이번에는 웹 데이터를 수집하는 것에 대해서 알아보는 챕터이다.

1. robots.txt
- 웹 사이트를 크롤링하는 것은 불법의 여지가 있으며, 피해를 줄 수도 있음
- 최소한 해당 사이트의 robots.txt 파일을 참고해서 제약 사항들을 잘 지켜주는 것이 중요함
- 이번 실습에서 활용할 야후 파이낸스 사이트의 robots.txt 파일 내용 확인
. https://finance.yahoo.com/robots.txt
. User-agent: 크롤러 식별
. Disallow: 크롤링 금지 디렉토리/페이지 지정
. Allow (Disallow 함께 사용): 크롤링 허용 디렉토리/페이지 지정
. Sitemap: 사이트 맵 파일의 위치를 지정
2. BeautifulSoup
- HTML/XML 문서의 구문을 분석하기 위한 파이썬 패키지
- 2004년 발표 후 현재(25년 2월 16일) 기준 v4.13.2 버전까지 출시 → bs4
. https://www.crummy.com/software/BeautifulSoup/
3. CSS Selector
- CSS(Cascading Style Sheets)에서 사용되는 선택자(Selector)를 활용해 HTML 요소를 선택하는 방법
- 이 때 사용할 수 있는 여러 종류의 Selector가 있다.
① Class Selector
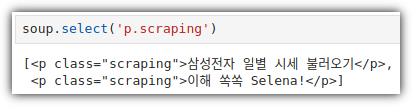
② Child Selector
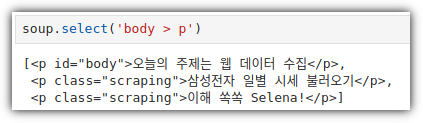
③ ID Selector
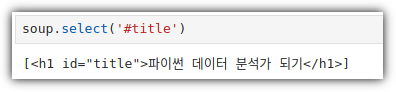
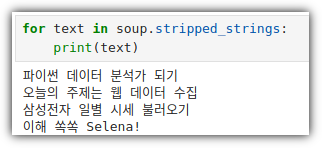
- Selector와 별도로 그냥 텍스트만 추출할 수도 있음
. 자동으로 좌우 공백들은 제외해서 추출함
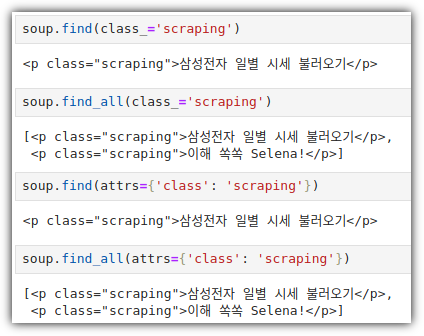
4. find() / find_all()
- CSS Selector도 충분히 좋은 방법이지만, find() / find_all() 을 이용해서도 원하는 것을 얻을 수 있다.
① Class
② Tag
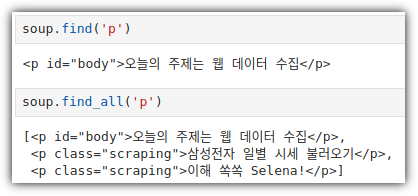
③ ID

5. Web
- 이번 실습에서 사용할 야후 파이넌스 사이트에 접속을 해보자.
- 'Samsung Enecltronics'를 검색해서 들어가고, 왼쪽 메뉴의 'Historical Data'를 선택하자.
