
드디어 마지막 챕터까지 왔다.
힘들었지만, 그래도 주말마다 꼬박 꼬박 해냈다.
07장 의료 데이터 분석 프로젝트

앞서 했던 "넷플릭스 데이터 분석 프로젝트"와 유사한 방식으로 진행하면 될 것 같다.
① 의료 데이터 분석 프로젝트 소개
② 의료 데이터셋 파악하기
③ 심부전 데이터셋 필터링하기
④ 심부전 데이터셋 결측치 처리하기
⑤ 심부전 데이터셋 통계 처리하기
⑥ 심부전 데이터셋 시각화하기
① 의료 데이터 분석 프로젝트 소개
앞서 진행한 넷플릭스 데이터 분석과 대부분 유사하게 진행되고
차이가 있다면 "logical indexing" 부분에 조금 더 중심을 두고 진행하는 것이라고 한다.
② 의료 데이터셋 파악하기
교재에서는 자세한 설명이 없었지만, 찾아보니 아래 데이터인 것 같다.
- https://www.kaggle.com/datasets/fedesoriano/heart-failure-prediction
직접 다운로드 받아보자.
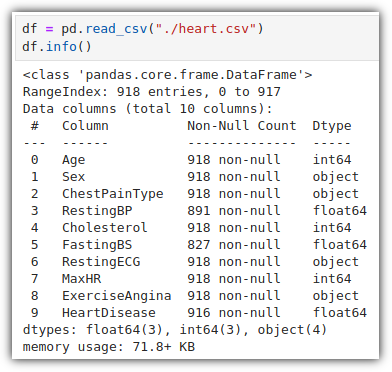
다운로드 받은 CSV 파일을 데이터프레임으로 읽어오자.
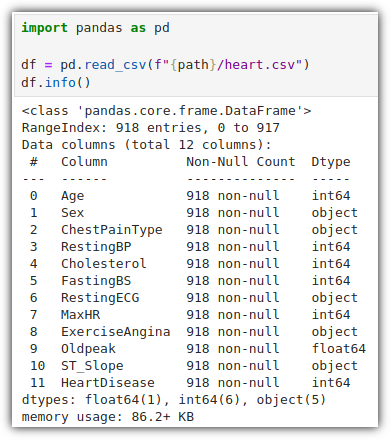
샘플 데이터를 살펴보자.

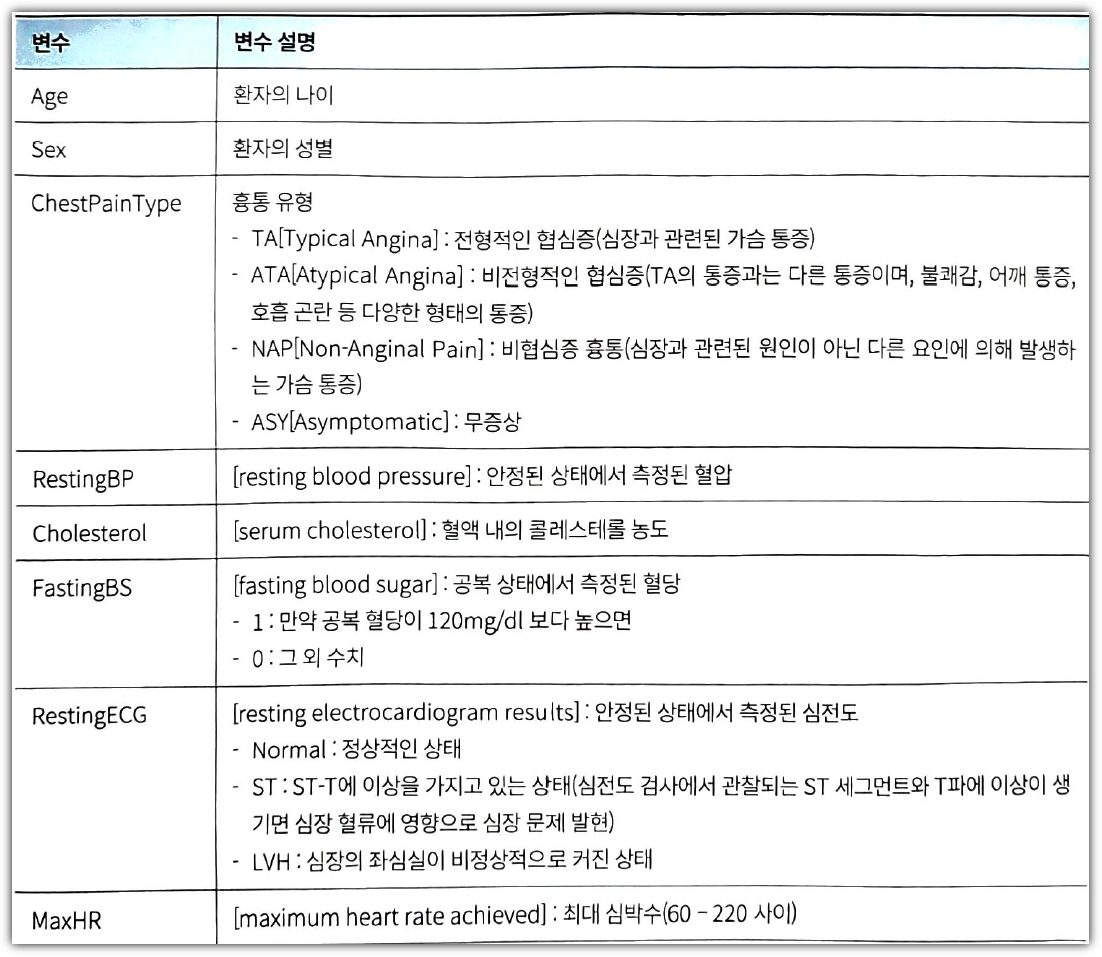
각 columns 의미는 다음과 같다.

