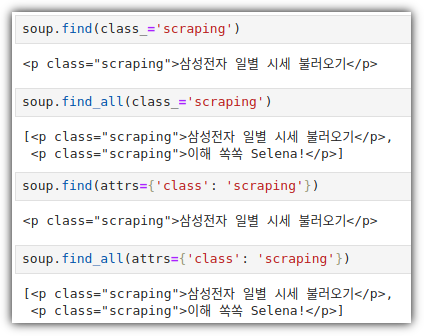
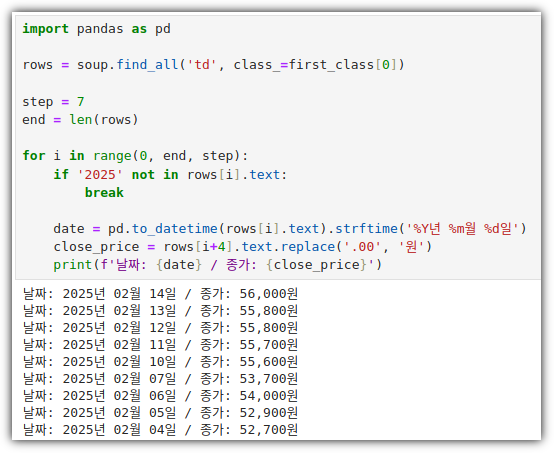
데이터 분석 공부를 하게 되면
필수로 공부하게 되는 파이썬 라이브러리 코스 "Numpy → Pandas"
Numpy는 지난 번에 다음과 같이 살펴봤다.
- [파이썬 데이터 분석가 되기] 01 - NumPy
이번에 살펴볼 것은 "Pandas "
① 판다스 시작하기
② 데이터 내용 확인하기
③ 특정 열 선택하기
④ 데이터 필터링 하기
⑤ 결측치 처리하기
⑥ 데이터 통계 처리하기
⑦ 데이터프레임에 행/열 추가하거나 삭제하기
지난 포스팅에서도 말했지만 처음 공부하는 것은 아니기 때문에
기본적인 것들은 생략하고 기억하면 좋을 것들 중심으로 정리해보겠다.
책에서 언급하지 않는 내용들도 조금 더 포함했고,
설명 방법도 조금 다르게 정리한 내역도 있으니 참고하기 바란다.
실습은 local 환경에 mini-conda 설치해서
직접 Jupyter Notebook 띄워서 진행했다(당연히 Colab 환경과 별 차이는 없을 것이다).
① 판다스 시작하기 예전에는(예전이라고 해도 사실 그렇게 오래된 것은 아닐텐데, 요즘 AI 세상은 너무 빨리 변해서)
Numpy와 Pandas가 서로 상호보완적으로 많이 사용되었었던 것 같은데,
최근에는 사실 Pandas만으로도 대부분 처리할 수 있어서
굳이 Numpy 공부 후 Pandas를 공부할 필요 없이 바로 Pandas로 공부를 해도 괜찮은 것 같다.
다만, Pandas도 Numpy를 기반으로 한다고 할 수도 있기에... 뭐 같이 공부한다고 손해볼 것은 없다.
Pandas에서 제공하는 데이터 타입
- Series : 1차원 배열과 같은 형태. index와 value로 구성.
- DataFrame : 2차원 배열 형태. index와 column으로 구성. 하나의 column은 Series.
▷ List to Series pd.Series() 함수에 List를 넣어주면 된다.
index와 value로 잘 생성된 것을 볼 수 있을 것이다.
value에 여러 형식의 데이터 타입이 포함되어 있기에 'object'로 분류 된다.
▷ Dict to DataFrame pd.DataFrame()에 Dictionary 데이터를 넣어주면 된다.
print()로 출력을 하면 안예쁘게 나오는데,
Jupyter Notebook 환경인 점을 이용해서 그냥 해당 변수를 찍어주면 나름 예쁘게 내용을 살펴볼 수 있다.
