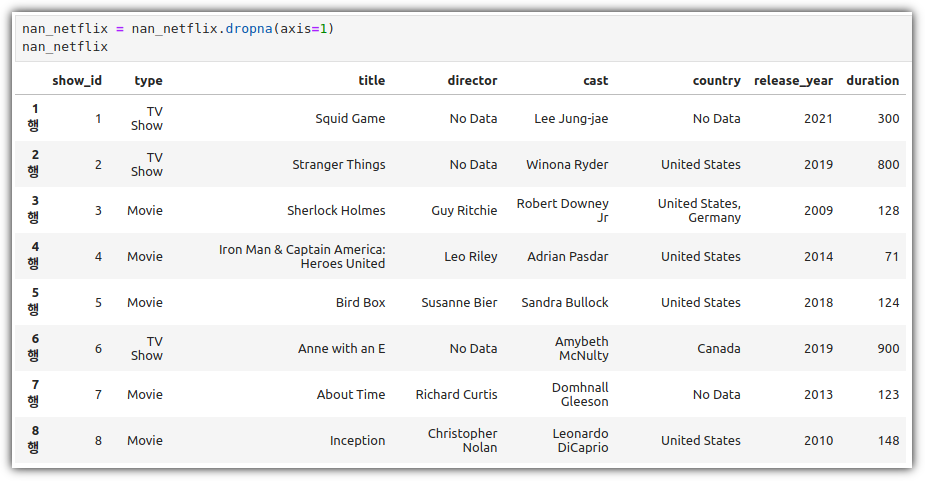
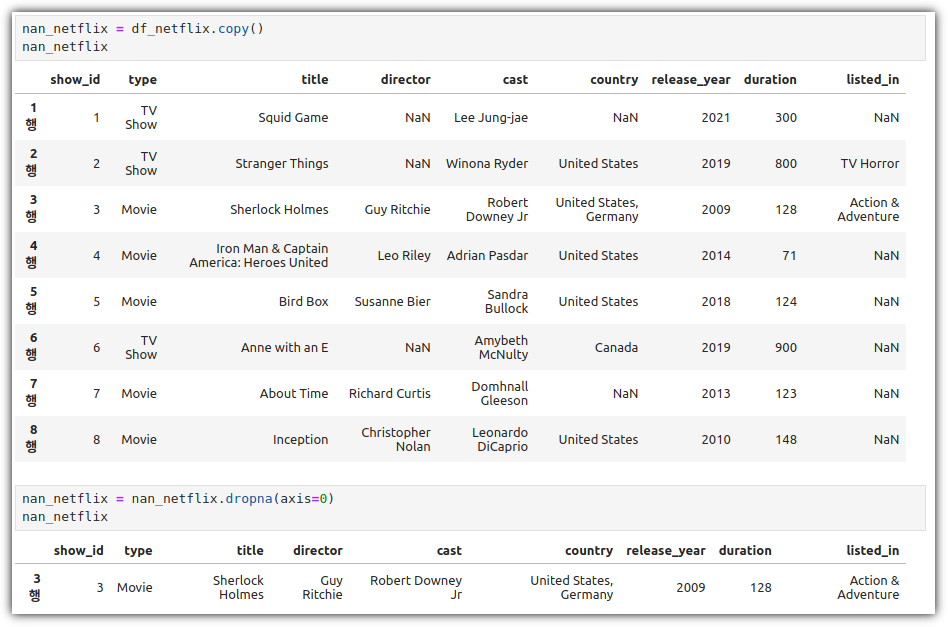
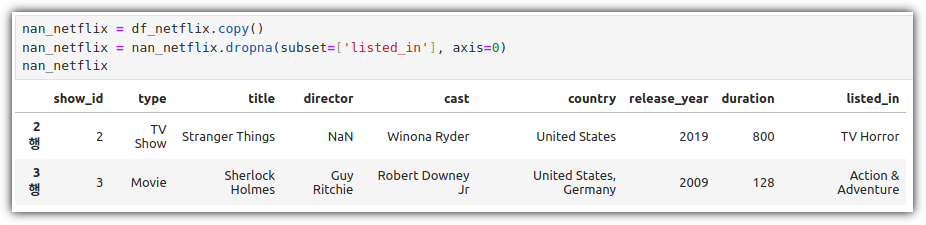
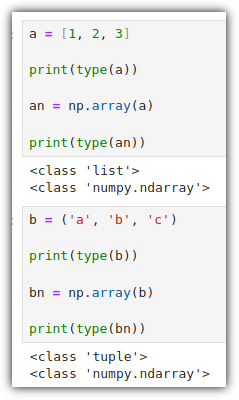
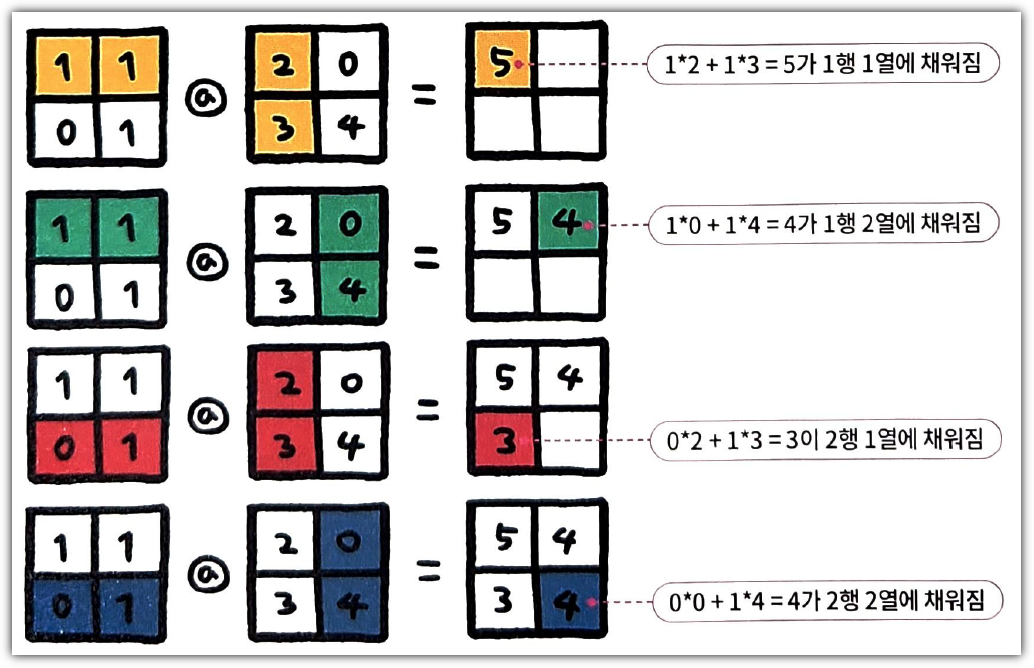
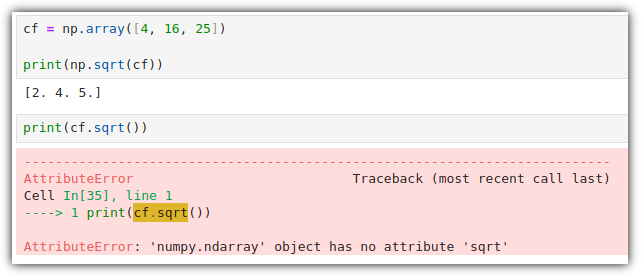
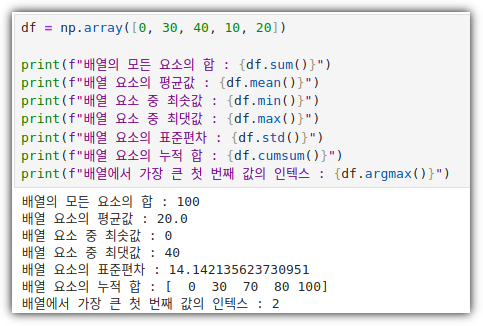
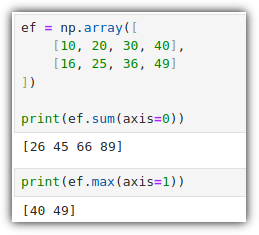
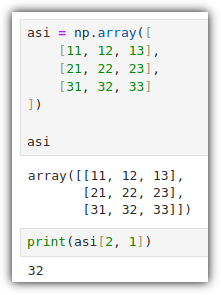
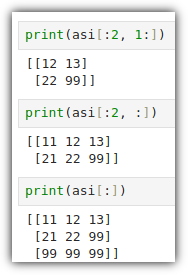
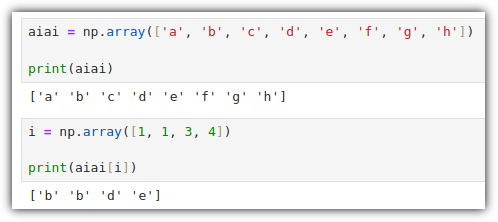
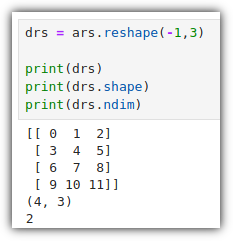
ML / DS 공부를 시작하게 되면 누구나 겪는(?) 자연스러운 스터디 순서,
- Numpy → Pandas → Matplotlib

솔직히 전형적인 코더(키보드 워리어) 생활을 하던 사람으로써
이런 Visualization 영역에 대해서는 왠지 모를 거부감가 함께 두려움(?)이 있다.
