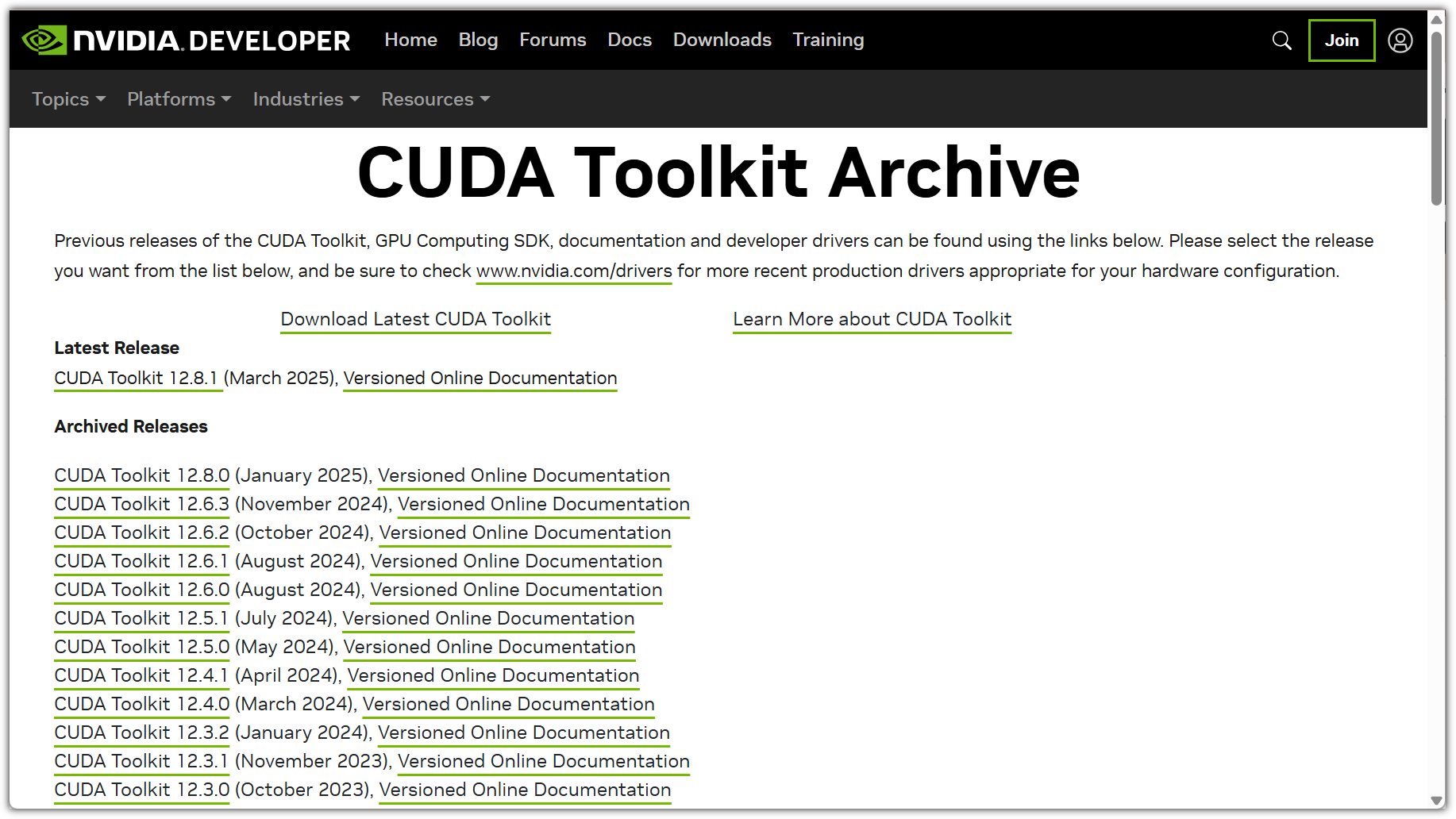
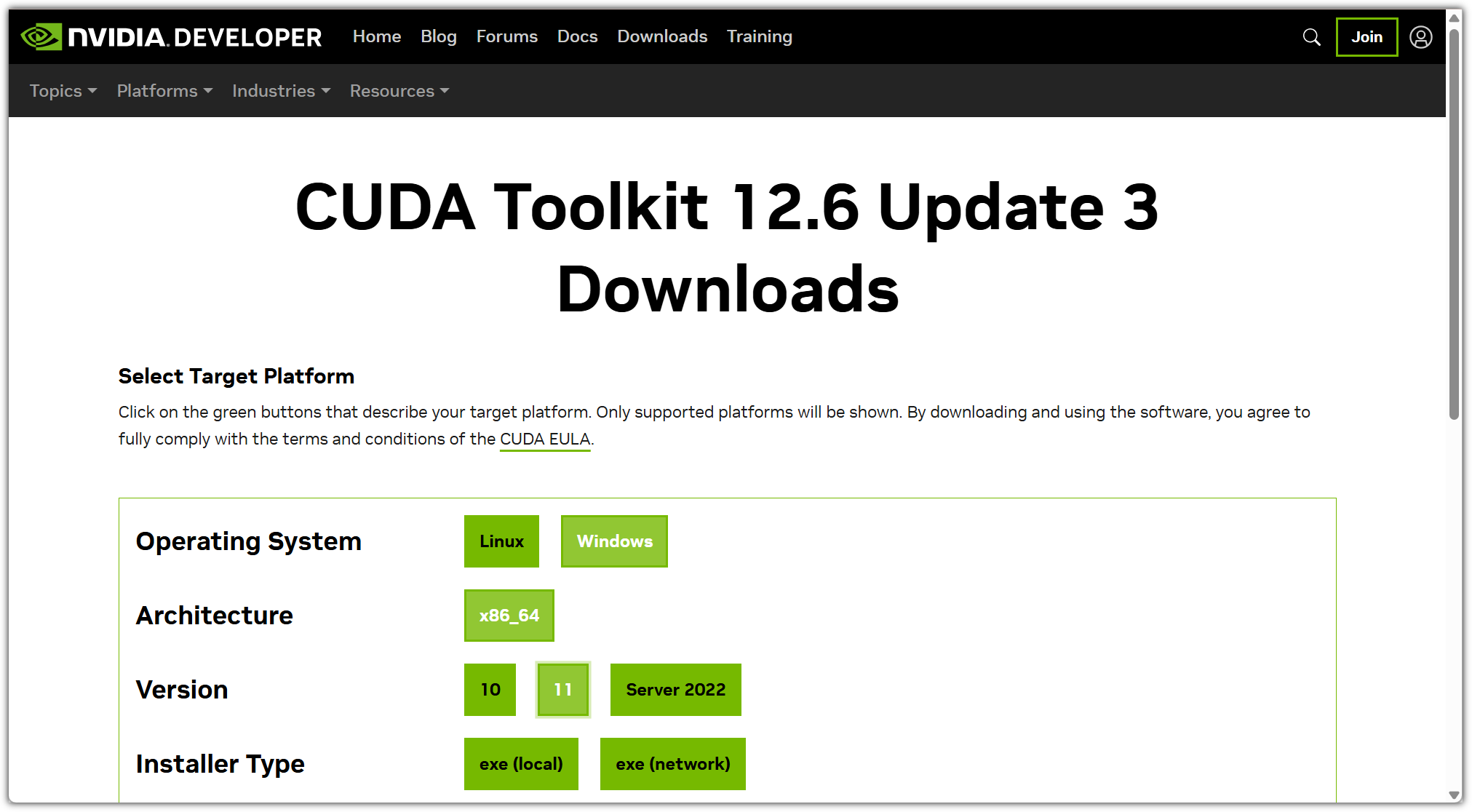
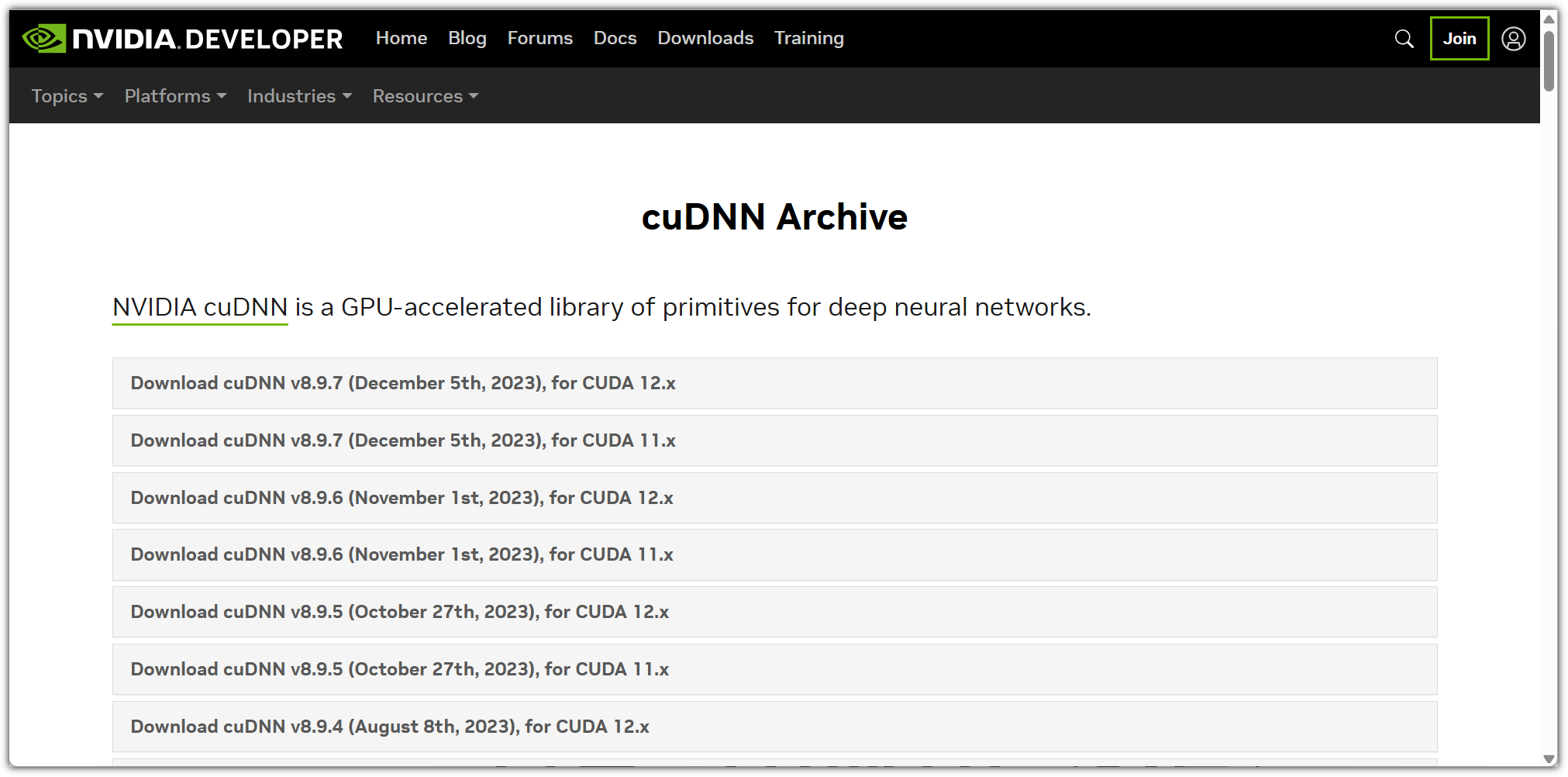