▷ DataFrame to CSV File Pandas DataFrame은 다양한 형태로 저장할 수도 있다.
일반적으로 많이 사용하는 CSV 파일로 저장을 하고 싶으면 .to_csv() 를 사용하면 된다.
"index=False" 파라미터를 주지 않으면 행 이름까지 저장하는 것을 막기 위한 코드이다.
왼쪽 파일 목록에 생성한 CSV 파일이 보일 것이다.
▷ CSV File to DataFrame 반대로 CSV 파일을 읽어와서 DataFrame을 만드는 것은 어떻게 할 수 있을까?
정답은 ".read_csv()"
local에 있는 파일뿐만 아니라 웹에 있는 파일도 불러올 수 있다.
▷ DataType in Pandas "int / float / object" 3종 밖에 없는 줄 알았는데, 의외로 다양한 데이터타입을 지원하고 있다.
하지만, 중요한 것은 결국 "object "
② 데이터 내용 확인하기 ▷ columns 앞에서 생성한 내역을 이용해서 column 내용부터 확인해보자.
column은 기본적으로는 Index 형식이고, list 데이터 타입으로 변환해서 살펴볼 수도 있다.
▷ index column과 마찬가지로 index에 대해서도 살펴보자.
여기에서 나오는 index는 실제 데이터 안에 포함된 정보가 아니라
일련번호로 설정되어 있다.
index 값을 명시적으로 정해주면 어떻게 될까?
내가 원하는 형태로 설정할 수가 있다.
임의로 정해준 값이 아니라, 명시적인 값이 있는 Index 형태의 데이터로 되었다는 것을 확인할 수 있다.
▷ loc[ ] 이렇게 정해진 index 값을 이용해서 특정 행을 지칭할 수도 있다.
앞서 살펴본 Numpy에서의 indexing / slicing 모두 적용 가능하다.
▷ head() / tail() / sample() 데이터의 일부 내용을 살펴보는 방법들을 알아보자.
데이터 앞부분의 내역을 살펴보는 것은 head()를 사용하면 된다.
기본적으로는 5개의 데이터를 보여주지만, 원하는 양만큼 보고 싶으면 파라미터로 전달하면 된다.
데이터의 뒷 부분을 살펴보는 것은 tail()을 살펴보면 된다.
임의의 데이터를 뽑아서 보여주는 것은 sample()이 있는데,
기본적으로 1개의 데이터를 보여주지만 원하는 양이 있으면 파라미터로 전달해주면 된다.
▷ shape 데이터의 전체 크기를 살펴보고 싶으면 shape을 찍어보면 된다.
정말 자주 사용하는 것인데, 함수 형태가 아님을 주의깊게 살펴보기 바란다.
▷ info() DataFrame 데이터의 전체적인 내용을 살펴보고 싶으면 info()를 사용해보자.
정말 많은 정보를 깔끔하게 잘 보여주고 있다.
index 및 column 정보들을 상세하게 보여주고 있으며,
각 column의 Non-Null 정보, DataType 정보들을 모두 보여주고 있다.
심지어 차지하고 있는 메모리 크기까지도 알려준다.
모두 중요한 정보이지만, 가장 중요하게 살펴봐야 할 것은 Non-Null Count 부분이지 싶다.
결측치가 얼마나 있는지에 따라 후속으로 진행해야 할 일들이 정해지기 때문이다.
③ 특정 열 선택하기 ▷ 단일 column = Series DataFrame의 column 하나는 Series로 볼 수도 있다.
이것을 어떻게 추출할 수 있는지를 살펴보자.
"DataFrame['column_name'] " 형식으로 column을 추출할 수 있다.
이렇게 추출했을 때, index 정보까지 같이 따라오는 것도 확인할 수 있다.
"DataFrame.column_name " 형식으로도 column을 추출할 수 있다.
▷ 복수 column = DataFrame 원하는 column의 조합으로 추출하고자 할 때에는
"DataFrame[['column1', 'column2', 'column#'] ] " 형식으로 수행할 수 있다.
