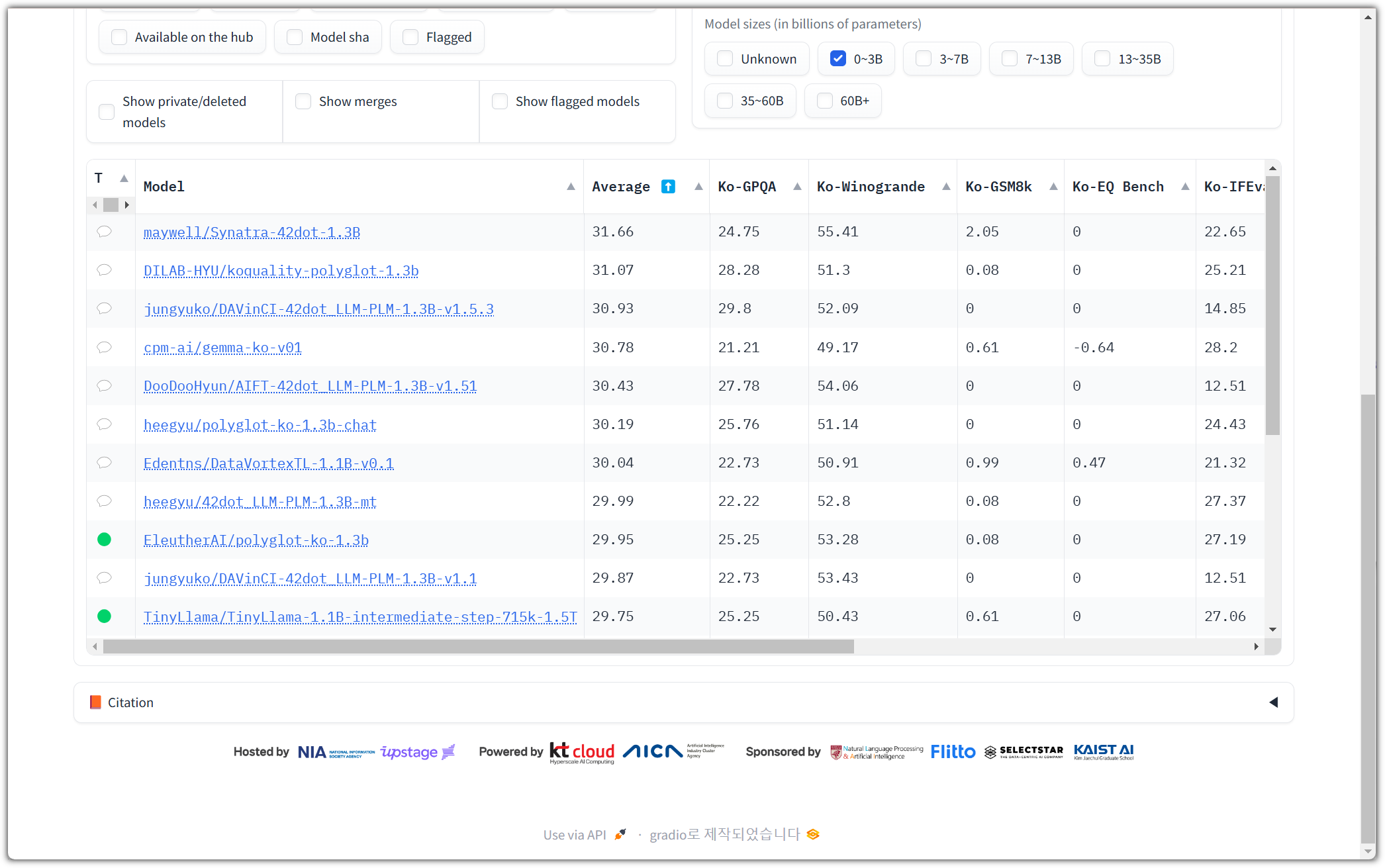
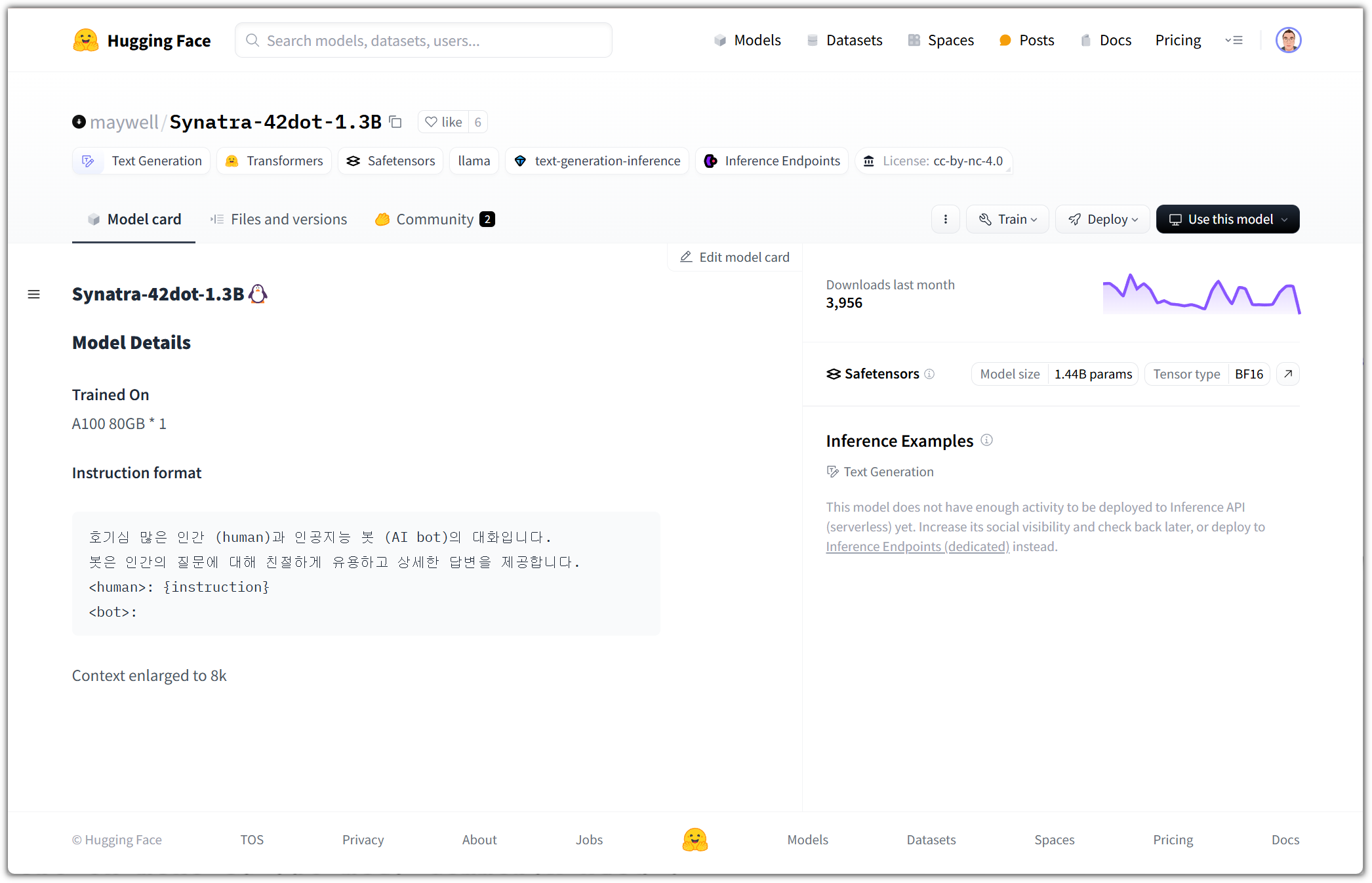
오늘은 왠지 LLAMA가 눈길을 끌어서 ...

친절하게 예제 코드도 제시해주고 있다.
|
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = 'Bllossom/llama-3.2-Korean-Bllossom-3B'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
instruction = "철수가 20개의 연필을 가지고 있었는데 영희가 절반을 가져가고 민수가 남은 5개를 가져갔으면 철수에게 남은 연필의 갯수는 몇개인가요?"
messages = [
{"role": "user", "content": f"{instruction}"}
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.convert_tokens_to_ids("<|end_of_text|>"),
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=1024,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9
)
print(tokenizer.decode(outputs[0][input_ids.shape[-1]:], skip_special_tokens=True))
|
3B 모델에서 과연 저 문제를 풀 수 있을까?