하지만, 해야하는 것이니 해야겠지만.... 😥
지금까지의 공부과정은 다음과 같다.
- [파이썬 데이터 분석가 되기] 02 - Pandas
오늘 공부할 것은 다음과 같다.
03장. 데이터 시각화 라이브러리, 맷플롯립
① Matplotlib 시작하기
② 그래프 꾸미기
③ 다양한 그래프 그려보기 ⑴
④ 다양한 그래프 그려보기 ⑵
⑤ 그래프 한꺼번에 그려보기
⑥ 그래프 저장하기
① Matplotlib 시작하기
Matplotlib은 이름 그대로 파이썬 환경에서 데이터 시각화를 위한 라이브러리이다.

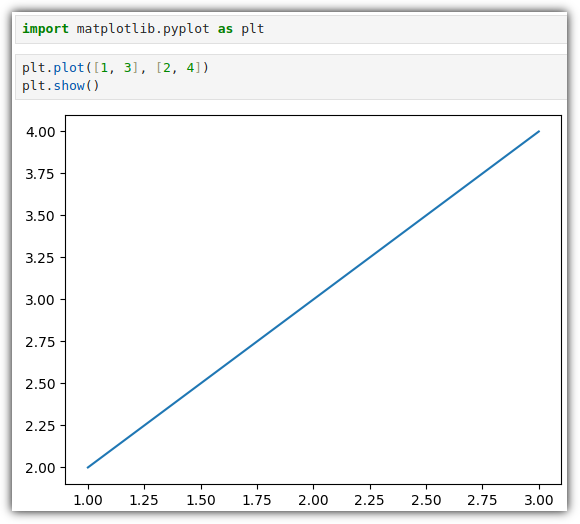
▷ 일단 한 번 그려보기
- plt.plot()으로 그래프를 그린다고 해서 바로 출력되지 않는다.
- plt.show()를 실행하면 앞에서 그린 그래프를 그려준다.
- [1, 3], [2, 4] 데이터가 어떻게 그래프에 그려졌는지 잘 살펴보기 바란다.
. [1, 3] 데이터는 X축의 좌표이고, [2, 4] 는 Y출의 좌표이다.
. (1, 2), (3, 4) 데이터가 출력된 것이다.
. plt.plot(x, y) 구성이므로, x 부분에 [ ] 형식으로 들어간 것이라고 생각하면 될 것 같다.
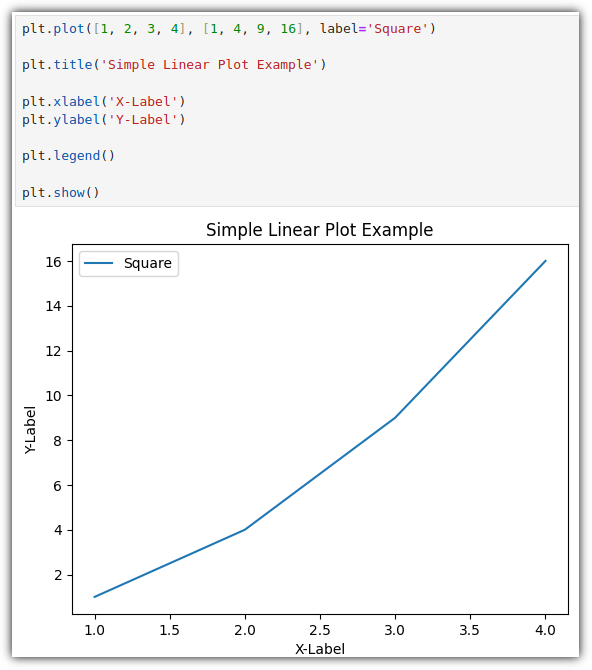
② 그래프 꾸미기
▷ 축 레이블 (label) / 범례 (legend) / 제목 (title) - 기본1
간단하게 표시하는 것을 우선 살펴보겠다.
▷ 축 레이블 (label) / 범례 (legend) / 제목 (title) - 기본2
그래프 실습을 위해 데이터들을 샘플로 생성해보자.
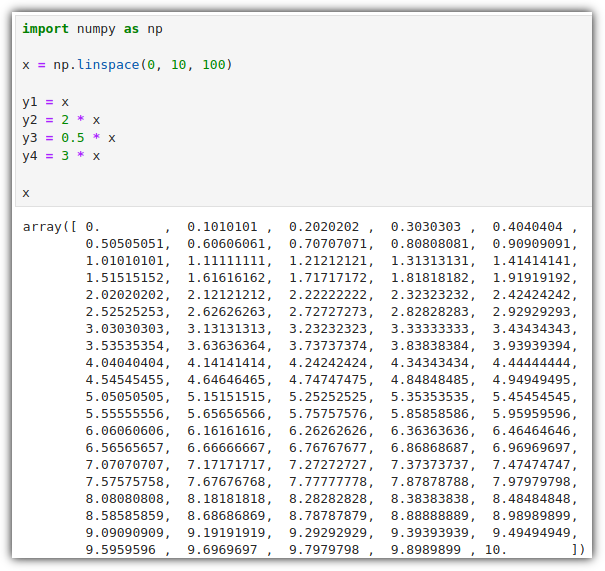
np.linspace(start, stop, num) : Linearly Spaced
- num 값은 생성할 값의 개수를 의미한다.
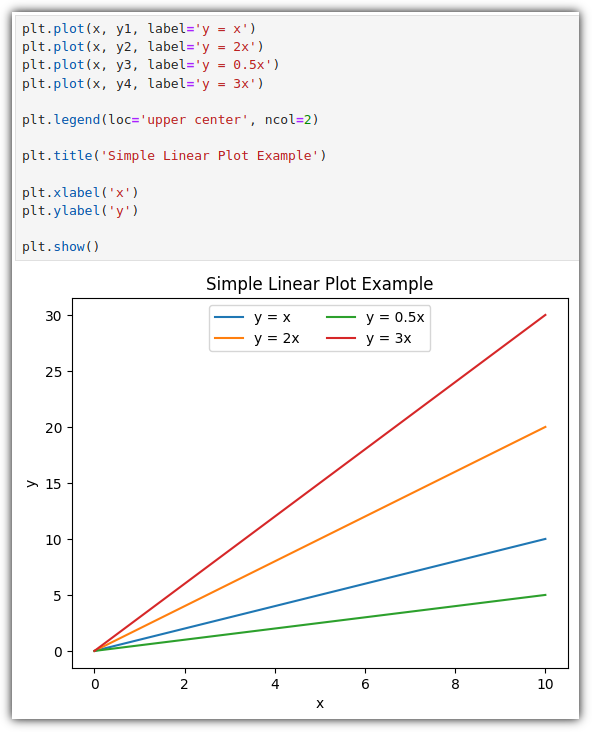
plt.show() 하기 전에는 그래프에 표현하고 싶은 것들을 계속 적어주면 된다.