여기에서 주의깊게 살펴봐야할 것은 "이중 대괄호 "로 표기해야하는 것이다.
복수 column을 표기하려면 대괄호로 묶어서 넣어줘야 하는 것이다.
앞에서 하나의 column을 추출하면 Series라고 했는데,
1개 열로 구성된 DataFrame으로 추출할 수도 있다.
"DataFrame['column_name'] " 형식으로 했을 때 Series로 추출되었음을 확인할 수 있다.
그런데, "DataFrame[['column_name']] " 형식으로 추출하면 DataFrame으로 추출할 수 있다.
이 부분은 잘 기억해둬야겠다.
▷ Boolean Indexing 특정 조건에 맞는 행을 선택하는 방법으로 'Boolean Indexing'이라는 방법이 있다.
이것을 활용해서 원하는 열들의 특정 조건에 맞는 행 데이터들을 추출하는 방법은 다음과 같다.
행의 조건을 앞에 정의하고 원하는 column을 뒤에 명시한다고 생각하면 될 것 같다.
④ 데이터 필터링 하기 여기부터는 정신 똑바로 차리고 잘 살펴봐야 한다. (빤짝!)
앞서 잠깐 살펴본 "Boolean Indexing"의 심화과정이라고 생각할 수 있을 것 같다.
DataFrame에 대해서 '비교 연산자'를 사용하면 전체 행에 대한 boolean 결과가 나온다.
이것을 DataFrame Column에 넣어주면 True 행만 추출이 되는 것이다.
▷ Operators 단순한 비교 연산자 외에 다른 연산자들을 더 알아보자.
먼저 살펴볼 것은 '부정 연산자(~, Not Operator) '이다.
다음 알아볼 것은 and(&) / or(|) 연산자를 알아보자.
조건문을 변수로 받을 수도 있다.
▷ loc[ ] / iloc[ ] 앞에서 "loc[ ]"에 대해서 간단히 맛을 봤다.
index를 명시적으로 지정해서 특정 행을 추출했었던 것인데, 이번에 좀 더 일반적인 사용법을 알아보겠다.
DataFrame.loc[ row, column ]
너무나 간단해보이지만, 정말 다양한 변형 활용이 가능하다.
DataFrame.loc[ :, [column1, column2] ]
DataFrame.loc[ [row1, row2], [column1, column2] ]
행 부분을 조금 더 알아보자.
index 값을 명시적으로 기재한 경우에는 잘 동작했으나,
slicing과 같은 방법으로는 제대로 실행이 되지 않는다.
index 숫자로 지정하고 싶은 경우에는 "iloc[] "를 사용하면 된다.
명칭 자체가 그렇다 ^^ "iloc(Integer Location )"
name을 사용하고 싶으면 loc[],
index를 사용하고 싶으면 iloc[]
▷ isin() 띄어쓰기가 생략된 문법이다 ^^
is in ()
isin() 함수 역시 결과가 Boolean 행렬로 나온다.
그렇기에 Boolean Indexing과 같은 방식으로 사용하면 된다.
여기에서 주의할 것은 파라미터로 넘길 때 하나의 요소만 사용하더라도
list 형태로(대괄호) 넘겨줘야 한다는 점이다 !!!
⑤ 결측치 처리하기 머신러닝, 데이터 분석 등을 할 때 가장 중요한 것 중 하나가 바로 결측치에 대한 관리다.
▷ NA, NaN, None 결측치라는 것은 값이 비었다는 것인데, 이것을 어떻게 표기할 것인지에 대한 문제가 있다.
Pandas에서는 "NA (Not Available)", "NaN (Not a Number)", "None " 두 가지 방식으로 표기하고 있다.
DataFrame 데이터 내역을 보다보면 "NaN"으로 되어있는 결측치를 볼 수 있다.
보다 일반적인 것은 Numpy의 "NaN" 개념이고, 실제로도 "np.nan"으로 지칭하는 것이 일반적이다.