. https://finance.yahoo.com/quote/005930.KS/history/
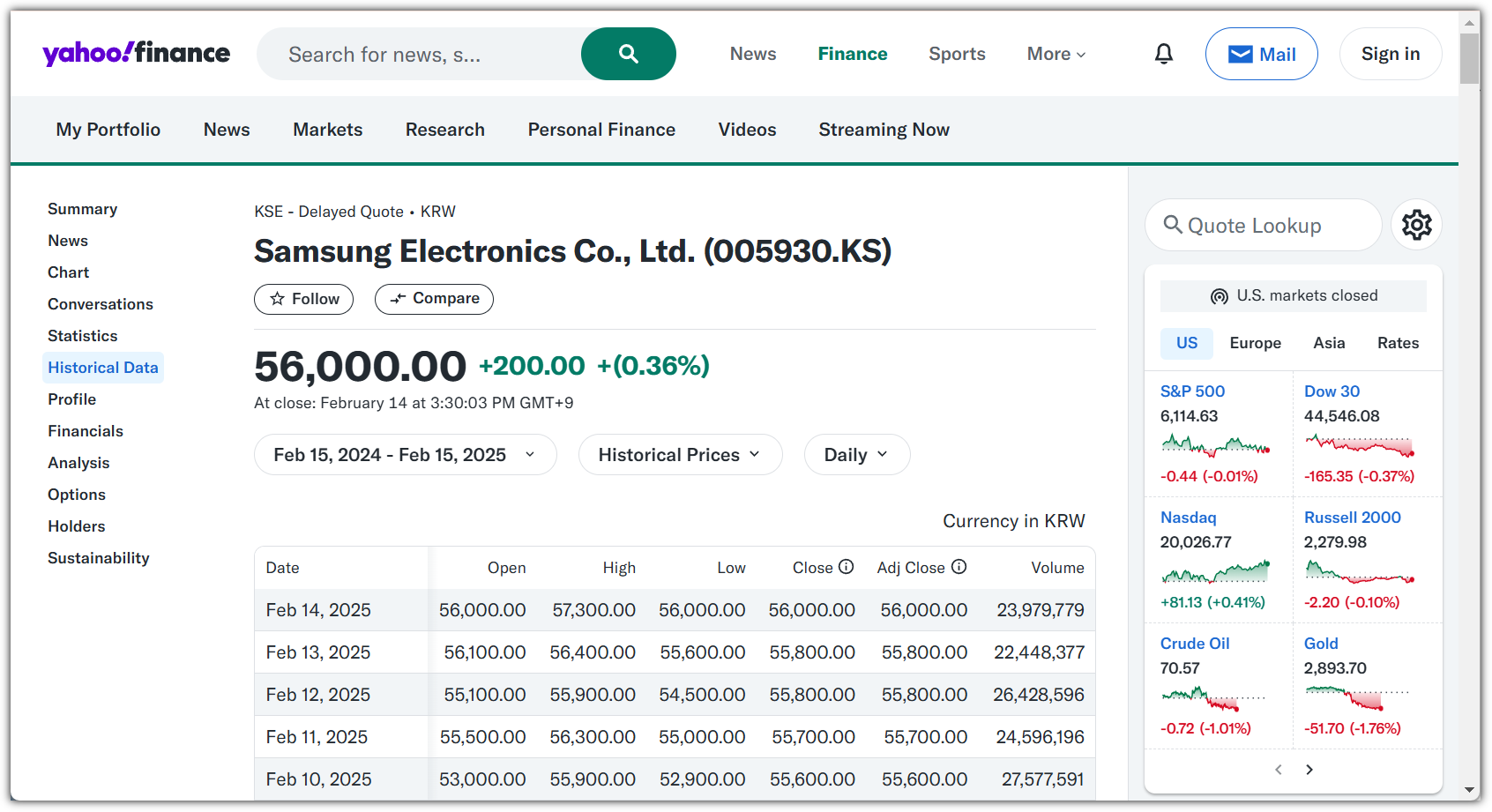
- 그러면, 이제 Python으로 사이트 정보를 읽어와보자.
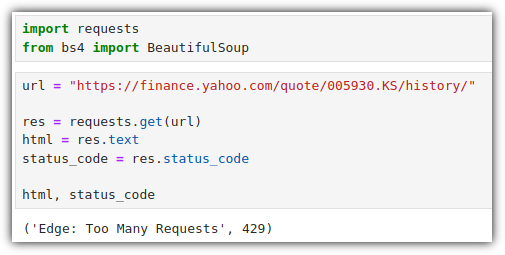
- 어?! 읽어오지 못한다. 그런데 왠 "Too Many Requests" ????
. 책에서는 404 에러가 발생한다고 했는데, 나는 매번 429 에러가 발생을 했다.