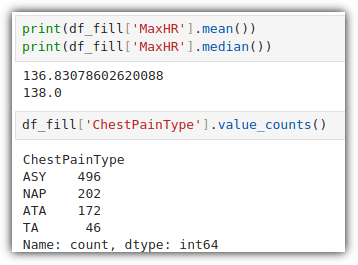
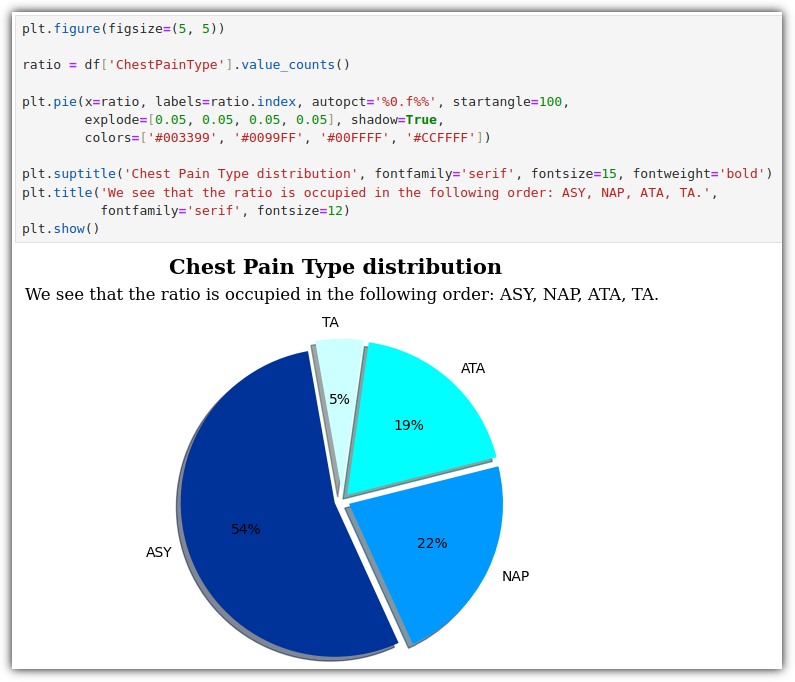
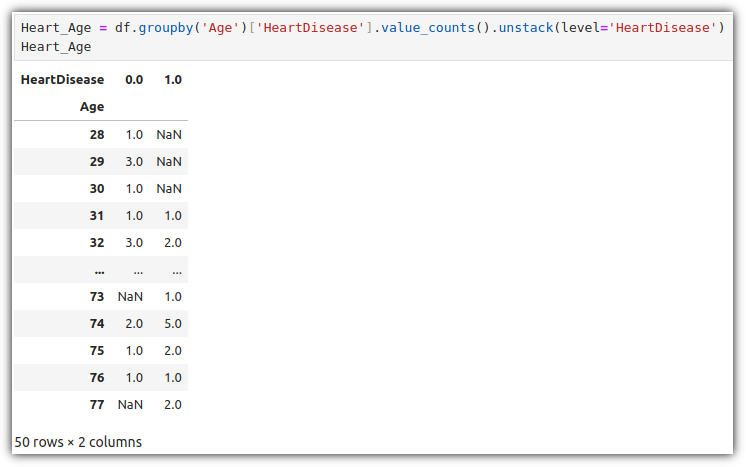