plt.legend(loc=location, ncol=number of column)
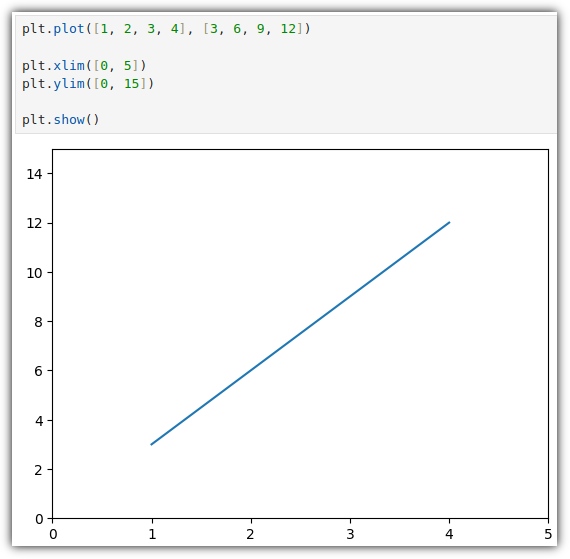
▷ 축 범위 (limit)
일단 기본적으로 축 범위는 입력 데이터를 기준으로 자동 설정이 된다.
plt.xlim() / plt.ylim() 을 통해서 표현할 축 범위를 강제할 수 있다.
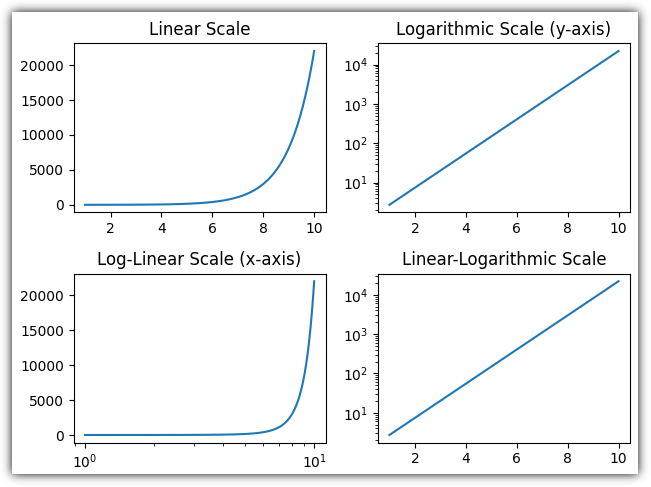
▷ 축 스케일 (scale)
⒜ 선형 스케일 (linear scale)
- 일반적으로 사용되는 스케일
- 값이 일정 간격으로 증가/감소 하는 경우
⒝ 로그 스케일 (logarithmic scale)
- 값의 크기 차이가 큰 경우
- 지수적으로 증가하는 데이터나 큰 범위의 데이터
⒞ 로그-선형 스케일 (log-linear scale)
- x축을 로그 스케일, y축을 선형 스케일
- x축이 시간 또는 크기인 경우 사용
⒟ 선형-로그 스케일(linear-logarithmic scale)
- x축을 선형 스케일, y축을 로그 스케일
- y축의 값 범위가 큰 경우, 대부분 작은 값 범위이고 일부 값이 매우 큰 경우
데이터를 먼저 준비하자. Exponential
여러 그래프를 묶어서 표시할 때 사용할 수 있는 것이 바로 plt.subplot()이다.
서브 그래프의 간격을 좁게 조절하기 위해서는 plt.tight_layout()을 사용할 수 있다.

실행 결과는 다음과 같다.
▷ 선 종류 (linestyle)
선 종류도 다양하게 할 수 있다.
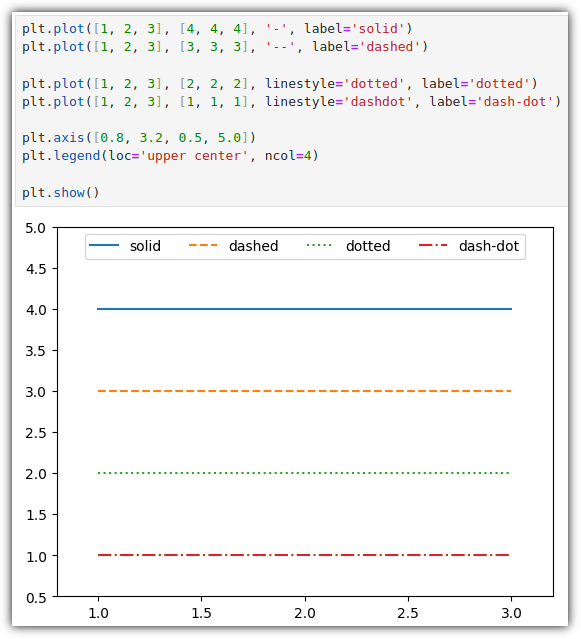
▷ 마커 (marker)
그래프의 선 색깔을 정해줄 수도 있고,
값을 표시하는 marker도 다양하게 정해줄 수 있다.

참고로
교재에서는 plt.plot([3, 4, 5], "ro")로 제시했지만 그렇게 하면 선(line)은 표시가 안된다.
본래 "색깔-선-마커"의 순서대로 모두 정해줘야 하는데, 선 부분을 생략해서 나오지 않는 것이다.
값 위치를 표현할 여러 표식들은 다음 링크를 통해 확인할 수 있다.
- https://matplotlib.org/stable/api/markers_api.html
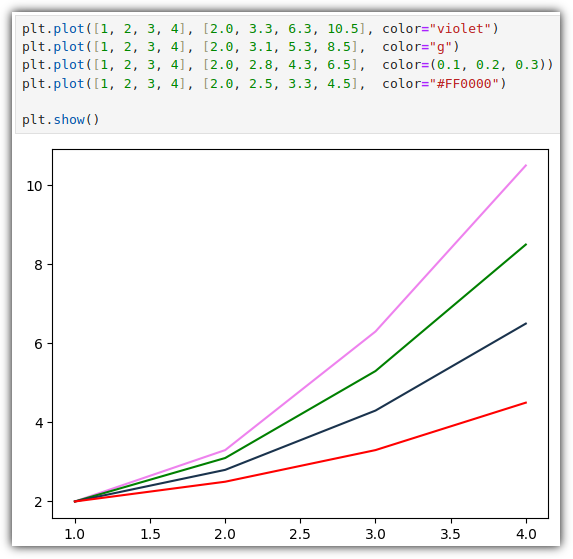
▷ 선 색 (color)
선의 색상을 설정하는 방법도 여러가지로 제공해준다.
⑴ 이름 (예: 'violet')
⑵ 약자 (예: 'g')
⑶ RGB (예: (0.1, 0.2, 0.3))
⑷ 16진수 (예: '#FF0000')
색상으로 사용할 수 있는 값들은 다음 링크를 통해 확인할 수 있다.
- https://matplotlib.org/stable/gallery/color/named_colors.html
▷ 제목 (title)
결국은 문자열(string)이기 때문에, 이와 관련한 설정들을 제공해준다.
다른 설정들은 익숙할 수 있는데, 조금 특이한 옵션이 바로 pad 이다.
그래프와 제목 사이의 거리인데, 이걸 잘 조절하면 예쁜 배치를 할 수 있을 것이다.
▷ 대제목 (super-title)
여러 개의 그래프를 묶어서 출력하는 경우,
전체를 대표하는 제목을 추가로 붙여줄 수 있다.
▷ 눈금 (ticks)
plot() 형식이 아니라 bar() 형식이 새롭게 등장했지만, 찬찬히 살펴보면 어렵지 않을 것이다.
xticks(눈금이 표시될 좌표, 표시할 텍스트 레이블) 형식이다.
