자~ 이번에는 "Merge Sort"에 대해서 알아보자.
한글로는 "합병 정렬" 또는 "병합 정렬"이라고 불리운다.
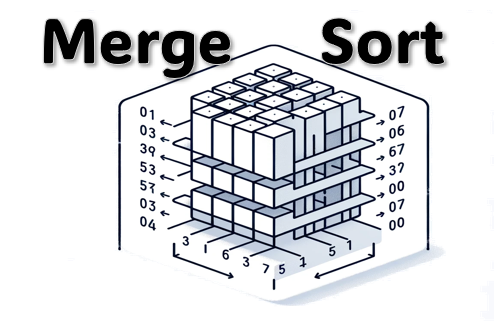
세계의 모든 지식이 들어있다고 해도 과언이 아닌 위키피디아에서는
Animated GIF 이미지로 Merge Sort를 너무나 잘 설명해주고 있다.
이 알고리즘은 그 유명한 "존 폰 노이만(John von Neumann)"님이 1945년에 개발했다고 한다.
우리의 갓 노이만 형님 !!!
위 Animation을 잘 지켜보면 알겠지만,
"Divide-and-Conquer (분할 및 정복)" 알고리즘의 하나이다.
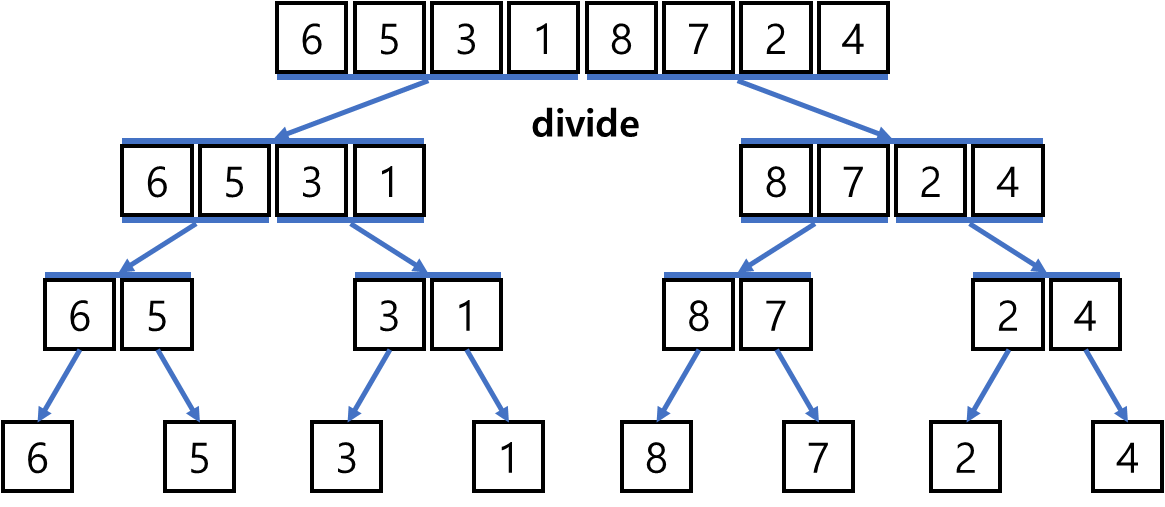
반절씩 잘라서 나누고, 합치면서 정렬을 하는 것이다.

그런데, 실제 구현을 할 때 divide를 하기 위해서
위의 그림에 있는 모든 박스의 갯수만큼 별도의 메모리 공간을 확보해야 할까?
한 번에 모든 메모리 공간을 확보하는 것 보다는
한 단계씩 나눠서 그 때 그 때 필요한 값을 복사해서 사용하는 방식이 훨씬 효율적이고 똑똑한 방법이 되겠다.
무슨 말이냐고!?
한 단계씩 밟아나가보자 !!!

