▶ ChatGPT

국제학술지 '네이처(Nature)'에서 올 한 해 과학계에 큰 화제를 불러일으킨 10명의 인물을 선정하는 '네이처 10(Nature's 10)'을 발표했는데, 역대 최초로 인간이 아닌 생성형 인공지능(AI) 챗봇 '챗GPT(ChatGPT)'를 포함시켰다.
ChatGPT라고는 하지만, 크게 바라보면 '생성형 인공지능' 자체가 우리 생활에 정말 큰 영향을 미치게 된 것이다.
지금은 시작일 것이다. 앞으로는 정말 생활 이곳 저곳에서 우리와 함께하게 될 것이다.
▶ RAG
ChatGPT는 정말 대단한 기능 및 성능을 보여주고 있지만, 한계점도 분명히 있다.
일단 ChatGPT가 이것 저것 골고루 많이 아는 똑똑한 아이이긴 하지만,
특정 분야에 대해서 전문적인 지식을 갖고 있다고 하기에는 조금 부족하다.
그리고 최신 정보를 알지 못한다는 점도 있고 장기 기억을 유지하기에 어렵다는 점도 있고,
할루시네이션(Hallucination)과 같은 문제도 있는 등
ChatGPT는 여러가지 한계점이 분명히 있고 이러한 한계점을 다양한 방법으로 해결하고자 발전하고 있다.
이러한 ChatGPT의 한계점을 극복하는 방법 중 하나로
RAG(Retrieval-Augmented Generation, 검색 증강 생성)이라는 것이 최근 엄청난 화두가 되고 있다.

위 그림에서 오른쪽 위를 잘 살펴보기 바란다.
'Knowledge Source'를 별도로 구성하고 이를 일종의 보조 기억장치처럼 사용하는 것이다.
어?! 뭔가 떠오르지 않는가!?
그렇다!!! 바로 "데이터베이스(Database)"이다.
▶ Embedding
ChatGPT의 경우 기본적으로 사용되는 데이터는 '자연어(Natural Language)'이다.
이러한 자연어를 문자 그대로 사용한다고 하면 그 안에 담겨있는 의미나 가치를 다루기가 어렵기 때문에
단어 또는 문장들을 다른 방식으로 표현을 해야하는데
현재 가장 보편적인 표현 방식이 바로 'Vector Embedding'이다.