NaN은 Numpy에서 사용하는 것이고, None은 Python 자체에서 사용하는 것이다.
NA 정도가 Pandas에 특화된 것인데, 나름의 추가적인 특성도 갖고 있다.
세가지 모두 NaN 처리가 되었지만, 조금 다른 특성들이 있긴 하다.
여러 상황을 고려하기 싫으면 np.nan을 사용하길 권장하고,
굳이 numpy 라이브러리를 import하기 싫을 때(pandas만 import 했을 때)에만 pd.NA를 사용하면 되지 않을까 한다.
이런 결측치 값을 어떻게 할 것인지에 대해서 다음의 4단계로 알아보자.
⒜ 확인하기
⒝ 대체하기
⒞ 제거하기
⒟ 추출하기/저장하기
⒜ 확인하기 - .isna() / .isna().sum() / .info()
각 값의 NaN 여부를 확인해볼 수 있다.
사실 알고 싶은 것은 각 column의 결측치 개수가 궁금하기에 .sum() 함수까지 붙여주는 것이 더 일반적이다.
한눈에 확 들어온다!
사실 .info() 만으로도 충분히 알 수는 있다.
비율을 확인해볼 수도 있다.
⒝ 대체하기 - .fillna() / .replace()
nan 값을 정해준 값으로 fill 해주는 함수이다.
셀레나 쌤(저자)이 말한 것처럼 원본을 그대로 작업하는 것이 명확하고 좋다. 또한 메모리도 보다 효율적이다.
하지만, 이것 저것 테스트해보고 공부할 때에는 원본을 그대로 놔둔채로
장난감(?)을 하나 만들어서 마음껏 뜯고 맛보고 즐기고(^^),
필요하면 다시 또 원본에서 장난감을 만들고... 하는 방식이 편해서 나는 위와 같이 해봤다.
말이 길어질 수도 있어서... 책에서도 뒤에 언급할 것으로 예상되지만,
Python의 특성상 그냥 변수에 할당하면 원본과 연결 고리가 생기므로
.copy()로 확실하게 명시적으로 연결고리가 끊긴 복사본을 만들어서 변수 할당해줘야 한다.
이번에는 .replace()를 이용해서 결측치 값을 대체해보자.
앞의 .fillna()도 그렇고, .replace()도 그렇고 자기 자신의 값을 실제 변경하지는 않는다.
변경한 결과값을 되돌려 줄 뿐이다.
그렇기에 앞에 원본에 그 결과를 반영하라고 변수 할당해줘야 변경한 값을 저장한다.
⒞ 제거하기 - .dropna(axis=#)
일단 현재까지 진행된 데이터프레임 데이터들의 상황을 확인해보자.
앞서 결측치의 값 대체를 통해서 대부분 처리를 했고, 하나의 column이 남아있다.
꼭 하나의 column에 대해서만 적용되는 것은 아니고,
결측치가 있는 column을 삭제해버리고 싶을 때 사용하는 것이 바로 .dropna(axis=1) 이다.
파라미터로 있는 axis=1 부분을 보면 알겠지만, column이 아닌 row에 대해서도 적용할 수 있다.
결측치 값이 하나라도 있는 row에 대해서는 모두 삭제를 해버렸기 때문에, 하나의 row만 남았다.
그러면, 내가 지정한 column을 기준으로만 결측치 row를 삭제하고 싶으면 어떻게 해야할까?
subset 파라미터로 column 목록을 지정해주면 된다.
※ inplace=True
앞에서 잠깐 언급했는데, pandas의 상당히 많은 함수들의 경우에 원본 값을 직접 수정하지 않는다.
그래서 지금까지처럼 함수 실행 결과를 변수에 할당하도록 작성을 했다.
하지만, pandas에서는 그냥 바로 원본에 그 결과를 반영하도록 할 수 있는 파라미터가 있다.
뭔가 편해보이지만, 사실 권장하는 방법은 아니다.