위 그림과 같이 8개의 입력이 있다고 해보자.
인덱스(index)값의 의미로 "[ ]"로 묶은 형태로 표기해보았다.
우리의 명령(입력)은 다음과 같다.
"1번부터 8번까지의 인덱스를 갖고 있는 입력값을 merge sort 해줘 !!!"
이것을 1-depth 더 들어가서 살펴보면 다음과 같다.
"1번부터 4번까지의 값을 merge sort하고
5번부터 8번까지의 값을 merge sort한 다음에
그 2개의 결과를 merge 해줘"
어!? 여기에서 조금 애매한 표현이 등장했다. merge ???
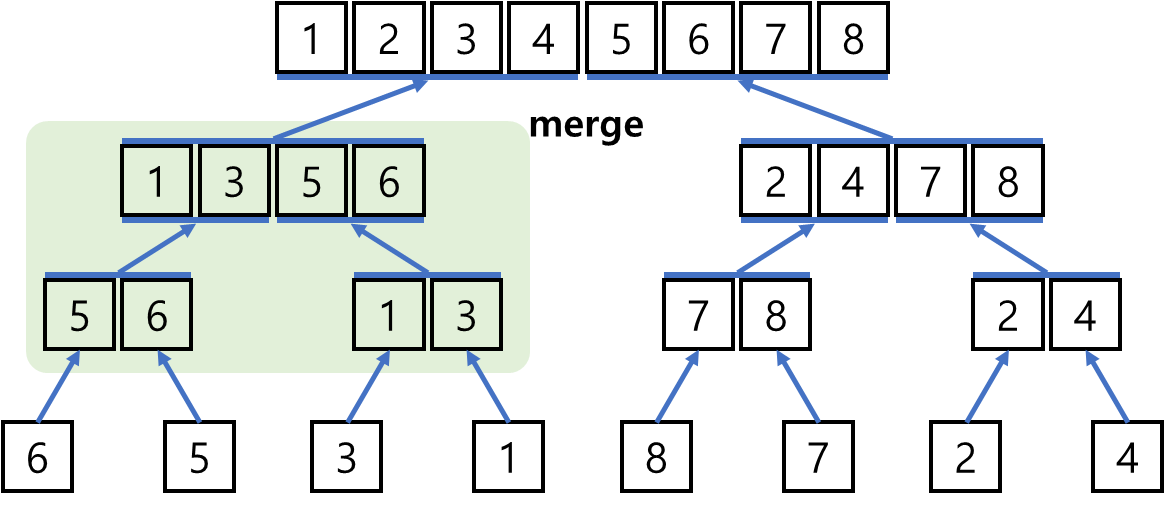
[5, 6] 과 [1, 3]을 merge 하는 과정을 보면 그냥 합치는 것이 아니라
크기를 비교해서 작은 것부터 차례대로 하나씩 넣어가는 과정이다.
그리고 여기에서 주의해야할 사항이 하나 더 있다.
[5, 6] 과 [1, 3]을 merge 할 수 있는 것은 [5, 6] 과 [1, 3]이 각각 이미 sort가 되어있기 때문이다.
그림으로 살펴보자.

[2, 4, 1, 3]이라는 값을 merge 한다고 하면
반절 크기의 2개의 메모리 공간을 잡아놓고, 거기로 값들을 복사한다.

그리고 2개 메모리 공간의 앞 부분의 값을 비교해서
작은 값 순서대로 하나씩 복사해 넣는 과정으로 정렬이 된 값으로 merge가 된다.
Pseudo Code는 다음과 같다.
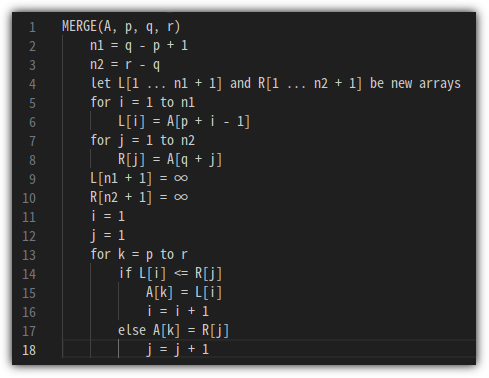
p, q, r 값의 정체는 다음과 같다.

merge 작업을 할 시작 위치(p), 끝 위치(r), 그리고 divide를 할 중간값(q)이다.
그러면 pseudo code를 진행하면서 정해지는 값/상태들을 확인해보자.
쪼갠 값들을 저장할 메모리 공간의 크기를 계산하기 위한 n1, n2 값을 계산한다.
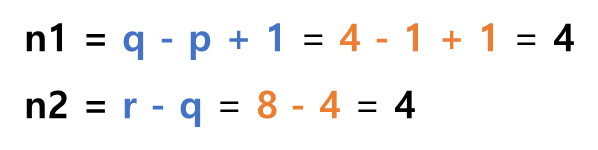
divide한 값을 저장할 2개의 메모리 공간을 생성한다.