구글 코랩에서 위 코드를 실행해보자. (나는 GPU도 없는 가난한 머글이니까 ㅠㅠ)
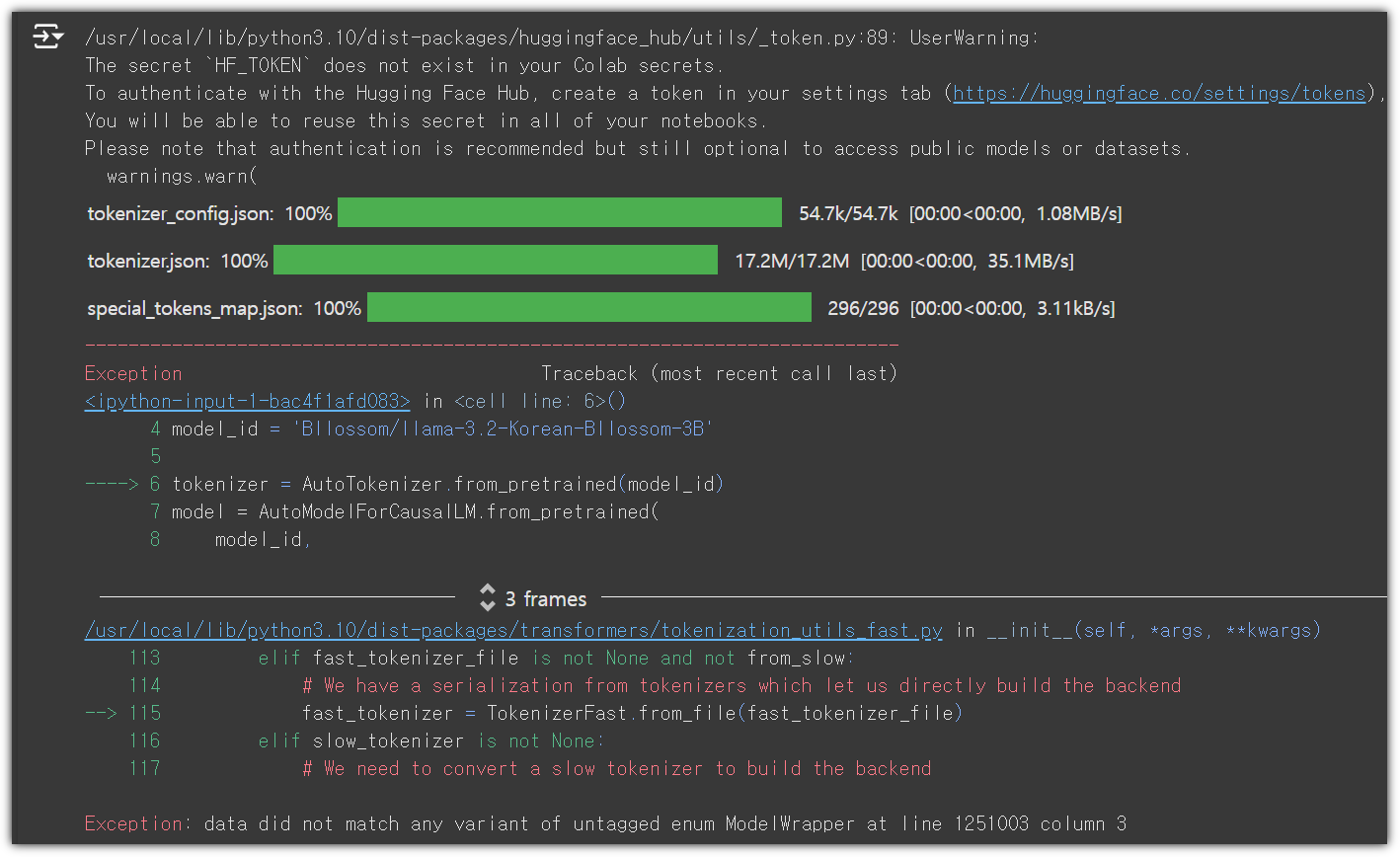
어?! 시키는 그대로 했는데, 왜?!
구글 코랩에서 기본 버전을 업그레이드 해주면 발생하지 않을테지만,
현재는 transformers, tokenizers 버전이 낮아서 발생하는 것으로 보인다.
| !pip install --upgrade transformers tokenizers |
설치가 끝나면 세션 재시작을 요구한다.
하면 된다.
그리고 나서 실행하면 시간이 좀 걸리지만... 잘 된다.

| 철수가 20개의 연필을 가지고 있었고 영희가 절반을 가져가면, 영희가 가져간 연필은 20 / 2 = 10개입니다. 철수가 남은 연필은 20 - 10 = 10개입니다. 민수가 5개를 가져가면, 철수가 남은 연필은 10 - 5 = 5개가 됩니다. 따라서 철수가 남은 연필의 갯수는 5개입니다. |
그리고, 문제도 잘 푼다!!!
반응형
'AI_ML > LLM' 카테고리의 다른 글
| HuggingFace - Learn - NLP Course #3 (2) | 2024.11.11 |
|---|---|
| HuggingFace - Learn - NLP Course #2 (0) | 2024.11.10 |
| HuggingFace - Learn - NLP Course (1) | 2024.11.09 |
| Gemini 잔소리꾼 만들기 (1) | 2024.11.08 |
| HuggingFace (허깅페이스 소개) (0) | 2024.06.24 |