▷ 그리드 (grid)
격자 모양의 선도 예쁘게 표시할 수 있다.
★ Helper
그런데, 지금 계속 간단하게 이런 것이 있다라는 것만 집어주고,
세부 옵션들에 대해서는 너무 안 살펴봐서 당황할 수도 있다.
이러한 옵션은 직접 보면서 필요에 따라 공부하면 충분하다.
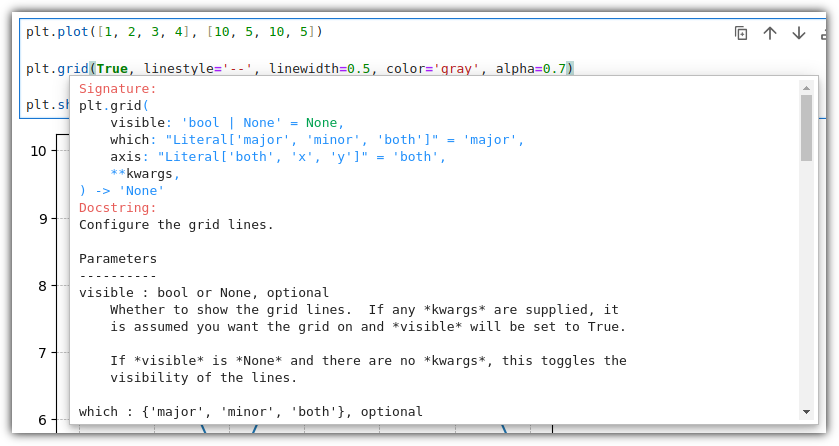
함수 이름을 타이핑하고 "Shift + Tab" 키를 눌러주면 친절한 Docstring을 확인할 수 있다.
▷ 텍스트 (text)
굳이 이 정도까지 해야하나?! 할 수도 있지만... 그래프의 원하는 곳에 텍스트를 찍어줄 수도 있다.
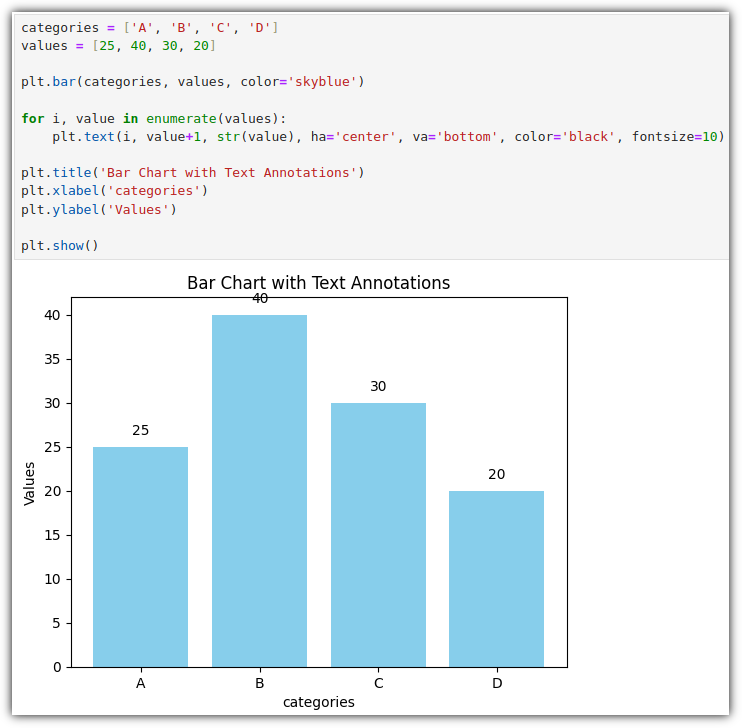
옵션 중에 ha / va 부분이 낯설 수 있는데,
horizontal axis / vertical axis 즉, 수평 / 수직 정렬을 위한 옵션이라고 생각하면 된다.
③ 다양한 그래프 그려보기 ⑴
▷ 타이타닉 데이터셋 (titanic dataset)
MachineLearning 특히 Kaggle 공부를 하게 되면
누구나 만나는 아주 친숙한 타이타닉 데이터셋~!!
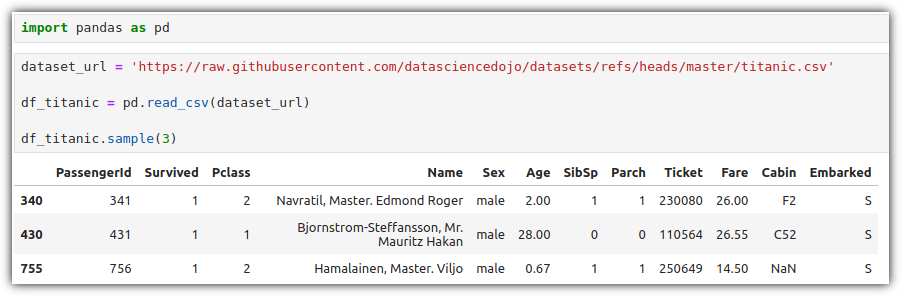
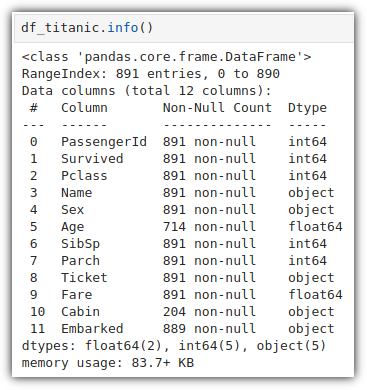
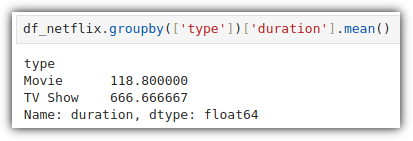
Pclass 기준으로 그룹화 해서 Survived 의 평균을 계산하고,
그룹화로 인해 제거된 기존 index를 대체해서 새롭게 index를 생성까지 해보자.
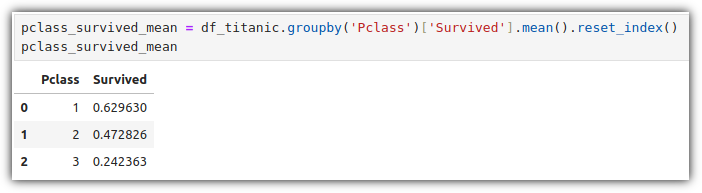
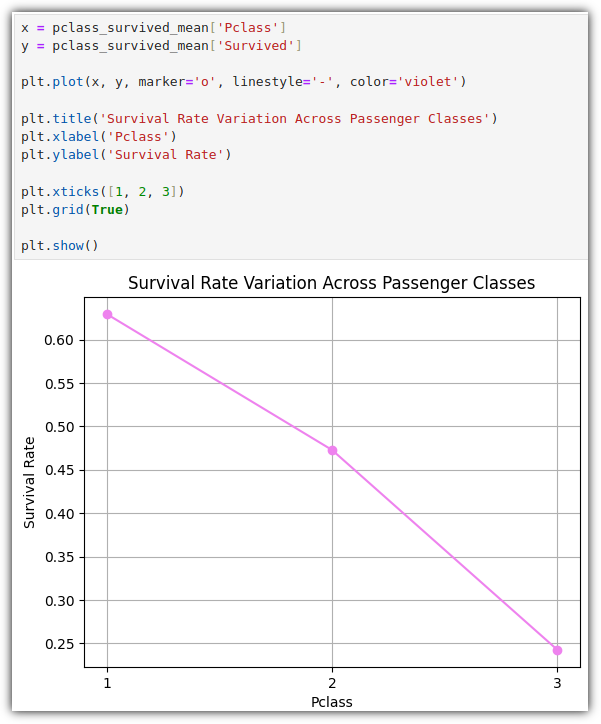
이 데이터들을 가지고 그래프를 그려보자.