Vector 형식으로 데이터가 저장이 되기 때문에
Vector 연산을 통해 검색을 한다거나 "king + queen = princess or prince"와 같은 연산도 가능하게 된다.
이제 이렇게 임베딩된 데이터들을 데이터베이스에 저장해놓고 쿼리를 해서 사용을 하면 되는데,
PostgreSQL이나 MySQL과 같은 기존 RDB를 이용하기에는 좀 어려움과 불편함이 한 가득이다.
▶ Vector Database
그렇다. 말 그대로 Vector 데이터들을 저장하고 제공하는데에 특화된 데이터베이스이다.
예전에도 있었던 데이터베이스 유형이지만, 최근 AI 시대가 되면서 엄청난 대박이 났다.
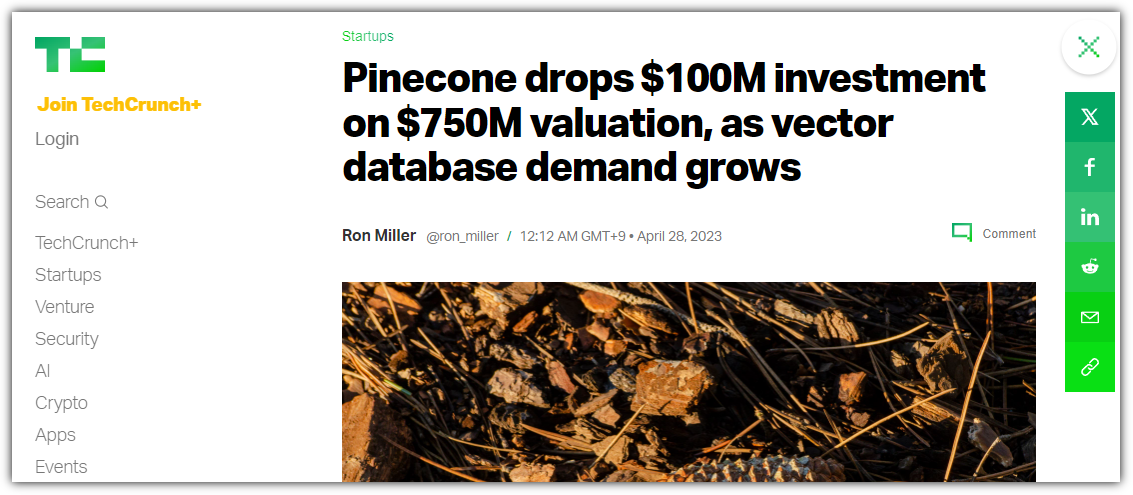
2021년도에 출시된 Pinecone은 1억 달러 규모의 시리즈 B 투자를 받았다고 한다. 기업 가치는 무려 7억 5천만 달러.
그 외에도 Weaviate, Chroma, Qdrant 等 다양한 Vector Database들이 모두 다 많은 투자를 받았다.
이렇게 돈이 쏠린다는 것은 이 분야에 대해서 많은 분들이 성공할거라 믿는다라는 의미일 것이고
그렇다면 우리는 이 부분에 대해서 공부해볼 가치가 충분히 있다!!!
▶ Pinecone
최근 가장 많은 인기를 얻고 있는(돈을 투자 받은?!) Pinecone에 대해서 알아보자.
비용은 어떻게 될까!? (너무 돈! 돈! 하는 것 같아서 조금 그렇지만... 현실이... ^^)

비용 부분을 살펴보면서 눈치 챘어야 한다.
그렇다! Pinecone은 On-Premise 형태로 제공되지 않는다. 무조건 SaaS 이다!
그나마 다행인 것은 Free 제공 부분이 있다는 점! ^^

Sign-Up은 편하게 되어있다.
무료 요금제에서는 Index 1개를 사용할 수 있다.
기존 RDB에서 table 정도로 생각하면 될 것 같다.

Python을 이용해서 접근하기 위해서는 API Key 값을 알아야 한다.
왼쪽 메뉴탭에서 'API Keys'를 눌러보면 하나 이미 만들어진 것을 확인할 수 있다.
▶ Hello-whatwant
이제 Pinecone을 사용해보자.
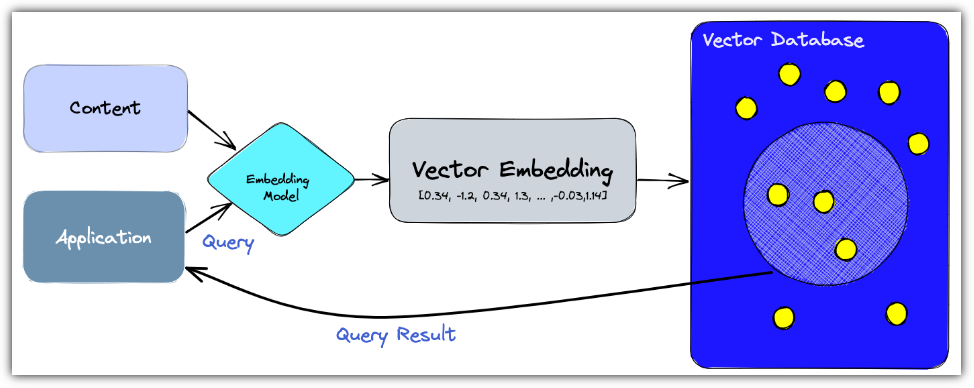
Knowledge를 임베딩해서 저장을 하고,
질문을 다시 임베딩해서 쿼리를 던지면 그와 유사도가 높은 것들을 답해주는 과정을 해보고자 한다.
기본적인 간단한 workflow이지만, 그래도 다음의 두 가지 사항은 미리 확인/준비 해야 한다.
① Python에서 Pinecone을 사용하기 위한 방법
② Embedding Model 선정 및 사용 방법
① Python에서 Pinecone을 사용하기 위한 방법
- 앞에서 이미 Pinecone API Key 및 Env 값은 확보(?)했으니 이 부분은 Pass
- 그리고, 친절하게도 Pinecone 라이브러리를 제공해주니 이를 사용하면 OK
. https://docs.pinecone.io/docs/quickstart
| > pip install pinecone-client |
② Embedding Model 선정 및 사용 방법
- 이 부분은 정해진 것이 없기에 필요에 따라 각자의 취향/상황에 맞춰서 하면 된다.
. 지금은 보통 적은 리소스로 괜찮은 성능을 보여준다고 하는 all-MiniLM-L6-v2 모델을 사용해보겠다.

