"한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다."

그렇지 않아도 최근에 LLM과 연관된 스터디를 하고 있던 중에 만나게 된 반가운 책
"NLP와 LLM 실전가이드"

원서의 제목은 "Mastering NLP from Foundations to LLMs"인데,
한글로 번역하자면... '기초부터 LLM까지, 자연어 처리 완전 정복!' 정도로 될 것 같다 ^^
여기서 또 하나 주목해야할 이름이 보인다. "박조은"
데이터분석, Kaggle, Python 같은 것들을 공부하신 분들이라면 한 번쯤은 들어보셨을 이름 ^^
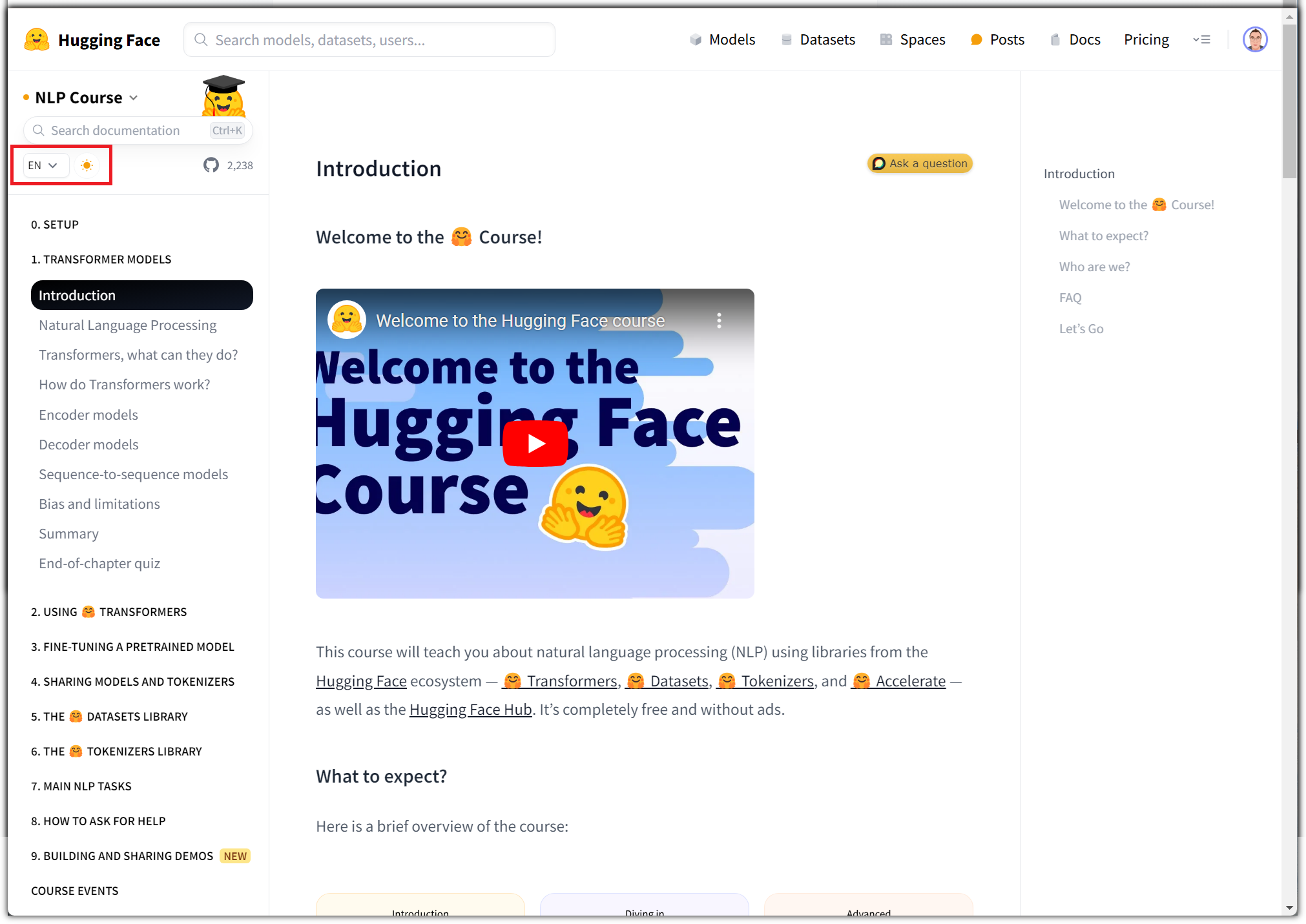
그래서인지 아래와 같이 동영상 강의도 유튜브로 계속 올려주고 계신다. 와우~
그리고, 실습을 위한 노트북 파일도 새롭게 손봐서 따로 올려주셨다.