그런데, 교재의 데이터와는 좀 차이가 있는 것 같다.
교재에서 제공하는 데이터를 보면 일부 column에서 결측치 값이 보이는데,
Kaggle에서 내려받은 데이터에서는 결측치 값이 안보인다.
아쉽지만, 교재에서 제공받은 파일을 업로드해서 사용해야겠다.
③ 심부전 데이터셋 필터링하기
심장병 여부를 나타내는 'HeartDisease' 컬럼 데이터를 살펴보자.
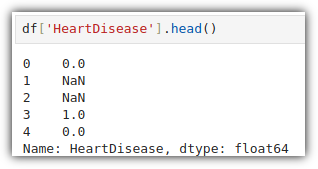
결측치 값도 보이고, 0.0/1.0 데이터도 보인다.
값이 '1.0'인 데이터를 True (심장병 맞음) 로 판단하면 된다.
간단히 실습해보자.

④ 심부전 데이터셋 결측치 처리하기
결측치 값들이 얼마나 되는지 살펴보자.
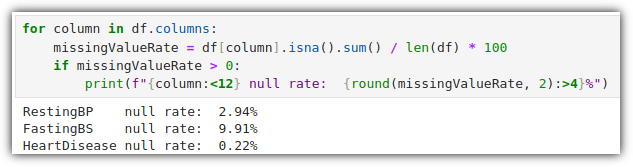
그다지 큰 비율은 아니지만, 그래도 처리를 해줘야 한다.
책의 저자와는 다른 개인적인 취향으로 별도의 데이터프레임을 만들어서 작업을 진행했다.

앞서 해봤던 넷플릭스 데이터 분석과 거의 유사한 과정이다.
이렇게 진행한 결과는 다음과 같다.

⑤ 심부전 데이터셋 통계 처리하기
데이터프레임에서는 여러 통계량을 손쉽게 구할 수 있도록 다양한 함수를 제공해준다.
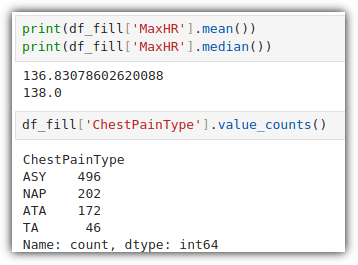
groupby()를 이용해서 그룹별 통계값들을 구할 수도 있다.

⑥ 심부전 데이터셋 시각화하기
여기에서 사용할 팔레트를 설정해보자.