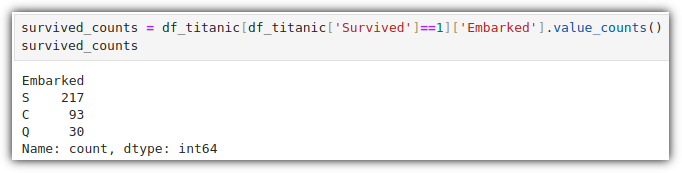
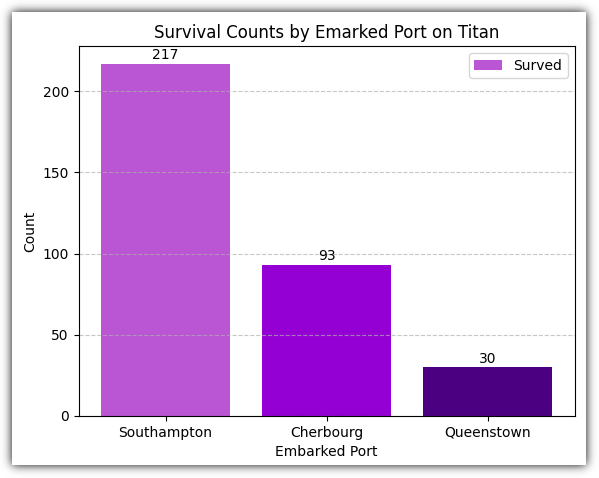
이번에는 생존자들이 어느 항구에서 승선을 했는지를 살펴보자
이런 저런 내역들을 포함해서 그래프를 그려보자.

비슷한 방식인데, 이번에는 성별을 기준으로 데이터를 정리해보자.
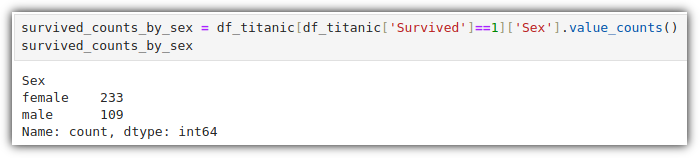
이번에는 수평 막대 그래프로 그려보자.

그려보면 다음과 같다.
▷ 산점도 그래프
여러모로 자주 사용하는 산점도 그래프에 대해서 알아보자.
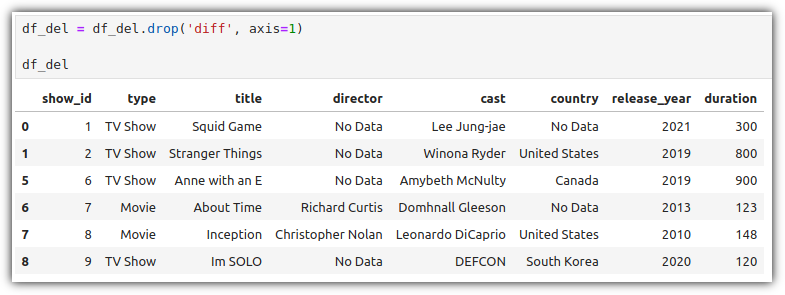
우선 가볍게 결측치 데이터를 살짝 걷어낸 데이터를 준비해보자.
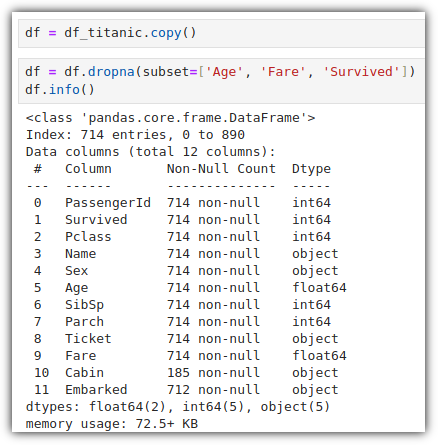
scatter 그래프를 그려보자.

못보던 것들이 많이 보일텐데, 찬찬히 살펴보면 이해할 수 있을 것이다.
plt.figure(figsize=(12, 8)) : 12인치, 8인치 정도의 크기의 그래프로 셋팅
plt.scatter() : 산점도 그래프를 그린다.
. c : 각 데이터 포인트의 색상을 지정
. cmap : 컬러맵 지정
plt.legend() : 범례를 추가한다.
. handles : 범례 핸들을 설정하는 것인데,
scatter.legend_elements() 는 산점도 그래프에서 사용된 생상에 대한 핸들을 반환해준다.
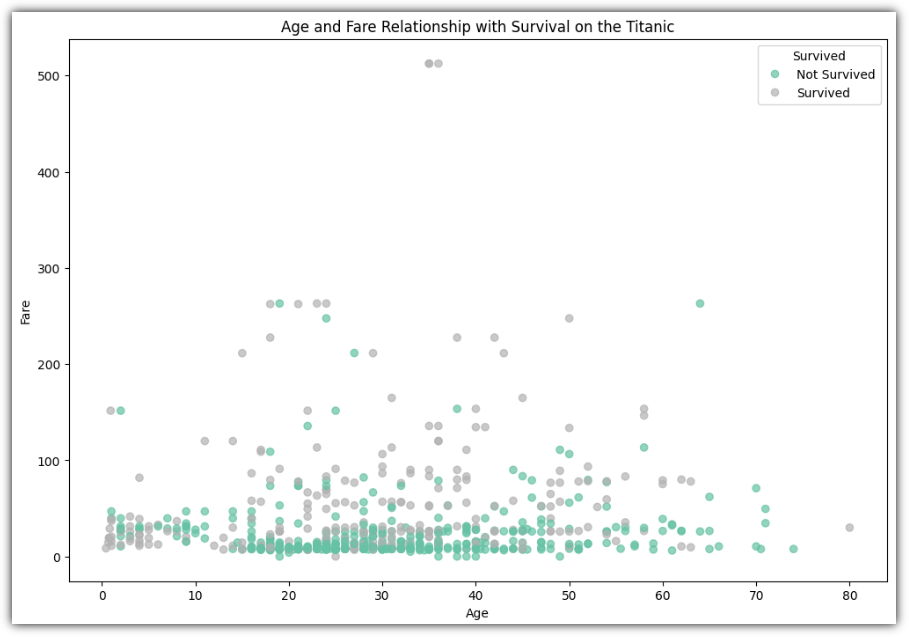
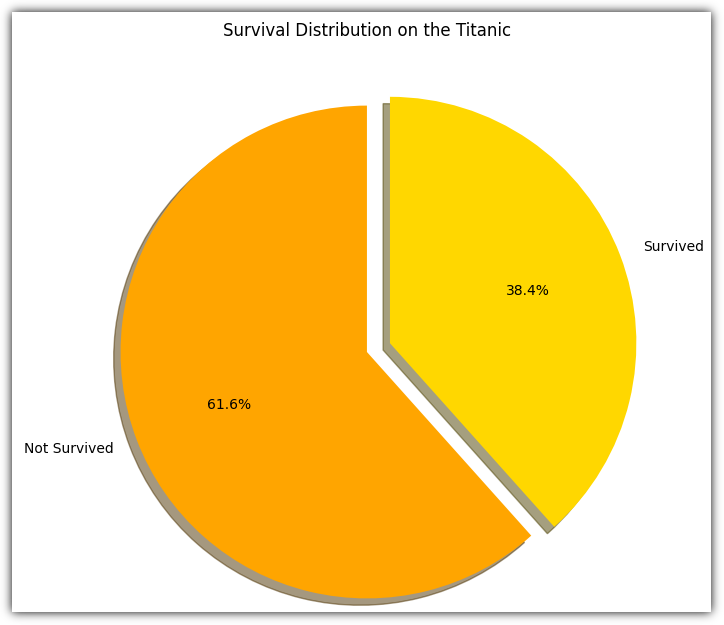
▷ 파이 차트 (Pie Chart)
생존 여부를 가지고 간단하게 파이 차트를 그려보자.