- https://github.com/corazzon/Mastering-NLP-from-Foundations-to-LLMs
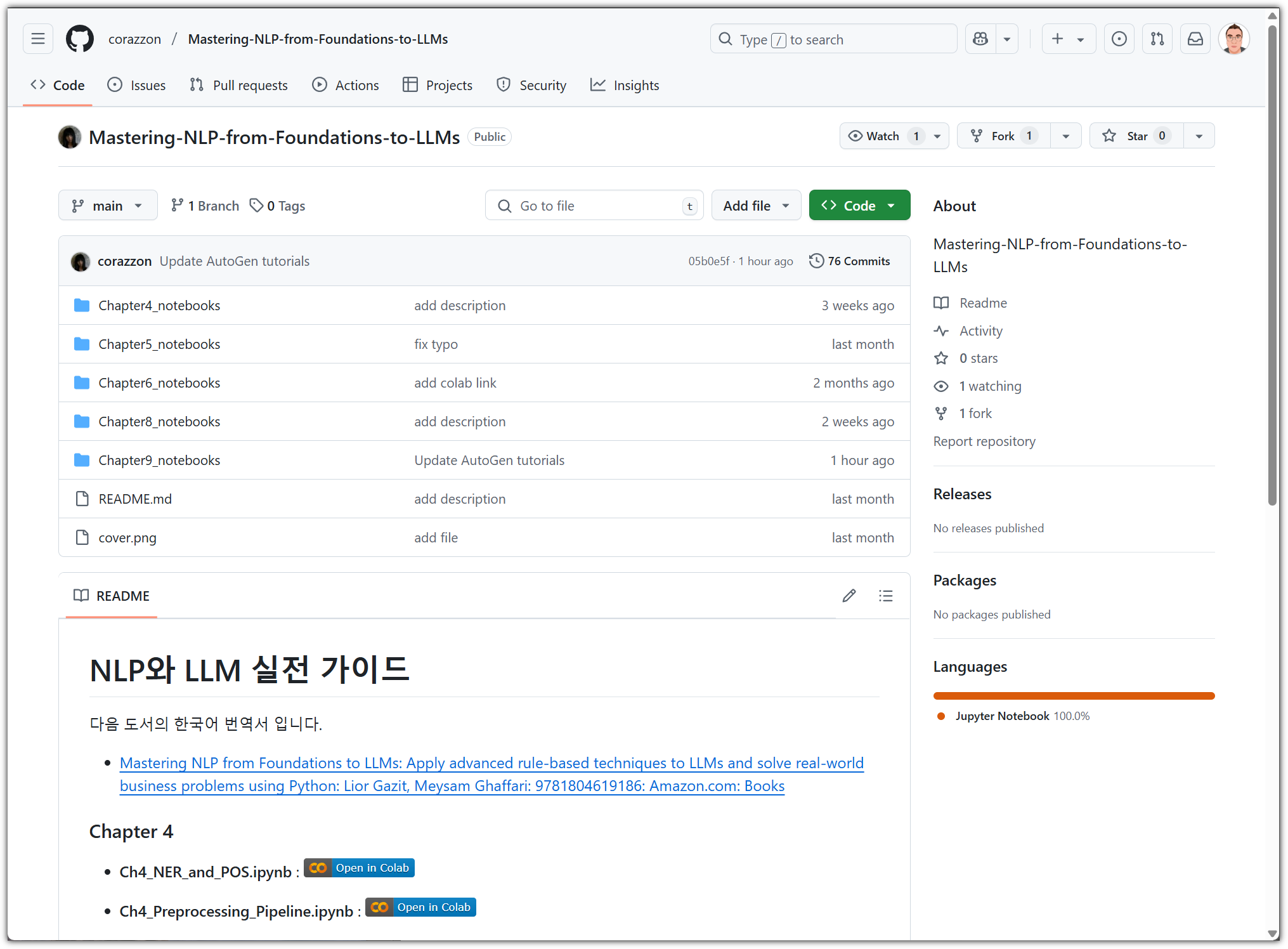
원래 제공하는 실습 파일과 비교해보는 것도 재미(?)가 있을 수 있다.