6. Header
- 내가 웹브라우저로 접근하는 것처럼 해야 접속이 될 것 같다.
- F12 눌러서 개발자 도구 열고 → 상단 메뉴 中 '네트워크' 선택 → F5 눌러서 사이트 리프레쉬 → "요청 헤더" 확인
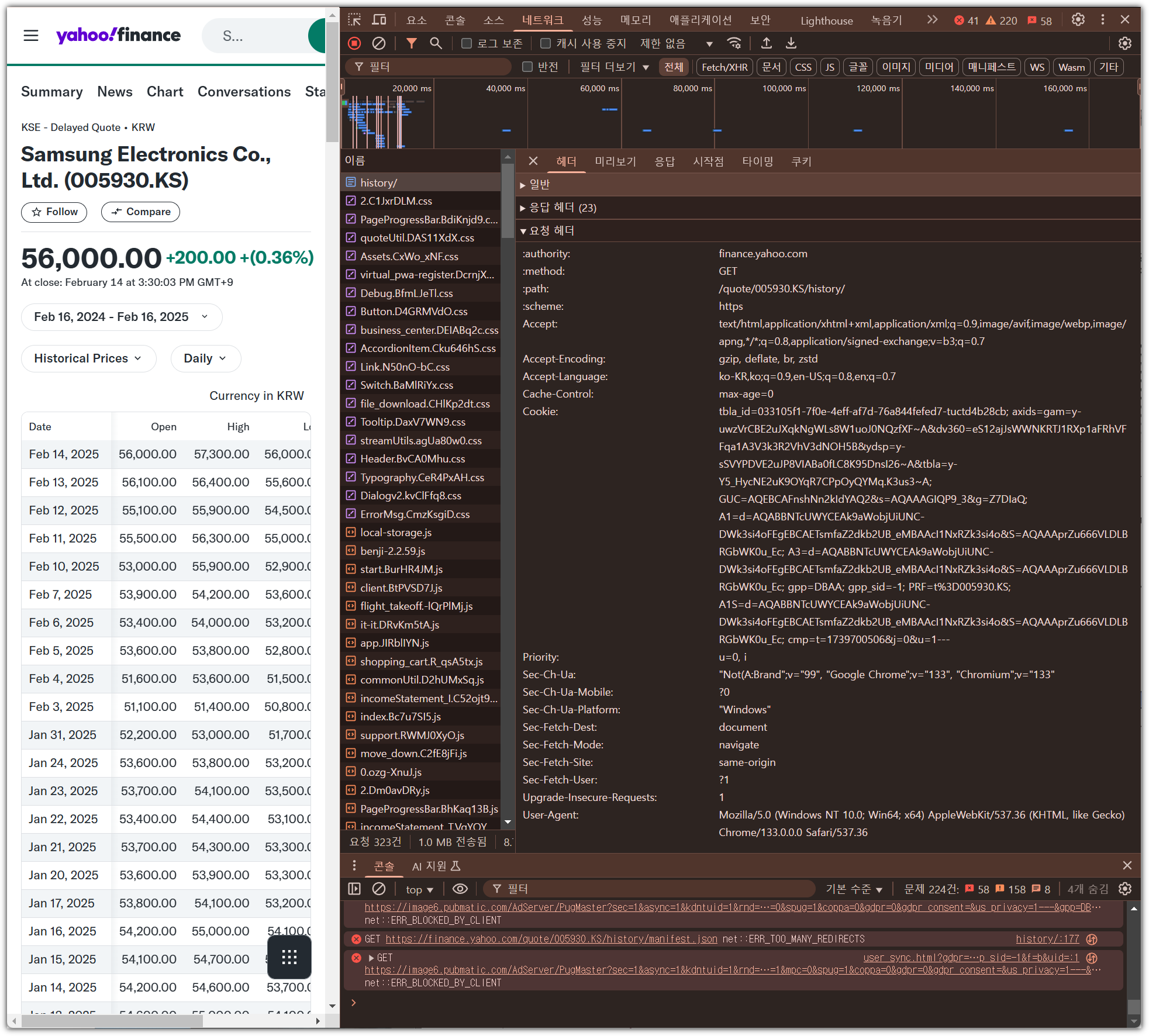
- 'User-Agent' / 'accept' 2개 정보를 copy해서 넣어보자.