이제 코드로 풀어보자.
설명을 위해 Colab 환경에서 진행한 내용으로 진행하겠다.
- https://colab.research.google.com/
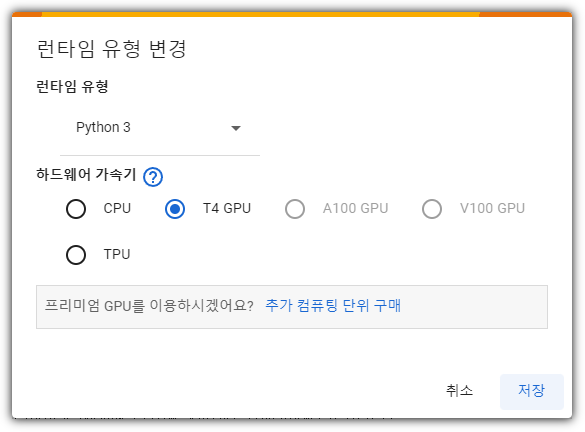
CPU 환경에서도 실행 가능하긴 하지만, 이왕이면 GPU 환경이 빠르니... 선택하자.
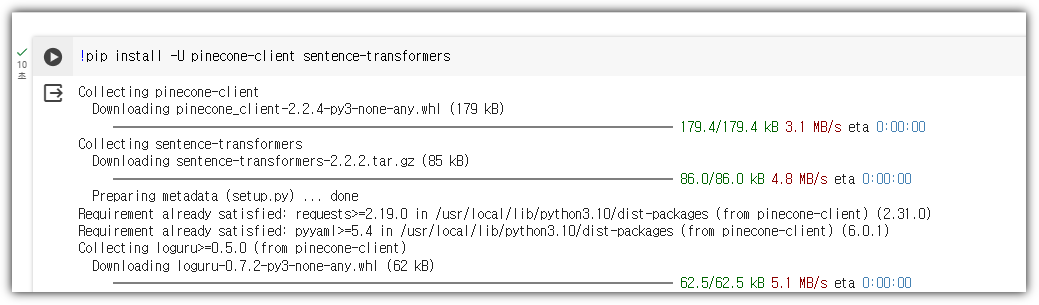
pinecone-client, sentence-transformer 2개의 패키지 설치가 필요하다.
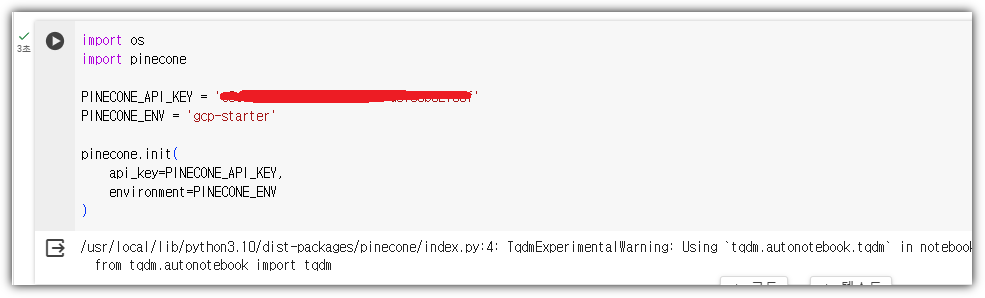
앞에서 확인한 pinecone API key 값 및 Env 값을 넣어주면 된다.
warning은 가뿐히 무시하자 ^^