▷ 히스토그램 (Histogram)
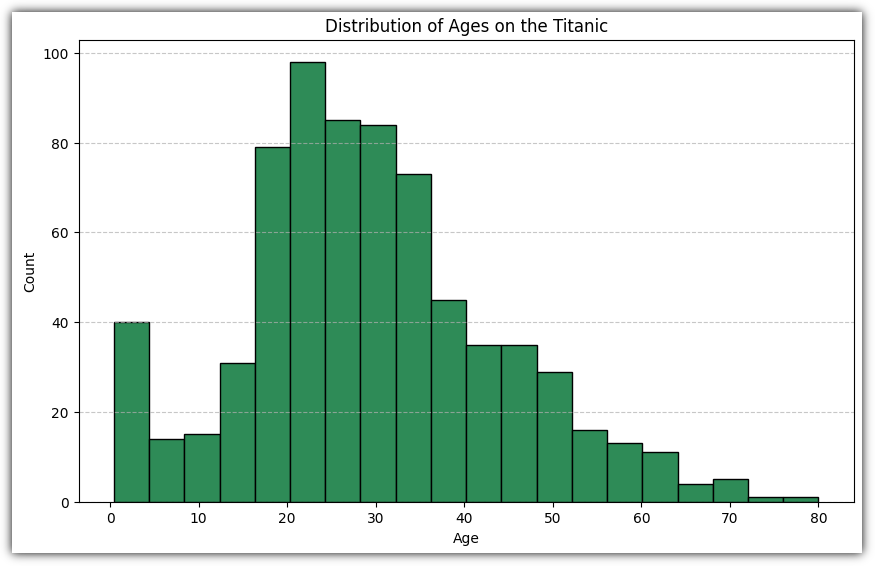
연속된 데이터를 구간으로 나누어 각 구간에 속하는 데이터의 빈도를 표현하는 그래프를 그려보자.
plt.hist() : 히스토그램을 그려준다.
. bins : 구간 개수, 현재는 20개로 설정
. edgecolor : 테두리 색상
④ 다양한 그래프 그려보기 ⑵
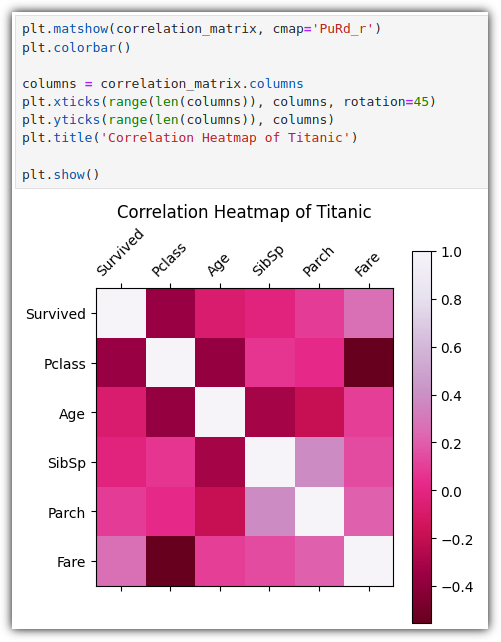
▷ 히트맵 (Heatmap)
히트맵은 2차원 데이터를 색상으로 표현하는 그래프인데, 2가지 방식의 그래프가 존재한다.
- matshow() : 정보를 명확하게 표시하고, 행/열 레이블을 추가하여 표시
- imshow() : 이미지만 표시, 행/열도 추가하지 않으며 색상도 표시하지 않음
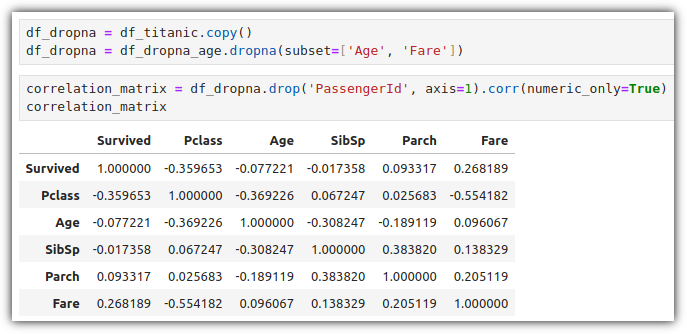
plt.colorbar() : 오른쪽에 색상 참고를 위한 bar 표시
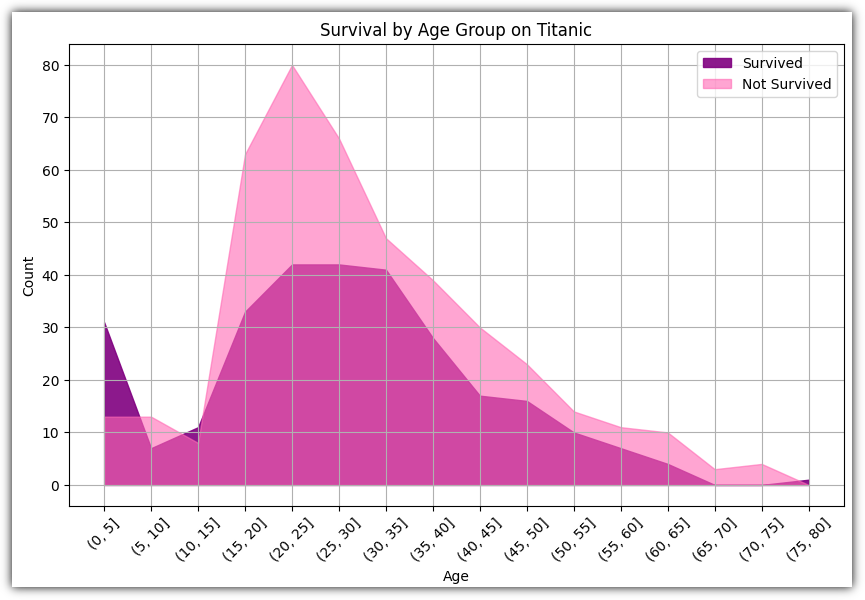
▷ 영역 채우기 그래프 (fill between)
데이터셋 간의 데이터 분포와 차이를 명확하게 시각화하는 데 유용하다.
일단 데이터를 준비해보자.
cut() : 연속형 변수를 구간별로 나누어 범주형 변수로 변환
(observed=False) : 데이터가 없더라도 모든 가능한 조합을 결과에 포함
.size() : 각 그룹의 빈도(크기)
.unstack() : 그룹화된 결과를 피벗 테이블 형태로 변환하여 index를 열로 포함
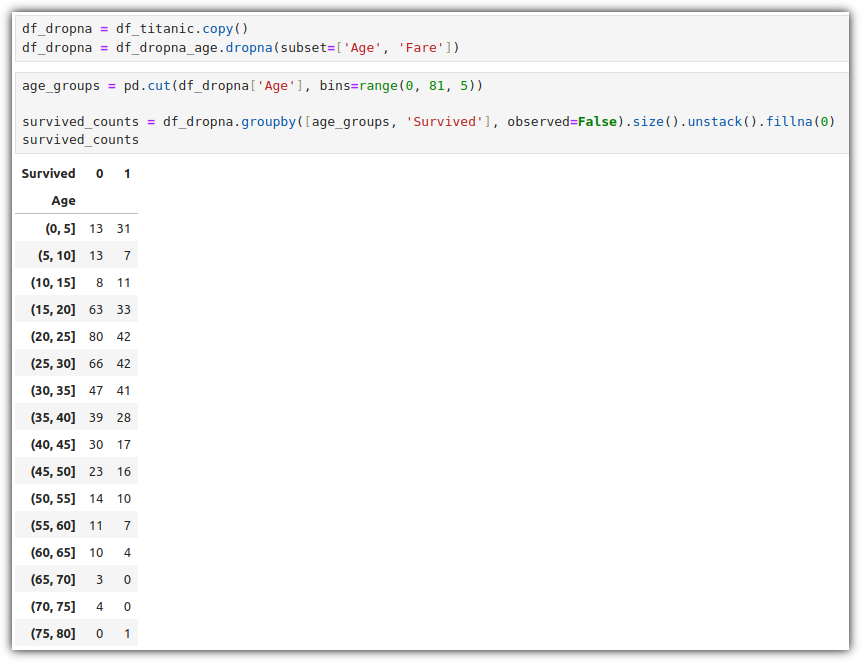
(0, 5] : 0 초과 5 이하
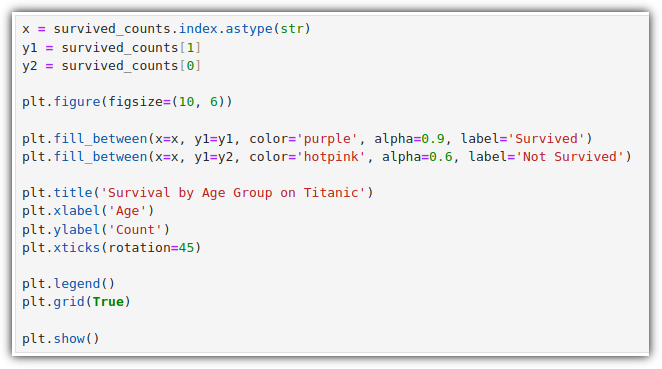
잘 활용하기 위해서는 alpha 값 등에 신경을 써야 겹치는 부분들에 대한 표현을 잘 할 수 있을 것 같다.