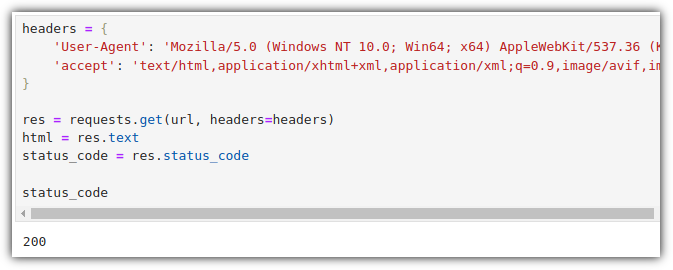
- 성공적이다 !!!
7. Parse
- 내가 읽어오기 원하는 정보가 있는 곳에서 마우스 오른쪽 버튼 클릭 → '검사' 선택
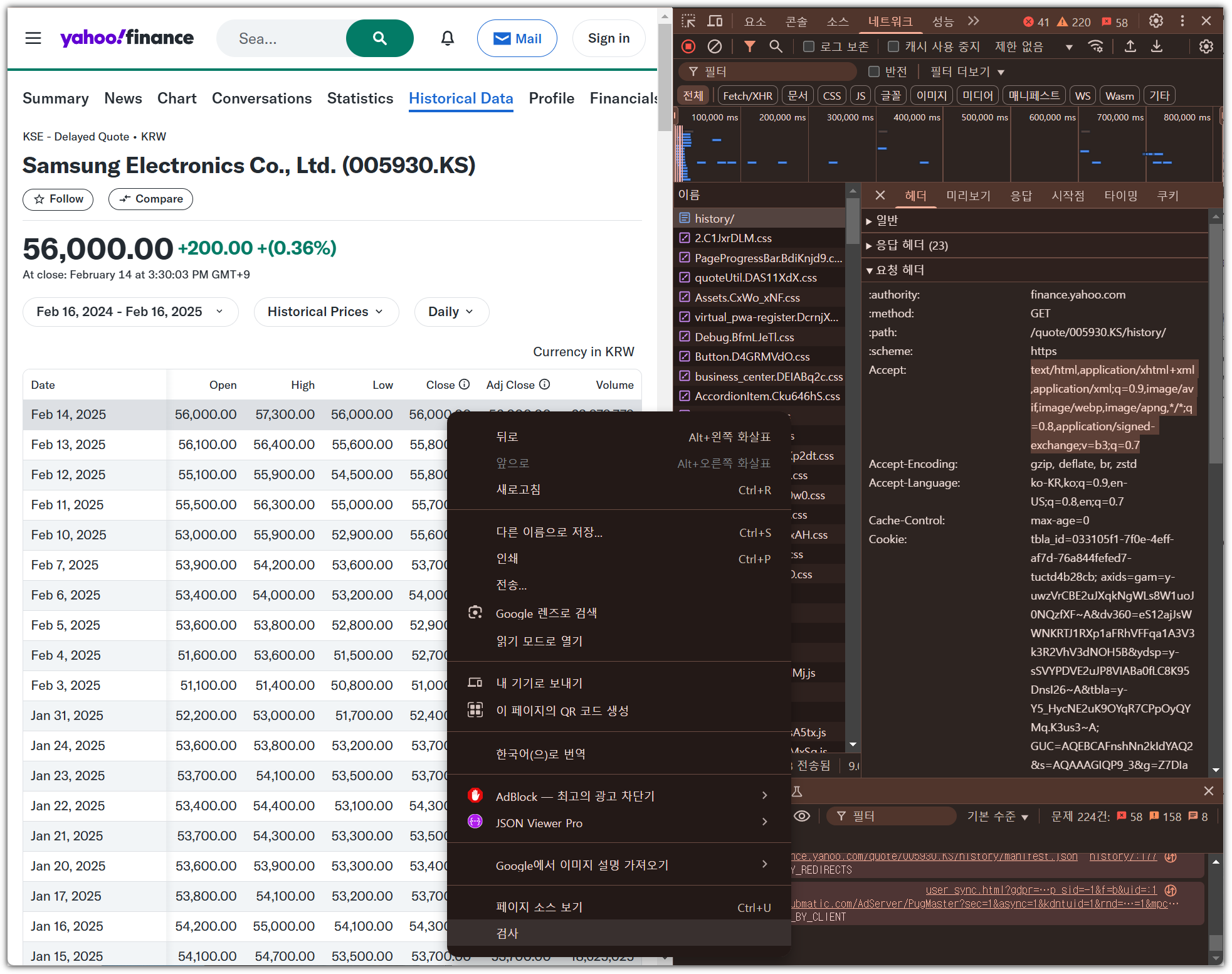