굳이 torch를 import까지 할 것은 아닌 것 같아서 주석처리했고 ^^
all-MiniLM-L6-v2 모델을 불러왔는데, 출력된 내역을 보면 간단하게나마 spec을 확인할 수 있다.
잠시 현재 Pinecone의 Index 상태를 살펴보자면 다음과 같이 아무 것도 없다.
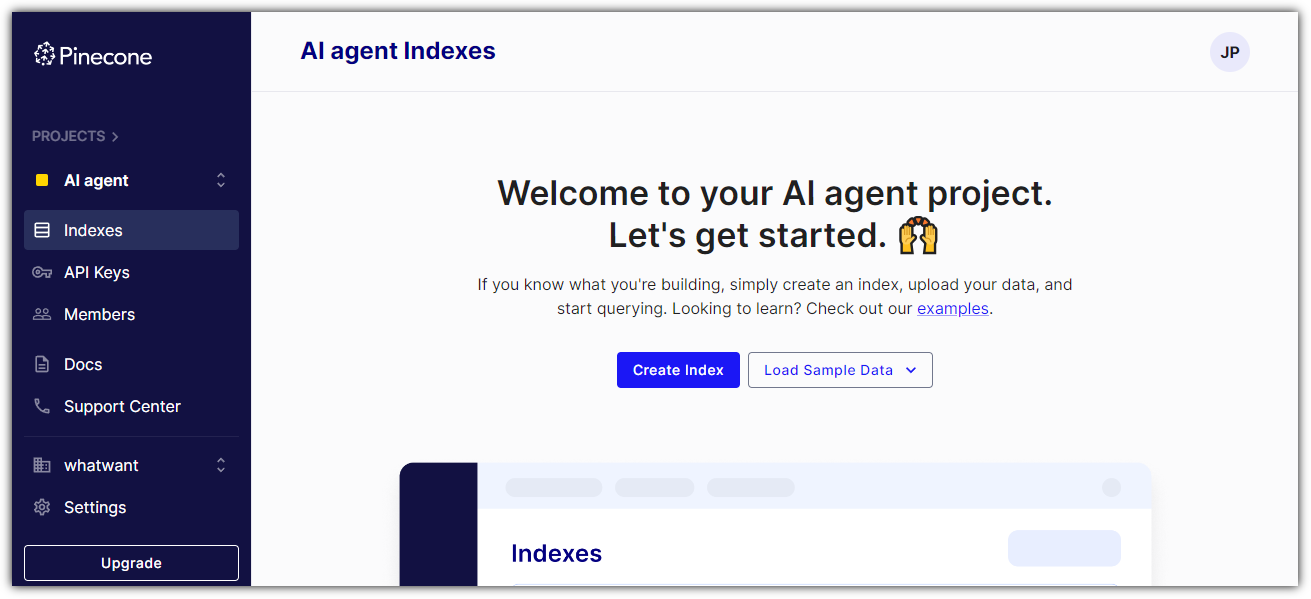
그러면, 우리는 Index를 하나 만들어보자.

이렇게 만들면 Pinecone에서는 다음과 같이 결과가 보인다.