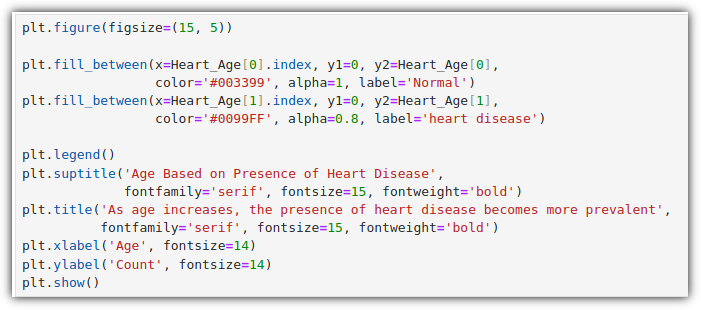
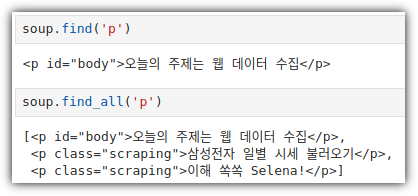
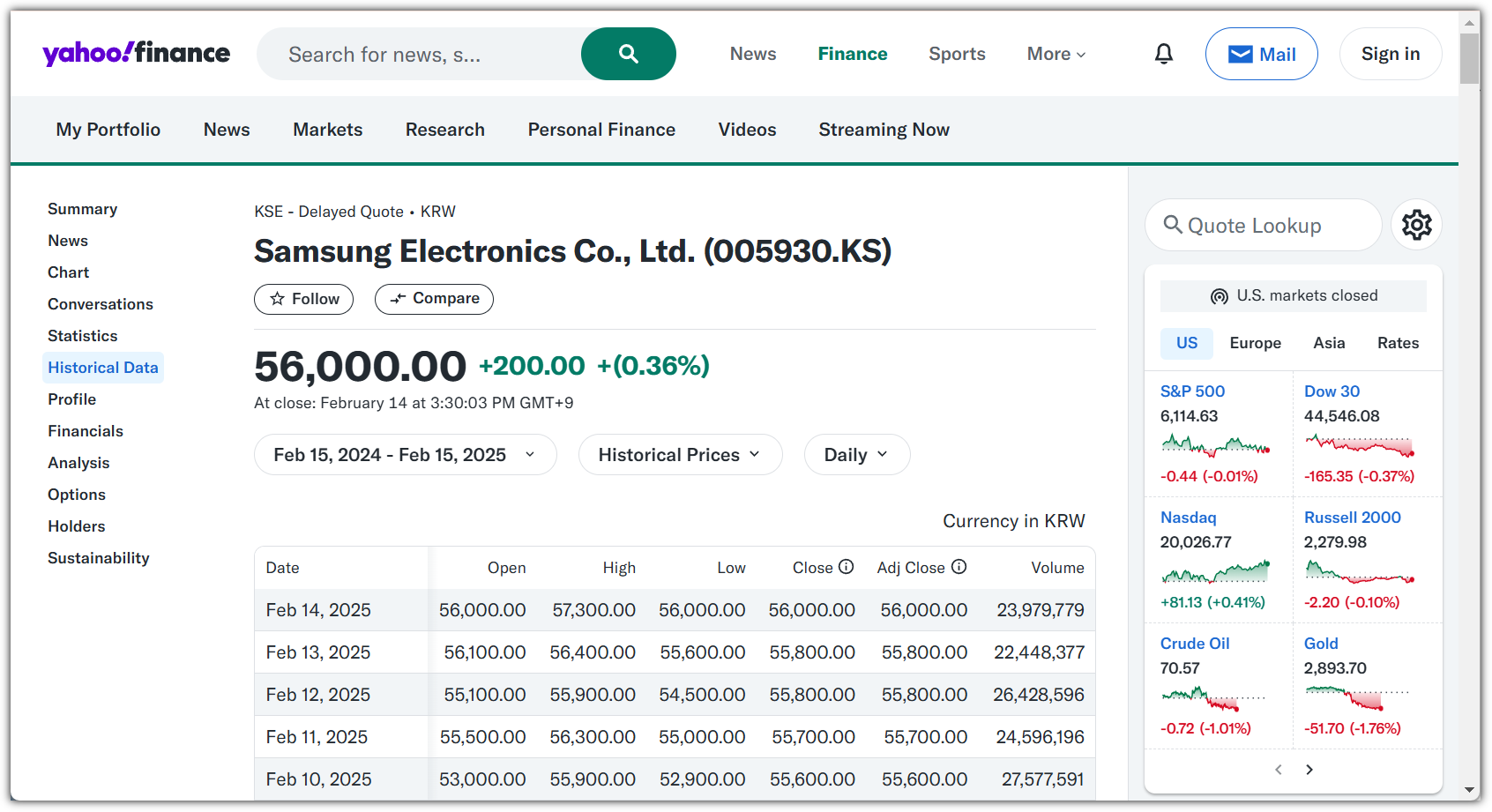
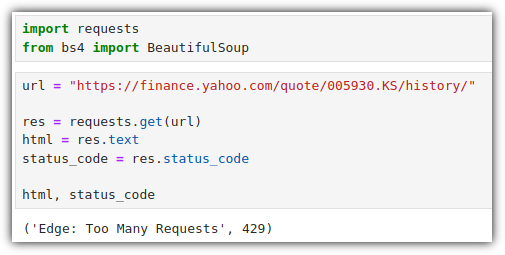
내가 생각했을 때에는 "NLP(자연어 처리)와 관련된 전체적인 내용을 훑어보고 싶은 사람"이라고 말해야 하지 않나 싶다.