- 그러면, 개발자 모드 화면에 HTML Tag 코드 확인 가능
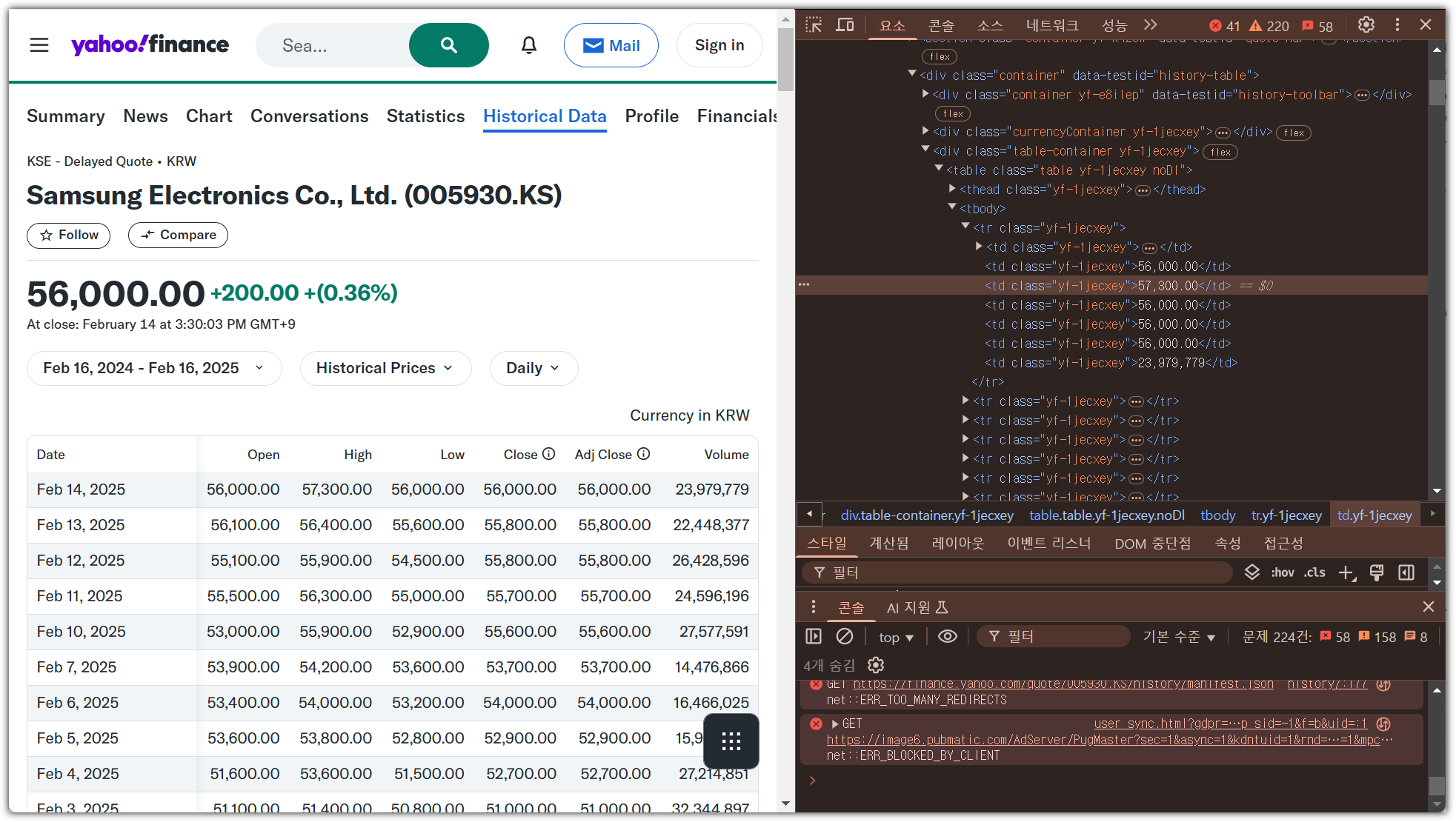
- 잘 살펴보면 특정 row를 읽어오면 될텐데, '<tr>' 태그로 되어 있는 것을 볼 수 있다.