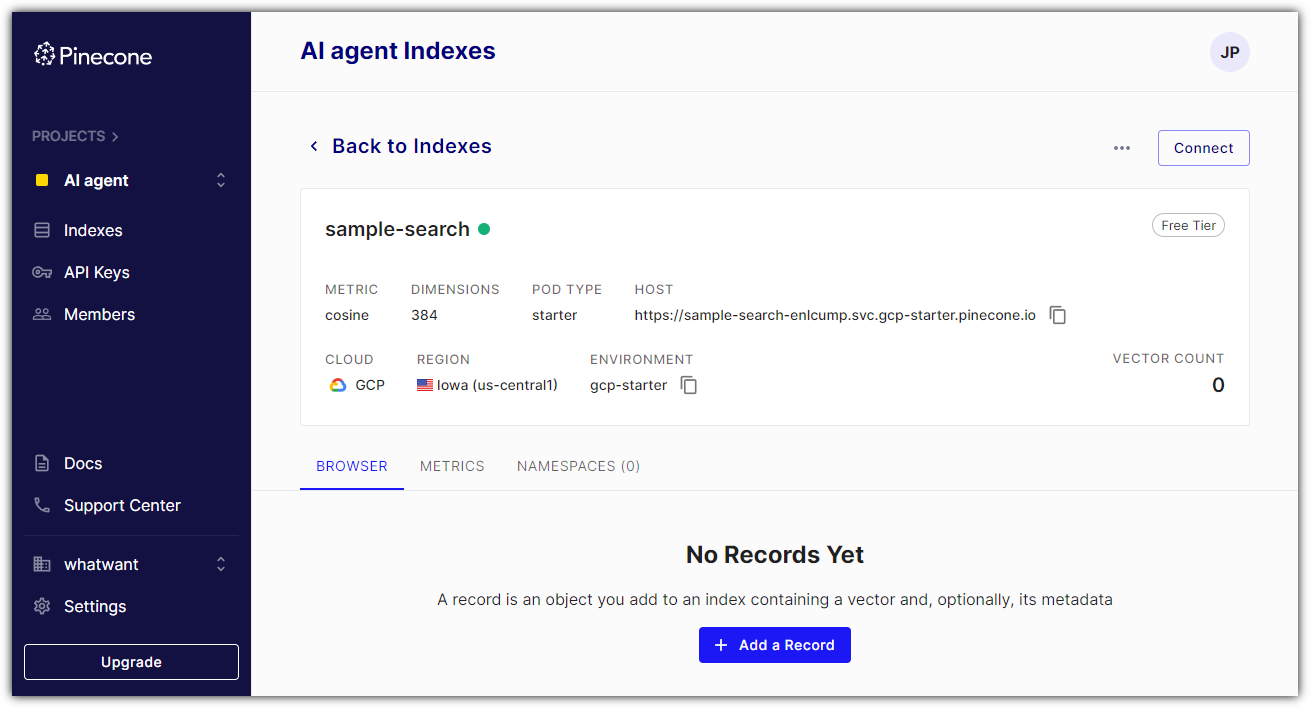
내용물을 살펴보면 다음과 같이 아무 것도 없다 ^^
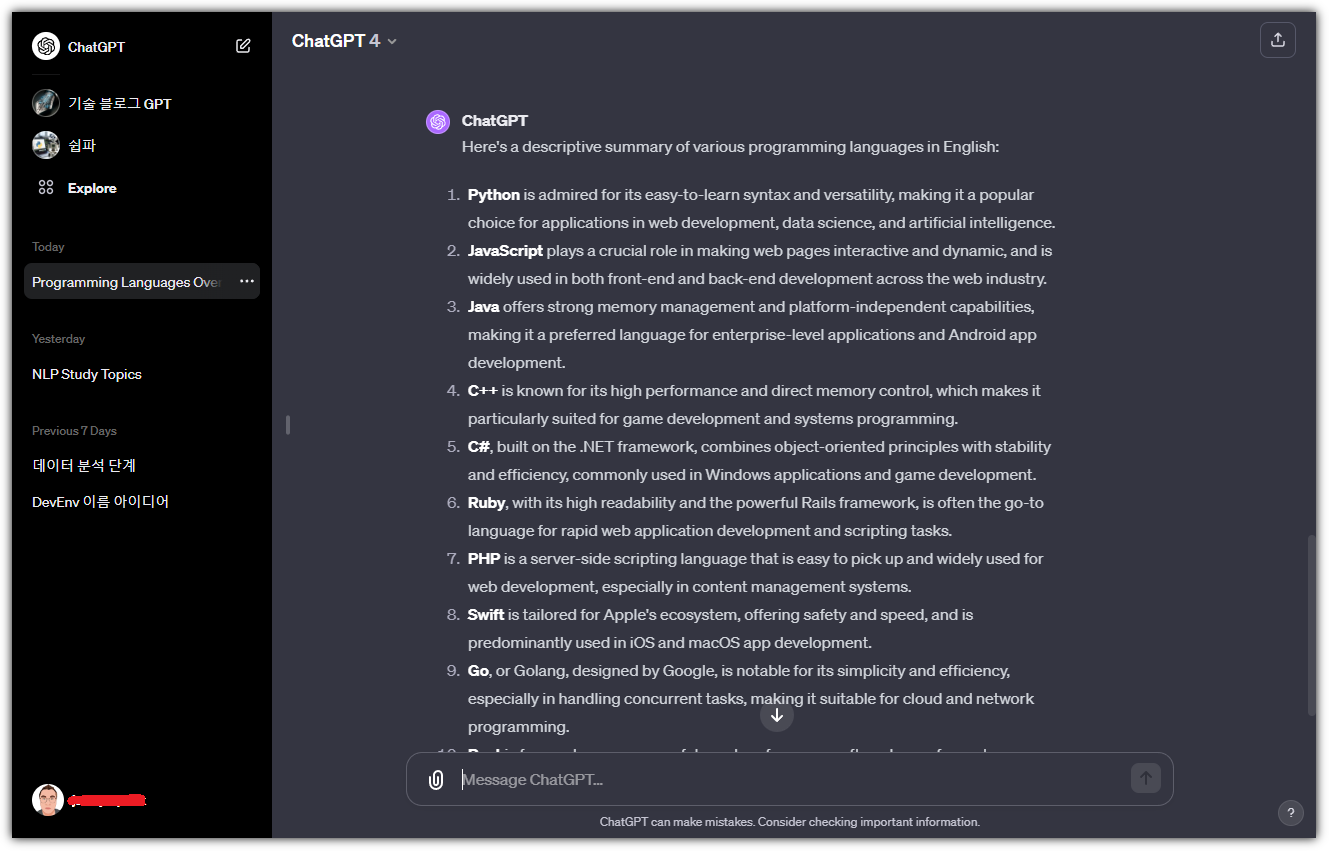
테스트하기 위해 넣어줄 데이터는 ChatGPT로 만들어봤다.
프로그래밍 언어를 한 문장으로 정리해달라고 했다.
입력을 열심히 해주면 된다.