이 책의 목차는 다음과 같다.
CHAPTER 1 자연어 처리 개요 살펴보기 CHAPTER 2 머신러닝과 자연어 처리를 위한 선형대수, 확률, 통계 마스터하기 CHAPTER 3 자연어 처리에서 머신러닝 잠재력 발휘하기 CHAPTER 4 자연어 처리 성능을 위한 텍스트 전처리 과정 최적화 CHAPTER 5 텍스트 분류 강화: 전통적인 머신러닝 기법 활용하기 CHAPTER 6 텍스트 분류의 재해석: 딥러닝 언어 모델 깊게 탐구하기 CHAPTER 7 대규모 언어 모델 이해하기 CHAPTER 8 대규모 언어 모델의 잠재력을 끌어내는 RAG 활용 방법 CHAPTER 9 대규모 언어 모델이 주도하는 고급 응용 프로그램 및 혁신의 최전선 CHAPTER 10 대규모 언어 모델과 인공지능이 주도하는 과거, 현재, 미래 트렌드 분석 CHAPTER 11 세계적 전문가들이 바라본 산업의 현재와 미래
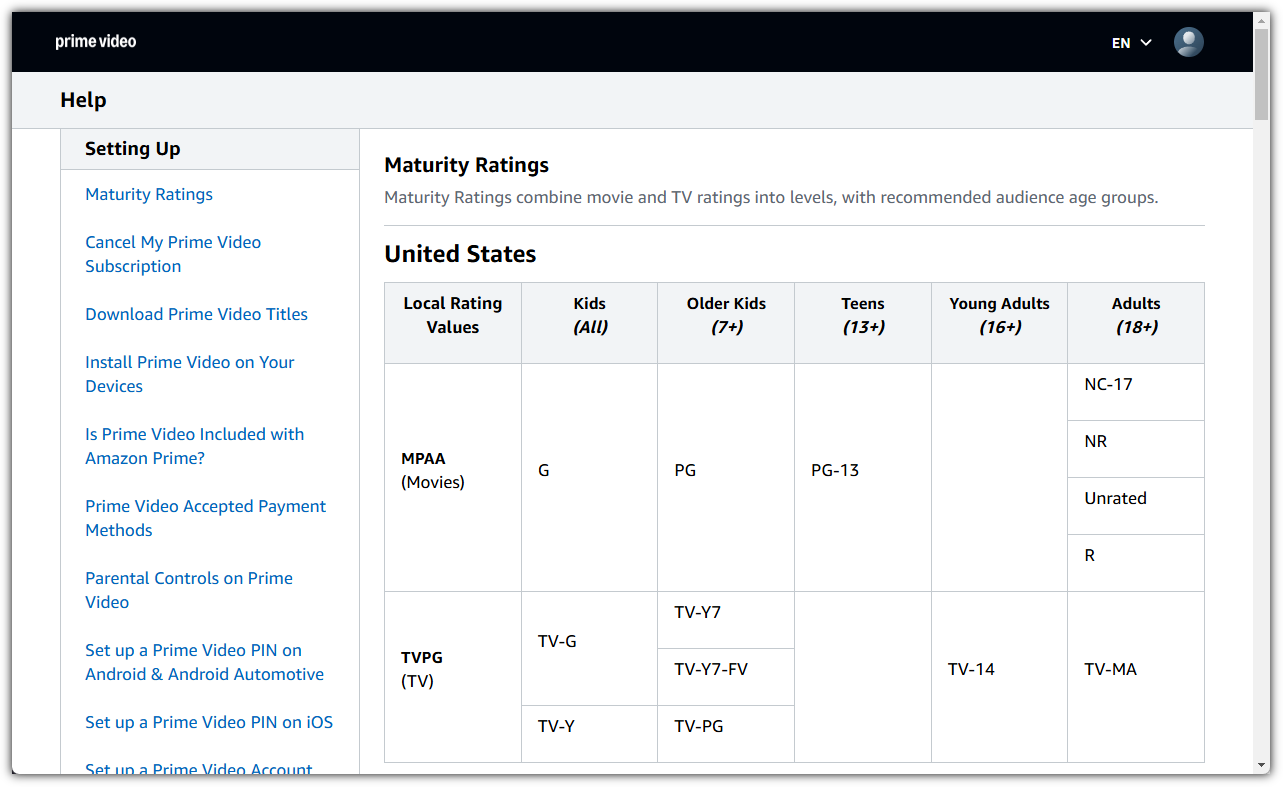