앞서서 말했지만, 원본을 수정하는 것 자체를 그다지 권장하지 않기 때문이다.
그냥 이런 방법도 있구나~ 하고 참고하기 바란다.
⒟ 추출하기/저장하기 - .to_csv()
이렇게 정제 작업을 거친 결과를 다음을 위해 파일로 저장을 해보자.
예쁘게 잘 저장된 것을 확인할 수 있다.
다음에는 정제 작업을 다시 할 필요 없이 해당 파일을 바로 불러오면 된다.
⑥ 데이터 통계 처리하기 데이터들이 모여 있으니 이에 대한 통계 정보를 확인하는 것은 당연한 수순일 것이다.
▷ 평균값(mean) / 중앙값(median) / 합계(sum) / 최댓값(max) / 최솟값(min) 가장 기본적인 통계값들을 구해보자.
너무 편하다!!
▷ 표준편차(std) / 분산(var) 표준편차와 분산도 그냥 쓰면 된다.
▷ count() / value_counts() count()는 결측치를 제외한 row의 개수를 알려준다.
value_counts()는 값 각자가 몇 개가 있는지를 알려준다.
▷ describe() 지금까지 살펴본 통계값들을 포함해서 기본적인 통계치를 한 번에 확인할 수 있다.
앞에서 살펴보지 않은 것은 사분위수 정도 밖에 없을 것 같다.
사분위수는 나중에 이상치(outlier) 처리할 때 심도있게 살펴보지 않을까 한다.
▷ 집계(aggregate) - agg() 원하는 column의 원하는 통계치만 보고 싶을 때 agg()을 활용할 수 있다.
지정하지 않은 부분은 NaN으로 나온다.
▷ groupby() 공부해보면 사실 별것도 아닌데,
개인적으로 머리에 잘 들어오지 않는 이상한 아이라서 신경이 많이 쓰인다 ㅠㅠ
type 값이 "TV Show"인 row들에 대해서 "release_year" 값의 평균, "duration" 값의 합계를 구하려고 할 때
"groupby() "를 사용하면 손쉽게 할 수 있다.
'type'으로 그룹핑해서 'duration'의 평균을 각각 구하라는 의미이다.
좀 더 복합적인 상황을 살펴보자.
type 값이 'Movie'이고 country 값이 'United States'인 데이터의
'duration' 평균값만 추출하고 싶으면 어떻게 해야할까?!
row를 지칭하는 부분을 주의깊게 살펴보기 바란다.
list 형식이 아니라, 튜플(tuple) 형식으로 사용한다.
⑦ 데이터프레임에 행/열 추가하거나 삭제하기 ▷ 행/열 추가 새로운 row를 하나 추가하는 것을 살펴보자.
일단 Dict 타입으로 추가할 row 데이터를 하나 준비하자.
새로 추가할 index(row) 값을 지정해서 값을 넣어주면 끝이다.
index 값을 가지고 새로운 row를 추가하는 것인데, iloc[]가 아닌 loc[]를 사용하고 있는 것을 조심해야 한다.
iloc[]의 경우에는 기존의 데이터 범주에 대해서만 사용할 수 있기 때문에
새로운 row를 추가하는 것에는 사용할 수 없다.
column을 추가하는 것은 변수값 지정하듯이 사용하면 된다.
▷ 행/열 삭제 - drop() drop()에서 axis 파라미터 값을 이용해 행/열 모두 삭제할 수 있다.
np.arange(2, 5)를 통해서 2부터 4까지의 값을 얻어낼 수 있기 때문에,
2, 3, 4 행이 삭제되었음을 알 수 있다. (axis=0)
이번에는 열(column)을 삭제해보자.
Column 이름을 지정해주고 axis=1 파라미터를 전달해서 column을 삭제했다.
우와 엄청 많은 내용이었다.
힘들다.
그래서 스터디 제출 기간을 살짝 오버했다 (사실 중간에 여행가느라... ㅋㅋㅋ)