그 다음에는 Pinecone으로 넣어줄 형태로 변환을 해야 한다.
'일련번호, 임베딩된 내용, 원본 내용'의 조합으로 생각하면 된다.

준비가 되었으면 upsert 해주면 된다.
upsert가 뭐냐고? update or insert !!!

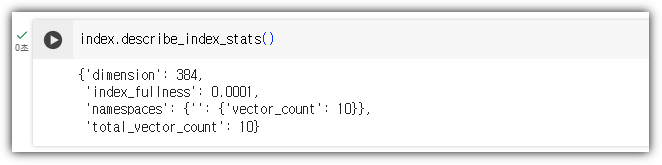
Pinecone에서 확인해보자.
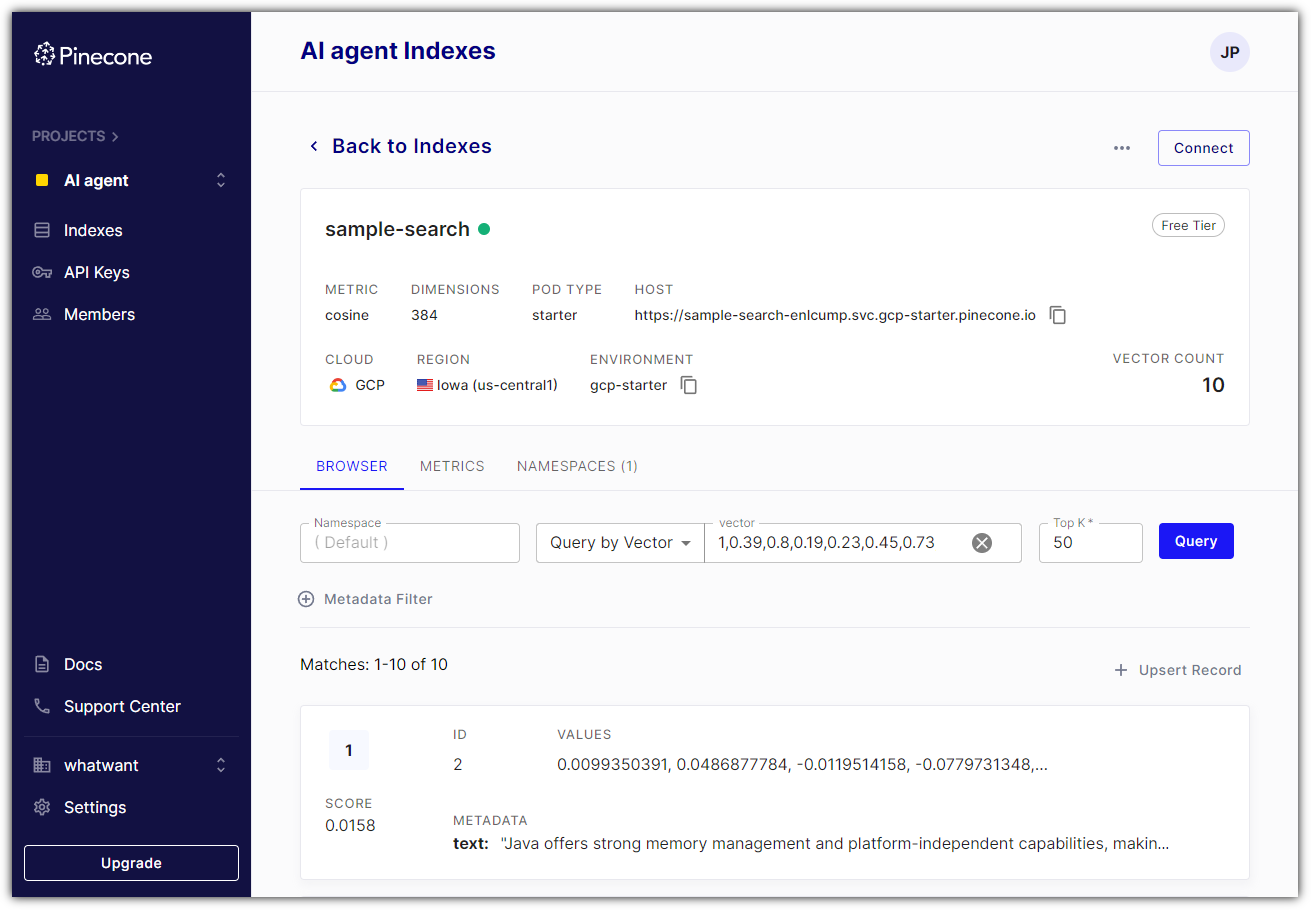
Pinecone의 상태를 직접 확인해볼 수도 있다.
query를 요청할 용도의 function을 하나 만들어 보자.

이제 질문을 해보자.

잘 나온다 !!!
다른 식으로 질문을 해볼까?

잘 찾아준다 !!!
여기까지~~~~ ^^
'Dev Tools > Database' 카테고리의 다른 글
| SQLite 활용하는 예시 (with Python) (1) | 2024.11.25 |
|---|---|
| SQLite에 대해서 알아보자 (4) | 2024.09.01 |
| Redis 맛보기 (Docker로 Redis 설치해보기) (0) | 2022.07.10 |
| PostgreSQL 계정 및 권한 관리 (0) | 2022.03.23 |
| pgAdmin4를 Docker로 설치하자 (PostgreSQL Tools) (0) | 2022.03.21 |