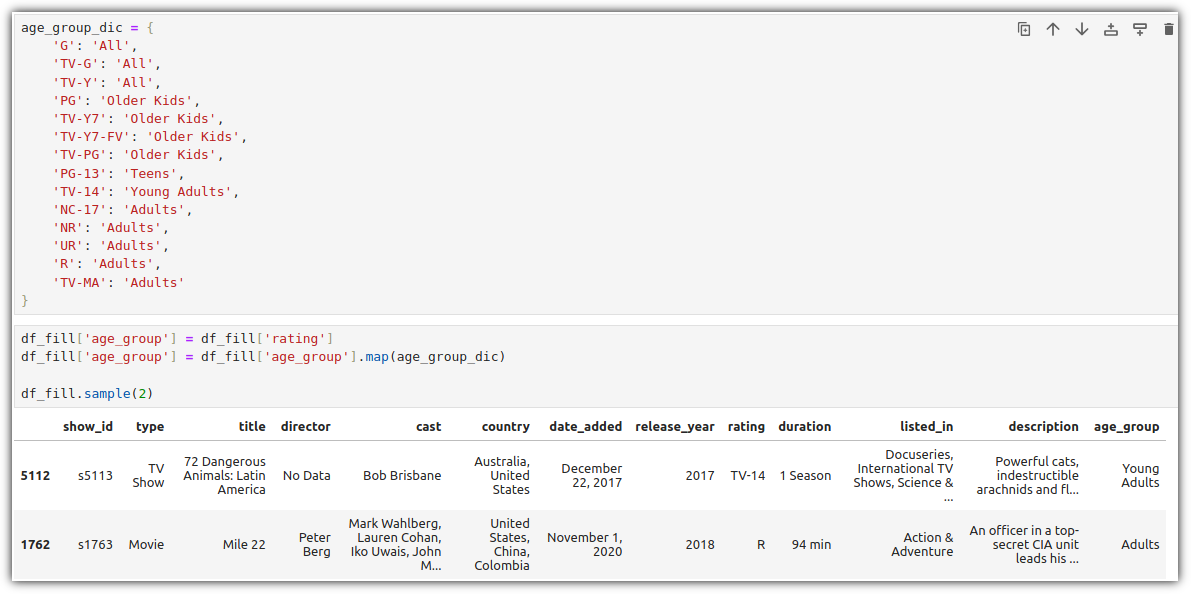
미국의 등급 시스템을 기준으로 묶어주면 되는데, 'age_group' 명칭의 column으로 생성해보도록 하겠다.
매핑하기 위한 딕셔너리를 작성하고, map()을 돌리면 잘 분류되어 값이 추가된 것을 볼 수 있다.
지금까지 작업한 내역들을 CSV 파일로 저장까지 하면서 일단 마무리 해보자.
⑸ Visualization
Graph를 그릴 기본 준비를 해보자.
원하는 정보를 검색하는 것을 해보자.
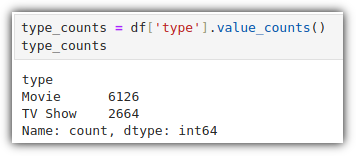
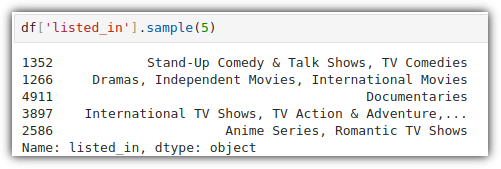
이번에는 'type' column의 내역을 한 번 살펴보자.
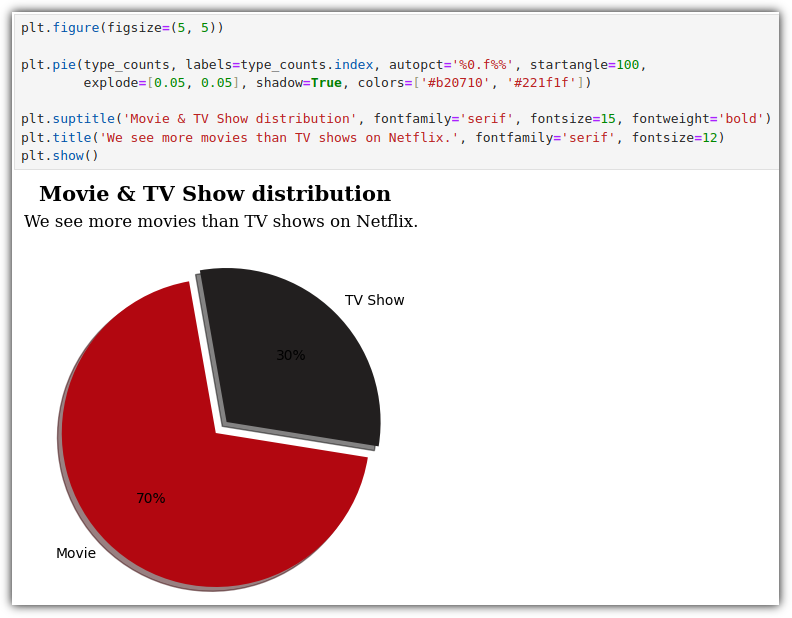
해당 데이터를 가지고 파이 차트를 그려보자.