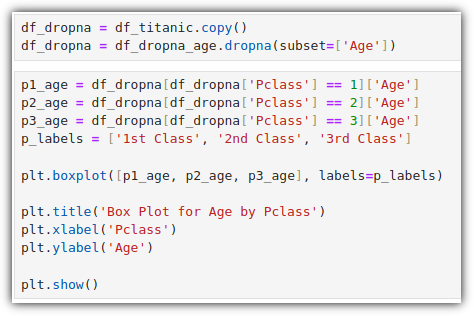
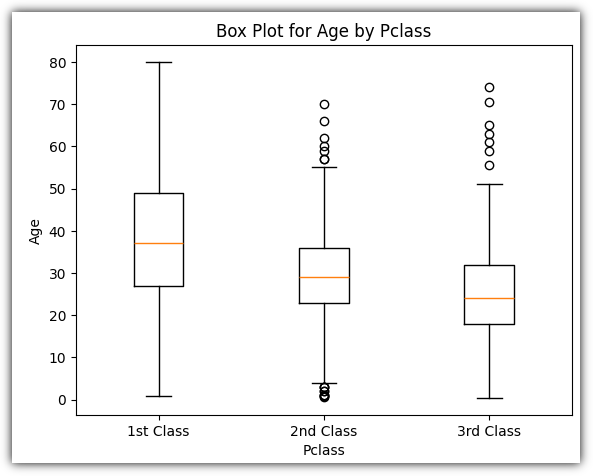
▷ 박스 플롯 (Box Plot)
그래프를 그리기 보다는 그냥 계산으로 사분위수를 계산하는 경우가 더 많지 않나 싶긴 하지만...
2등급/3등급 승객들은 이상치들이 보인다.
▷ 바이올린 플롯 (Violin Plot)
각 데이터 포인트의 밀도를 시각적으로 보여주는 특징
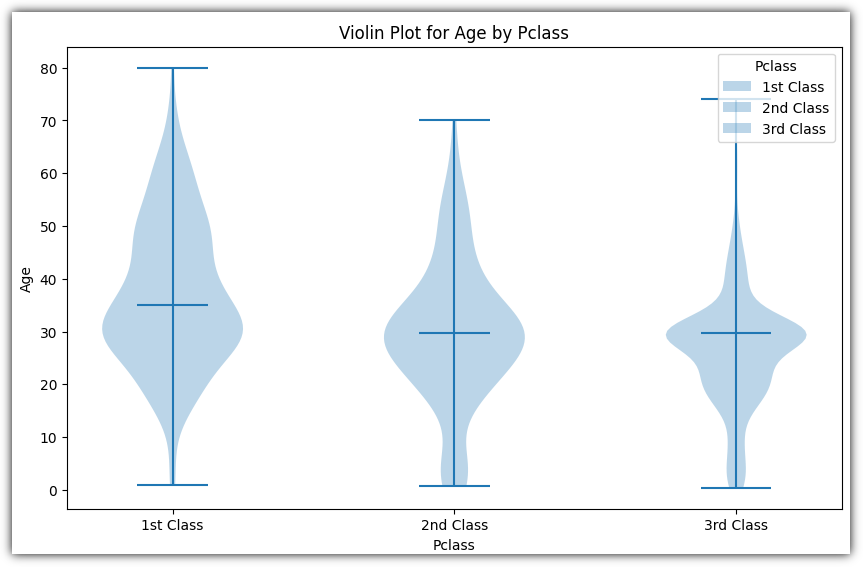
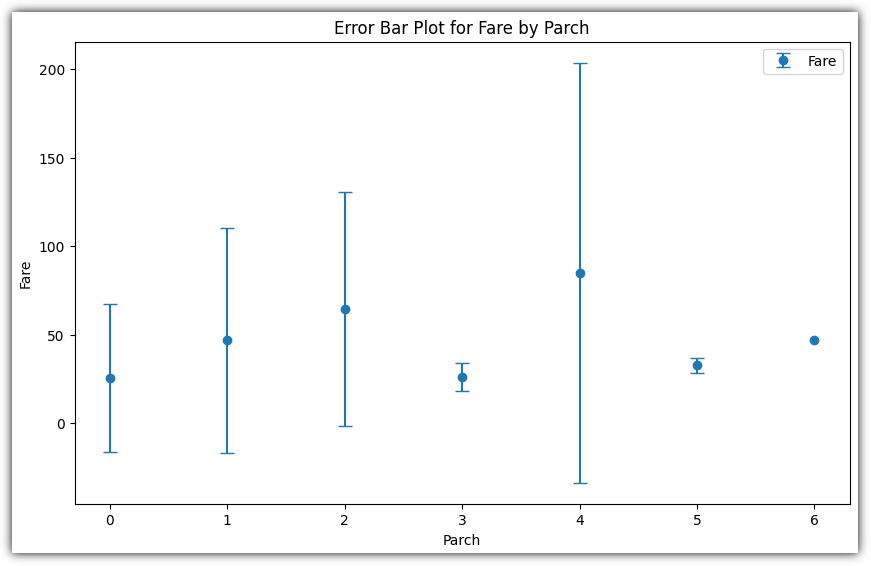
▷ 에러 바 (Error Bar)
개인적으로 처음 본 그래프 형태이다.
평균과 표준 편차를 구해서 이를 그래프로 표현하는 것이다.