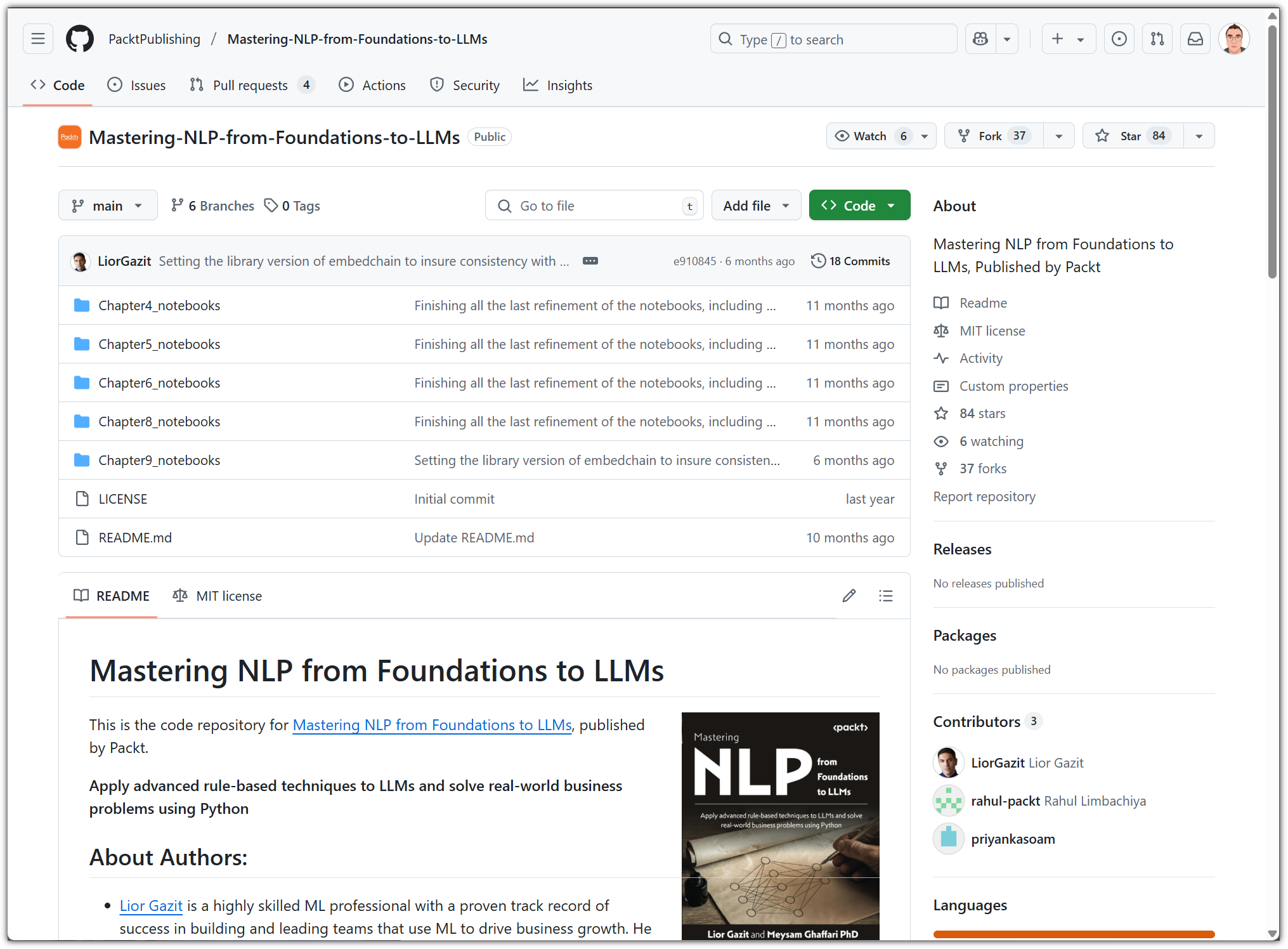
위에서 볼 수 있는 원서의 표지 그림을 보면 알겠지만
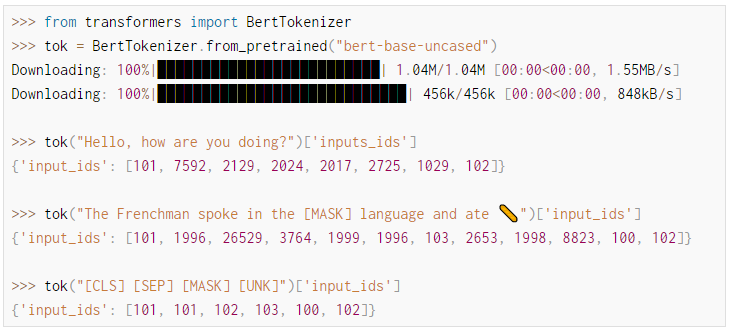
이 책의 본질은 NLP(자연어 처리) 책이다.
그 기반이 되는 수학적인 요소들을 포함해 LLM까지 언급하고 있는 것이다.

책에서는 "대상 독자"를 아래와 같이 말하고 있다.

내가 생각했을 때에는 "NLP(자연어 처리)와 관련된 전체적인 내용을 훑어보고 싶은 사람"이라고 말해야 하지 않나 싶다.
이 책의 목차는 다음과 같다.
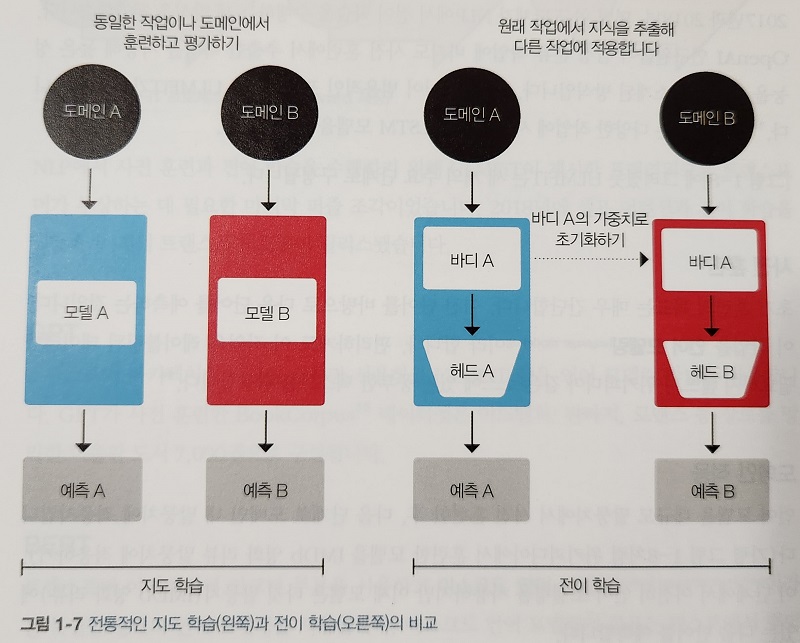
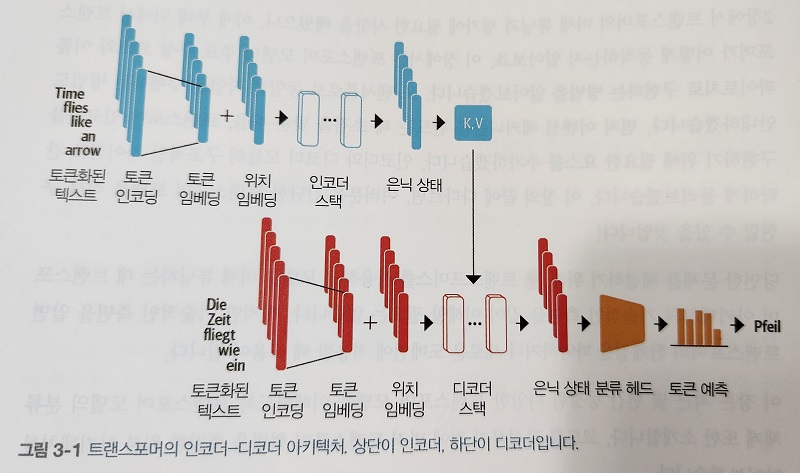
CHAPTER 1 자연어 처리 개요 살펴보기
CHAPTER 2 머신러닝과 자연어 처리를 위한 선형대수, 확률, 통계 마스터하기
CHAPTER 3 자연어 처리에서 머신러닝 잠재력 발휘하기