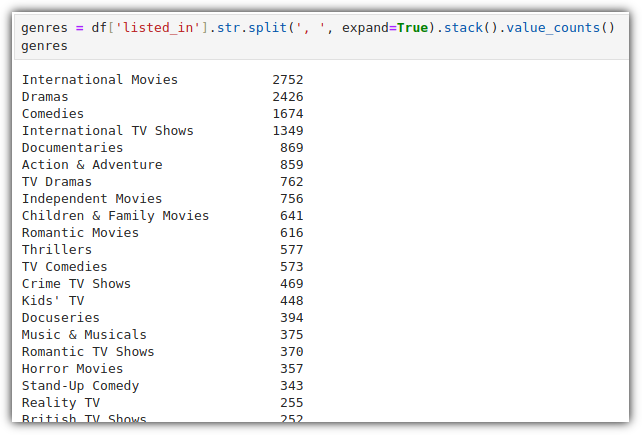
이번에는 장르 정보를 담고 있는 'listed_in' column을 살펴보자.
여러 장르에 속하는 경우 ", "로 여러 항목이 나열되어 있는 것을 볼 수 있다.
", "로 split을 하는데 'expand=True' 옵션이기에 column을 확장한다.
그런다음 다시 'stack()'으로 세로 방향으로 변환(column 하나로 합치기)해서 value_counts() 한다.
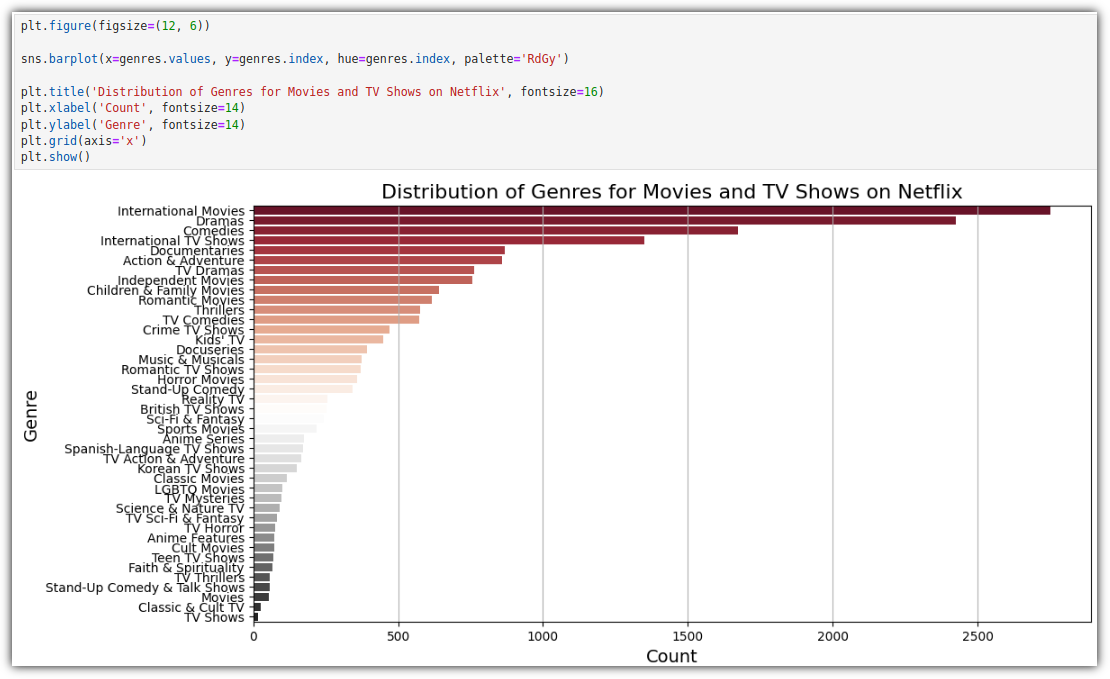
이제 막대 그래프로 그려보자.
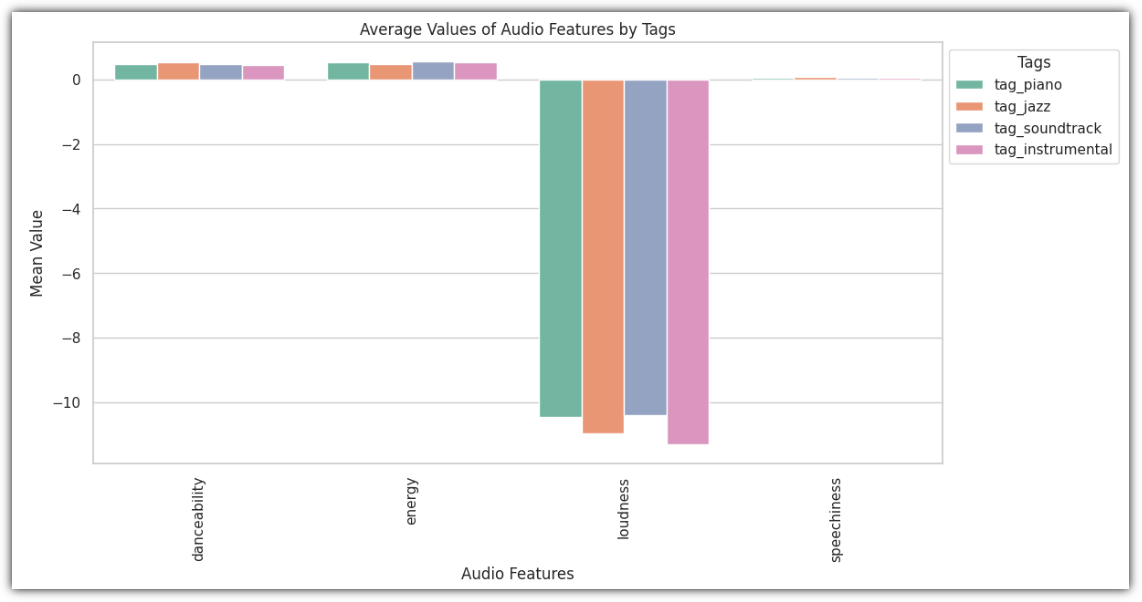
이 그래프를 보고 얻을 수 있는 인사이트는 다음과 같다고 한다.