응?! 4개가 아니라 5개씩 공간을 준비하네?!
그 다음 pseudo code들을 진행해보면 이유를 알겠지.
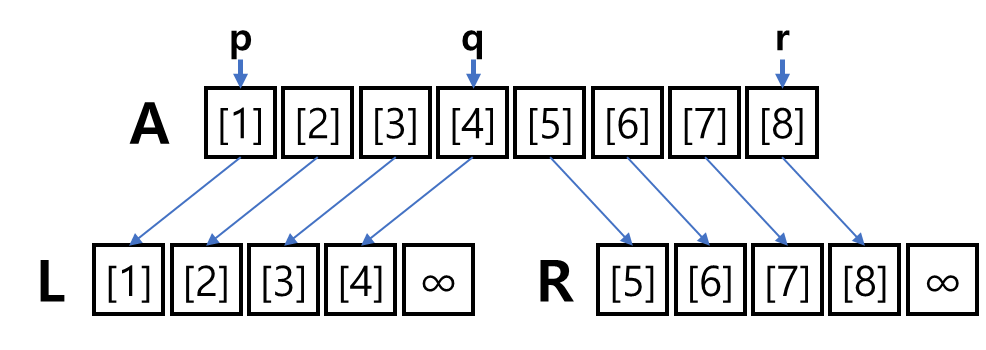
이제 모든 준비는 끝났다.
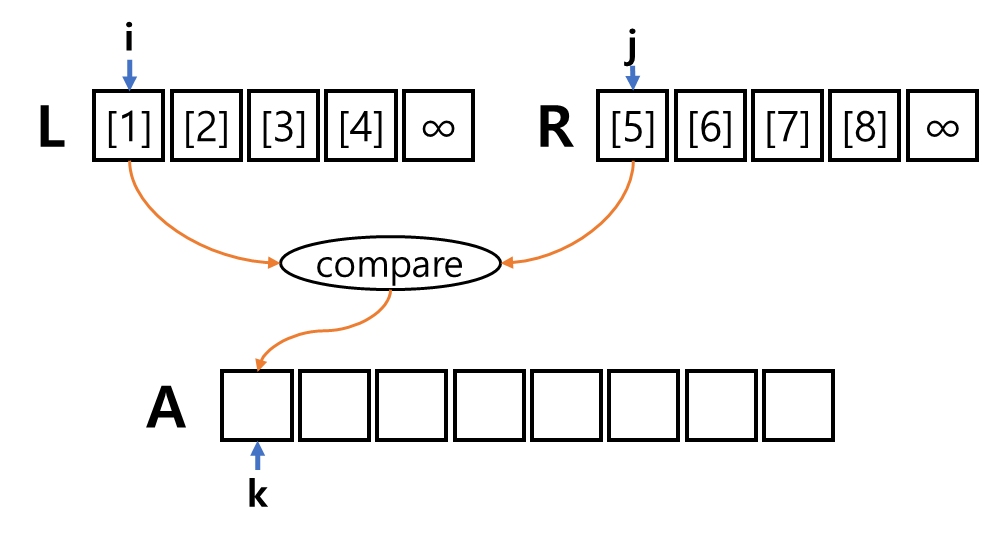
여기까지 해서 merge 과정에 대해서 살펴봤다.
이제, 전체적으로 merge sort 하기 위한 pseudo code를 알아보자.
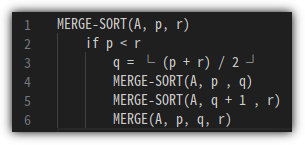
3번 라인은 본래 아래와 같은 notation이다.
Editor에서 사용 가능한 기호 중에서 마땅한 것을 찾지 못해서 ^^
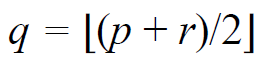
2로 나눈 결과의 소숫점 버림값을 취하겠다는 의미이다.
지금까지 살펴본 내용을 기반으로 Python으로 구현해보면 다음과 같다.
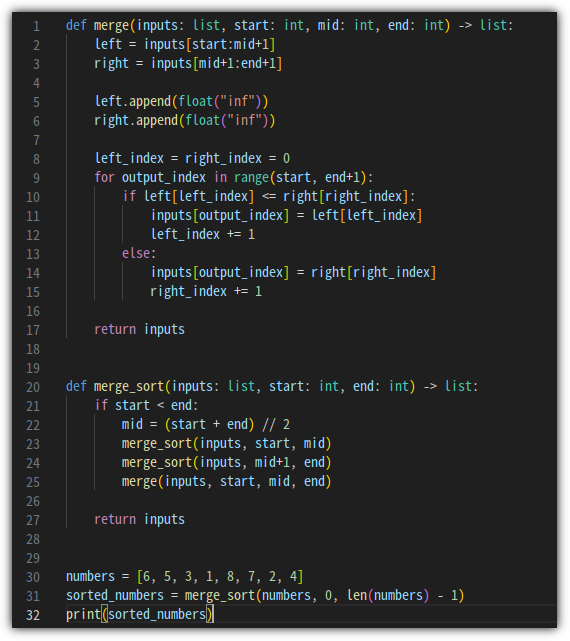
Merge Sort를 어떻게 하는 것인지에 대해서는 이제 다 알아봤다.
남은 것은 Performance 측정이다.
먼저, Merge 과정에 소요되는 시간을 계산해보자.
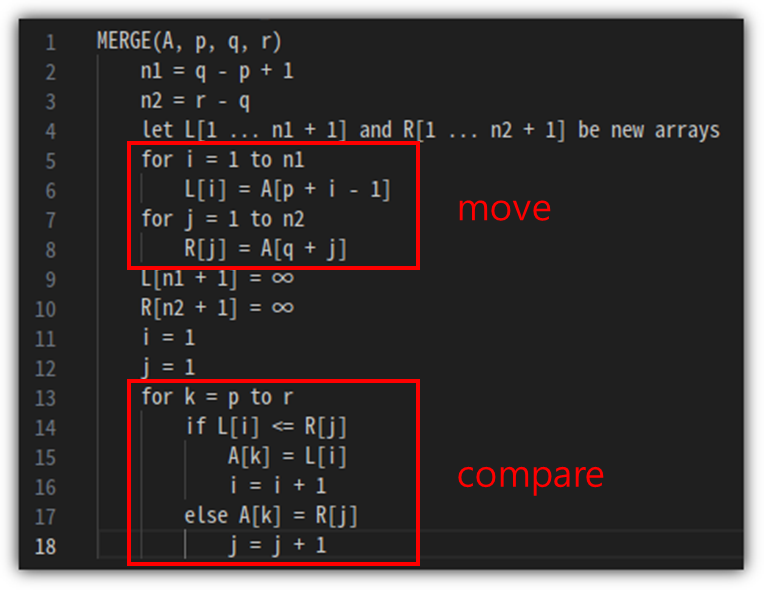
위 그림에서 보이는 것 처럼
핵심적인 부분은 move와 comapre로 구성되어 있다.
move는 "n1 + n2" 횟수만큼 실행이 되고
compare는 "n1 + n2" 보다 작거나 같은 횟수만큼 실행이 될 것이다.
그렇기 때문에, 전체적으로 2 * (n1 + n2) 횟수보다 같거나 적은 횟수만큼 실행이 된다고 봐도 무방할 것이다.
Merge = Θ(n1 + n2)
그러면, 전체 Merge Sort의 소요 시간은 얼마나 될까!?