CHAPTER 4 자연어 처리 성능을 위한 텍스트 전처리 과정 최적화
CHAPTER 5 텍스트 분류 강화: 전통적인 머신러닝 기법 활용하기
CHAPTER 6 텍스트 분류의 재해석: 딥러닝 언어 모델 깊게 탐구하기
CHAPTER 7 대규모 언어 모델 이해하기
CHAPTER 8 대규모 언어 모델의 잠재력을 끌어내는 RAG 활용 방법
CHAPTER 9 대규모 언어 모델이 주도하는 고급 응용 프로그램 및 혁신의 최전선
CHAPTER 10 대규모 언어 모델과 인공지능이 주도하는 과거, 현재, 미래 트렌드 분석
CHAPTER 11 세계적 전문가들이 바라본 산업의 현재와 미래
전체 목차와 함께 이 책의 쪽수 424쪽인 것을 보면 알겠지만
"기초 수학부터 실전 AI 문제 해결까지" 살펴볼 수 있는 책인 것은 맞지만
깊이 있게까지 살펴보려면 다른 자료들을 더 많이 찾아봐야할 것이다.
기초 수학부터 언급한다고 하여 좋아할 사람도 있고, 싫어할 사람도 있을텐데....
그냥 말 그대로 한 번 쭉 훑어보고 지나가는 수준의 수학이기 때문에
너무 큰 기대도 너무 큰 걱정도 할 필요는 없을 것 같다.
이 책은 원서 제목 그대로가 딱 적당한 제목인 것 같다.
"Mastering NLP from Foundations to LLMs"
(기초부터 LLM까지, 자연어 처리 완전 정복!)
'Books' 카테고리의 다른 글
| [파이썬 데이터 분석가 되기] 08 - Homework (1) | 2025.03.10 |
|---|---|
| [파이썬 데이터 분석가 되기] 07 - PRJ: Medical (0) | 2025.03.02 |
| [한빛미디어] 밑바닥부터 시작하는 딥러닝 1 (Deel Learning from Scratch 1) - 리마스터판 (1) | 2025.02.27 |
| [파이썬 데이터 분석가 되기] 06 - PRJ: Netflix (0) | 2025.02.23 |
| [파이썬 데이터 분석가 되기] 05 - BeautifulSoup (0) | 2025.02.16 |