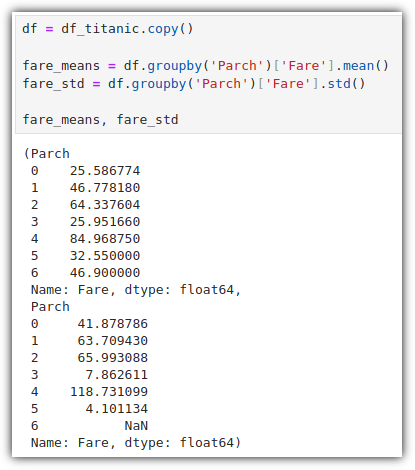

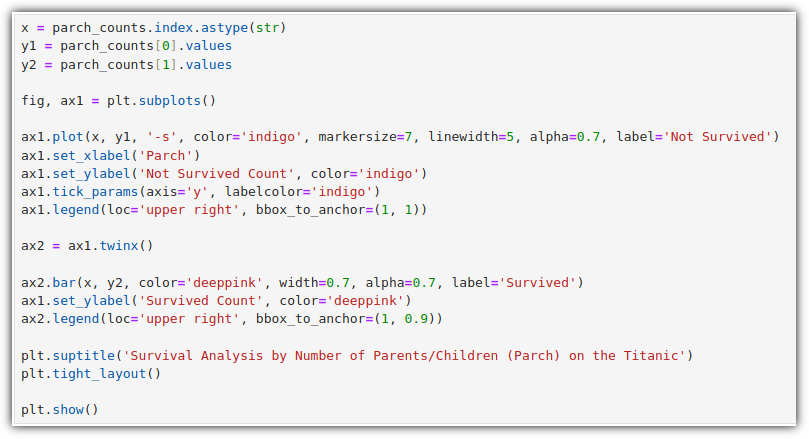
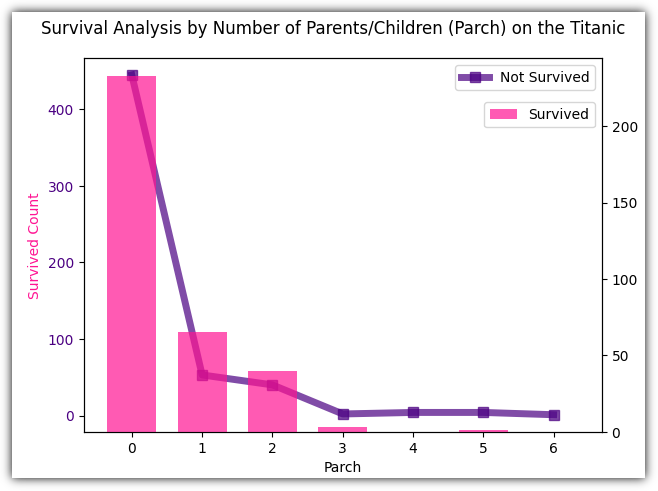
Parch가 4일 때 평균 요금이 가장 높고, 길이가 긴 것으로 보아 해당 그룹의 요금이 크게 퍼져 있음을 표현한다.
Parch가 3일 때 평균 요금이 높지 않고, 에러바의 길이도 비교적 짧다.
⑤ 그래프 한꺼번에 그려보기
그래프를 표현한 결과물을 figure라고 한다.
1개의 그래프일 수도 있고, 여러 그래프일 수도 있다.
이미 앞에서 subplot()을 살짝 맛을 보긴 했는데,
실제로 여러 그래프를 한꺼번에 그리는 방법은 2가지가 있다.
⑴ .subplot()
: 개별 서브플롯을 하나씩 추가하기
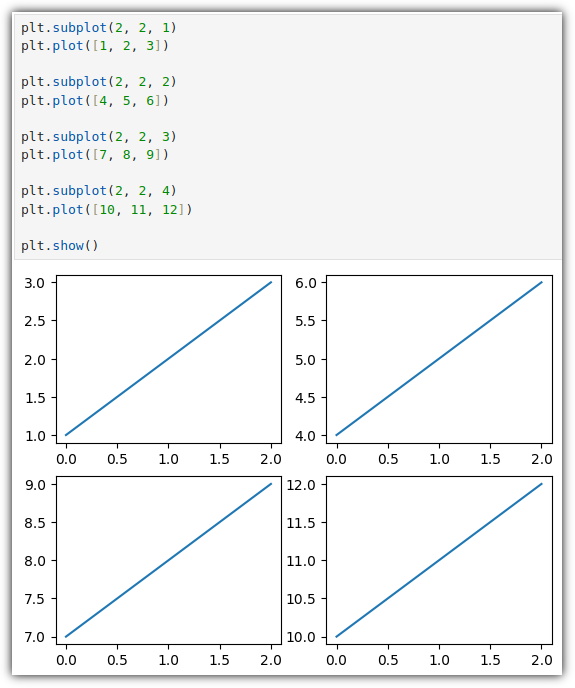
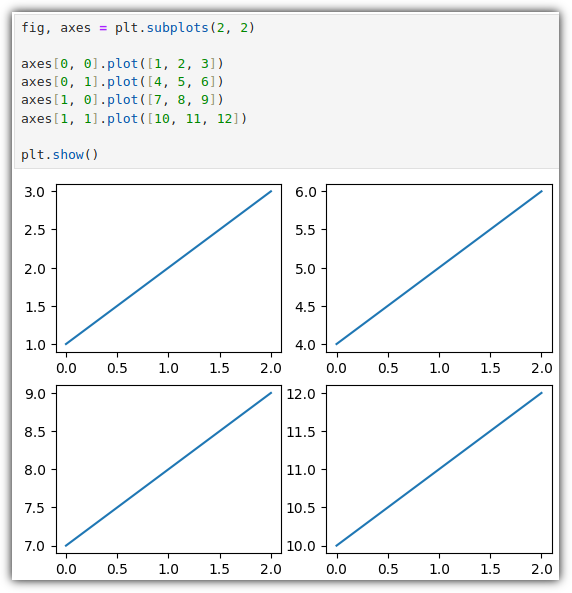
⑵ .subplots()
: 개별 서브플롯을 동시에 생성하기
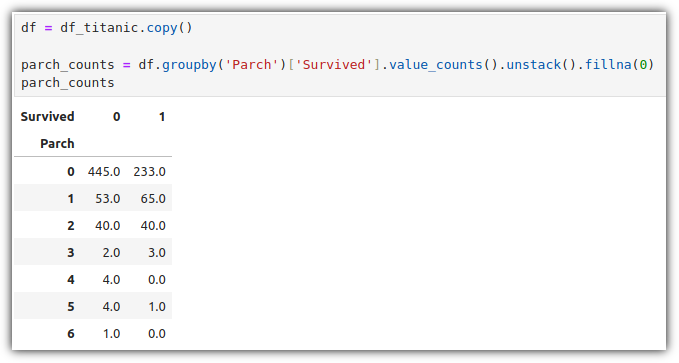
▷ 하나의 서브플롯에 여러 그래프 그리기 (twinx)
2개의 그래프를 그리기 위해 2개의 데이터를 준비했다.
.twinx() : X 축을 공유하는 새로운 axes 객체 생성
⑥ 그래프 저장하기
plt.savefig()를 사용해서 그림파일로 저장을 할 수 있다.
별도로 plt.show()를 실행하지 않아도 그래프가 출력된다.
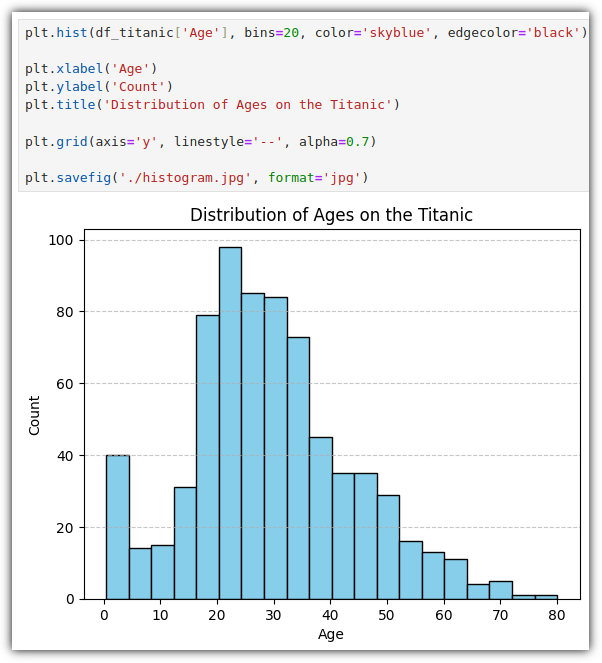
그림 파일이 잘 생성되었음을 볼 수 있다.
와우... 힘들다.
'Books' 카테고리의 다른 글
| [한빛미디어] '나는리뷰어다2025' 선정 (0) | 2025.02.01 |
|---|---|
| [파이썬 데이터 분석가 되기] 02 - Pandas (0) | 2025.01.25 |
| [파이썬 데이터 분석가 되기] 01 - NumPy (1) | 2025.01.18 |
| [파이썬 데이터 분석가 되기] 00 - 공부 시작 (0) | 2025.01.15 |
| [혼공머신] 6주차 - CH.07 딥러닝을 시작합니다 (0) | 2024.08.25 |