MERGE-SORT(A, p, r) 의 소요 시간을 T(n) 이라고 하면,
3번째 라인과 4번째 라인은 n의 이등분된 값을 갖게 되므로 T(n/2) 값을 갖는다고 할 수 있다.
5번째 라인은 바로 앞에서 살펴본 내용에서 n1 + n2 = n 이므로 Θ(n) 값으로 표현해볼 수 있다.
여기에서 생각해볼 것은 1번 라인이 비교문이라는 것이다.
비교문을 통과하지 못하는 경우를 생각해보면, p < r을 만족하지 못하는 경우는 n=1 일 경우일 것이다.
그래서 점화식으로 표현해보면 다음과 같다.
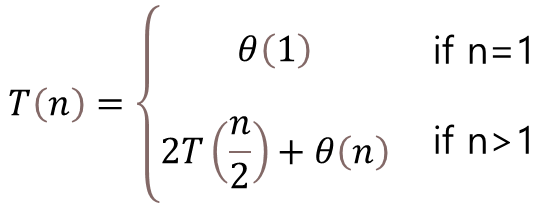
이와 같은 경우는 'Recursion Tree Method(재귀 트리 방법)'을 통해 풀어낼 수 있는데,
중간 과정은 생략하고.... 그래서 계산한 결과는 다음과 같이 정리된다.
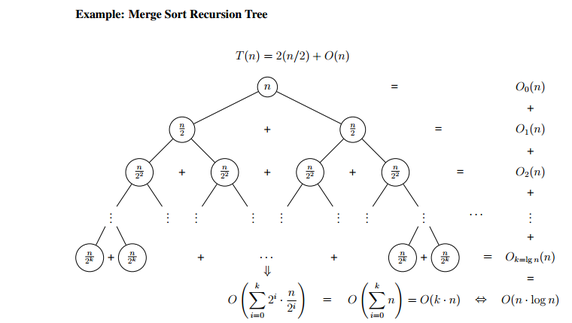
위의 이미지에서는 Big-O로 표기되었지만, Big-Theta로 할 수 있다.
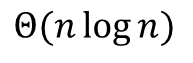
그러면 메모리 공간은 얼마나 사용할까?
"n"개 만큼 더 필요로 한다.
최대 n개 공간이 있으면 그것을 이용해서 모두 계산 가능하다.
'Programming > Algorithm' 카테고리의 다른 글
| 알고리즘 #1 - 정렬 문제 #5 - Quick Sort #1 (0) | 2024.02.06 |
|---|---|
| 알고리즘 #1 - 정렬 문제 #4 - Heap Sort #1 (0) | 2024.01.20 |
| 알고리즘 #1 - 정렬 문제 #2 - Growth of Functions (0) | 2023.12.25 |
| 알고리즘 #1 - 정렬 문제 #1 - Insertion Sort #2 (0) | 2023.12.10 |
| 알고리즘 #1 - 정렬 문제 #1 - Insertion Sort #1 (0) | 2023.11.27 |