흉통 유형을 카테고리화 한 다음 개수를 세고, 이를 파이 차트로 표현해보자.
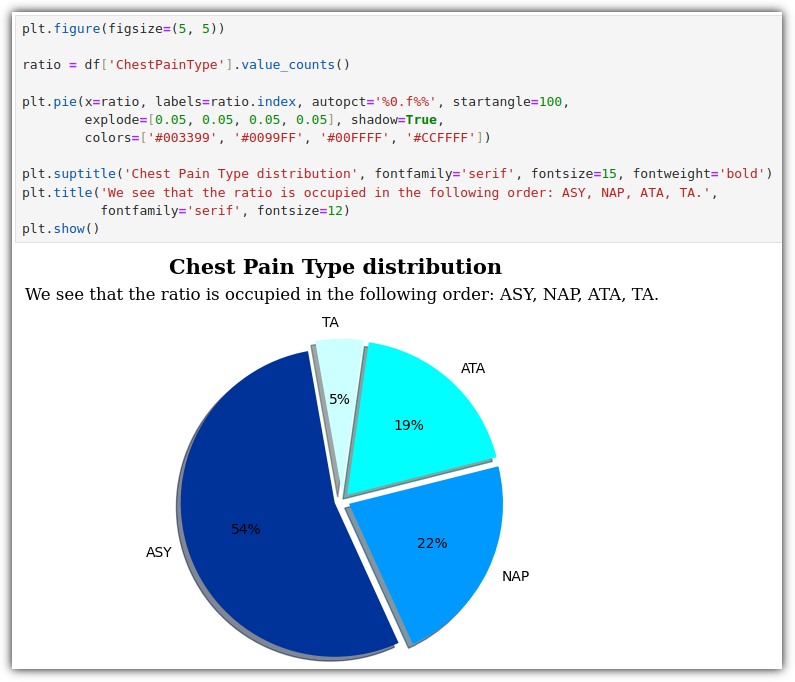
심부전 빈도 그래프를 그려보자.
심부전증이 있을 때와 없을 때 ASY(무증상)가 압도적인지 살펴보기 바란다.


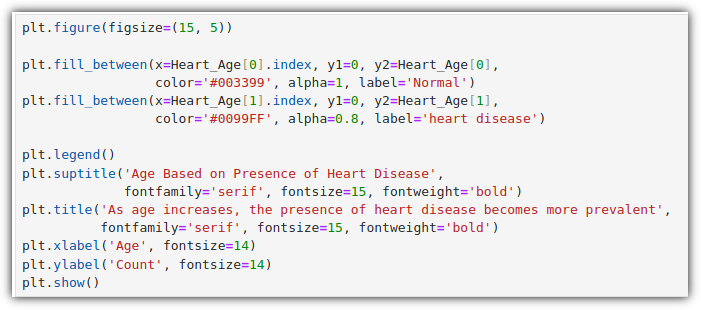
나이에 따른 HeartDisease 데이터를 한 번 살펴보자
이렇게 구한 값을 가지고 나이에 따른 심부전 여부를 살펴볼 수 있는 그래프를 그려보자.

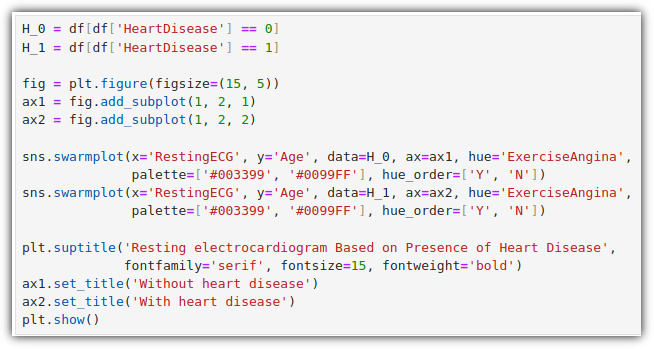
심부전 범주형 산점도 그래프를 그려보자.

워드 클라우드도 하나 만들어보자.

예쁘게 하트 모양으로 그려졌다.

여기까지 해서 책을 한 번 살펴봤다.
추후 한 번 다시 복습하면서 곱씹어봐야겠다 ^^
'Books' 카테고리의 다른 글
| [파이썬 데이터 분석가 되기] 08 - Homework (0) | 2025.03.10 |
|---|---|
| [한빛미디어] 밑바닥부터 시작하는 딥러닝 1 (Deel Learning from Scratch 1) - 리마스터판 (1) | 2025.02.27 |
| [파이썬 데이터 분석가 되기] 06 - PRJ: Netflix (0) | 2025.02.23 |
| [파이썬 데이터 분석가 되기] 05 - BeautifulSoup (0) | 2025.02.16 |
| [파이썬 데이터 분석가 되기] 04 - Seaborn (0) | 2025.02.08 |