- find_all() 사용하면 상당히 많은 내용이 잡히기 때문에, 출력은 일부분만 하도록 했다.
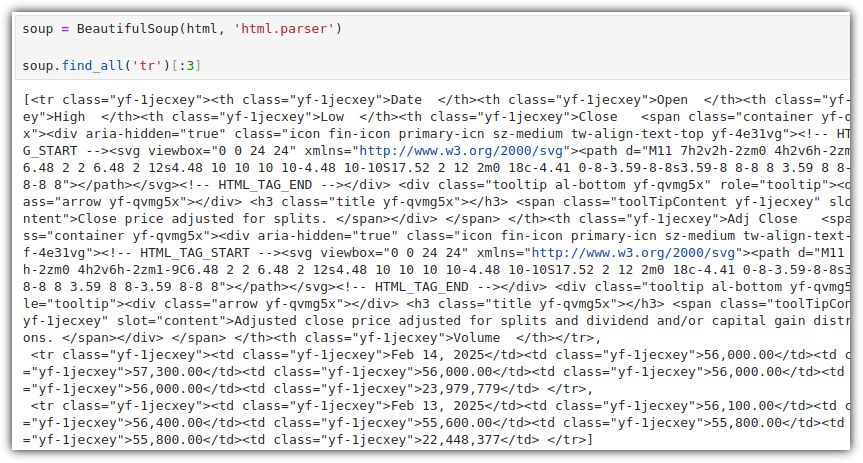
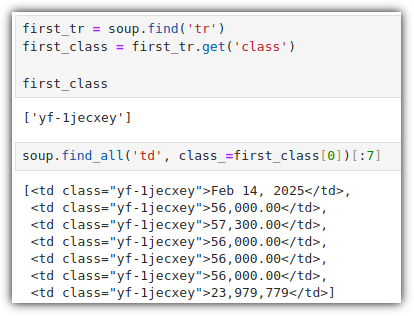
- 좀 더 구체적으로 원하는 정보를 찾아내기 위해서, class 값을 얻어오고 활용하는 것을 해보자.
8. Pretty Print
- 하나의 row에는 7개의 column으로 구성되었다는 것을 알고 있으니, 이를 이용해서 예쁘게 출력을 해보자.
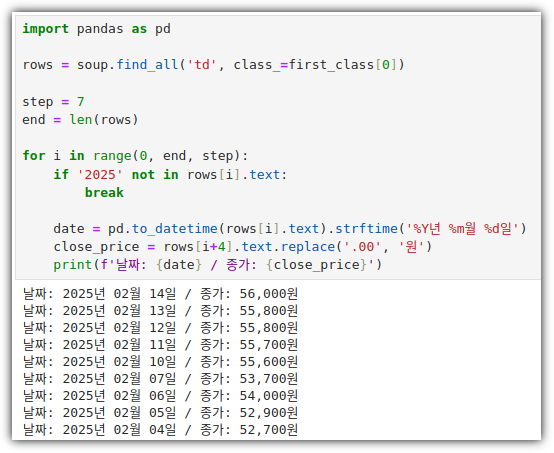
- 사실 이런식으로 처리하는 것은 위험 부담이 크다.
. 아래와 같은 예외 데이터가 있을 확률이 아주 높기 때문이다.

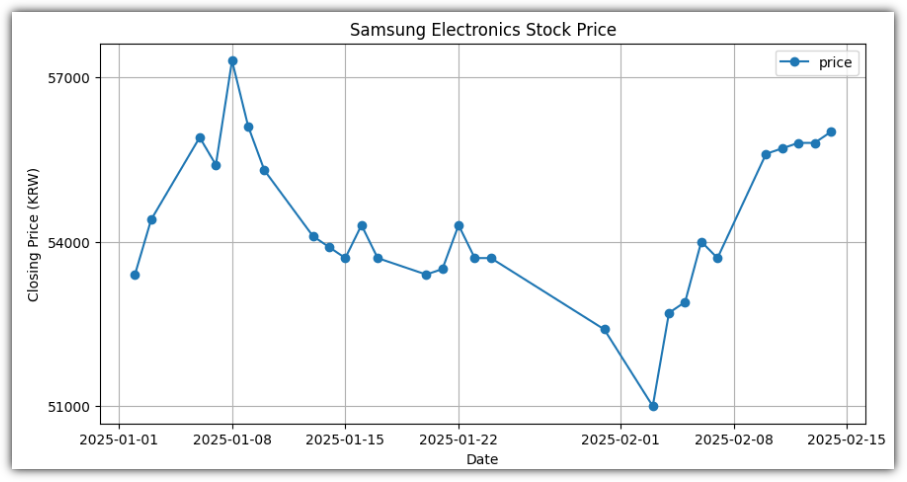
9. Graph
- Matplotlib을 이용해서 그래프를 그려보자.
. date는 일반적인 날짜 형태로 바꿔주는 것이 좋다
. price는 integer 형태로 바꿔줘야 한다.

10. Pandas
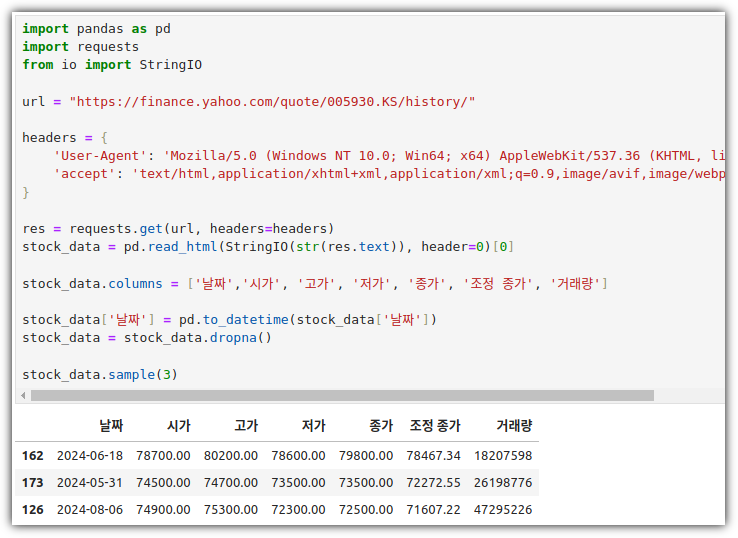
- BeautifulSoup 대신에 pandas를 이용할 수도 있다.
. 하지만, 내부적으로는 BeautifulSoup 및 lxml 라이브러리를 이용한다.
간만에 다시 한 번 찬찬히 살펴볼 수 있어서 좋았다!
'Books' 카테고리의 다른 글
| [한빛미디어] 밑바닥부터 시작하는 딥러닝 1 (Deel Learning from Scratch 1) - 리마스터판 (1) | 2025.02.27 |
|---|---|
| [파이썬 데이터 분석가 되기] 06 - PRJ: Netflix (0) | 2025.02.23 |
| [파이썬 데이터 분석가 되기] 04 - Seaborn (0) | 2025.02.08 |
| [한빛미디어] '나는리뷰어다2025' 선정 (0) | 2025.02.01 |
| [파이썬 데이터 분석가 되기] 03 - Matplotlib (0) | 2025.02.01 |