"넷플릭스는 드라마와 국제 영화에 집중하고 있습니다. 글로벌한 콘텐츠 제공과 깊이 있는 스토리 라인으로 시청자들의 다양한 취향을 만족시키려 하려는 것 같습니다. 또한, 다양한 영화 장르의 제공을 통해 시청자들에게 보다 풍부한 선택지를 제공합니다. 정리하자면, 넷플릭스의 전략은 장르 다양성과 글로벌 사용자들의 요구를 동시에 충족시키기 위한 방향으로 나아가고 있음을 알 수 있습니다."
이번에는 나이 그룹별 국가별 콘텐츠를 살펴보자.
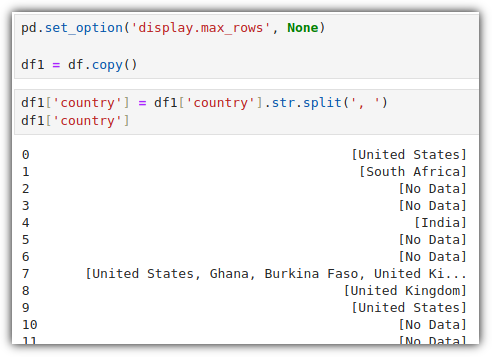
'country' column의 경우에도 ', '로 구분된 여러 나라가 입력되어 있음을 알 수 있다.
일단, split() 해보자.
pandas의 옵션을 설정하는 기능을 활용해서 출력 값의 개수 제한을 풀어봤다. (유용해 보이지는 않는다)
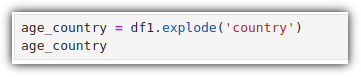
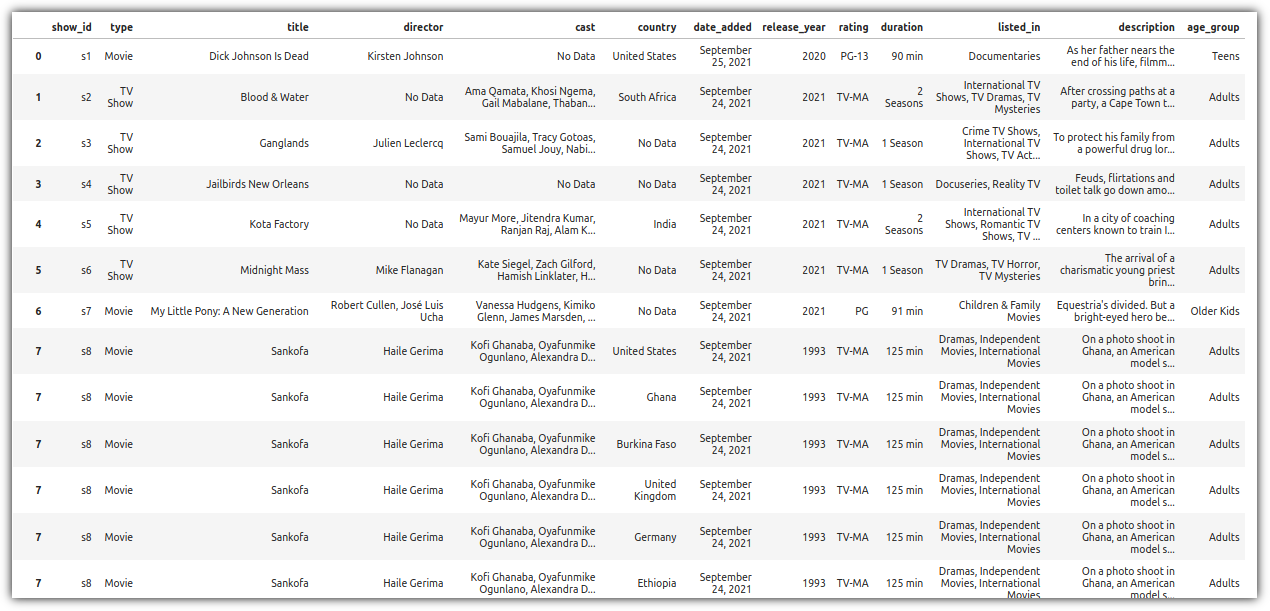
list 형태로 되어있는 'country' column을 기준으로 row를 분리해보자.
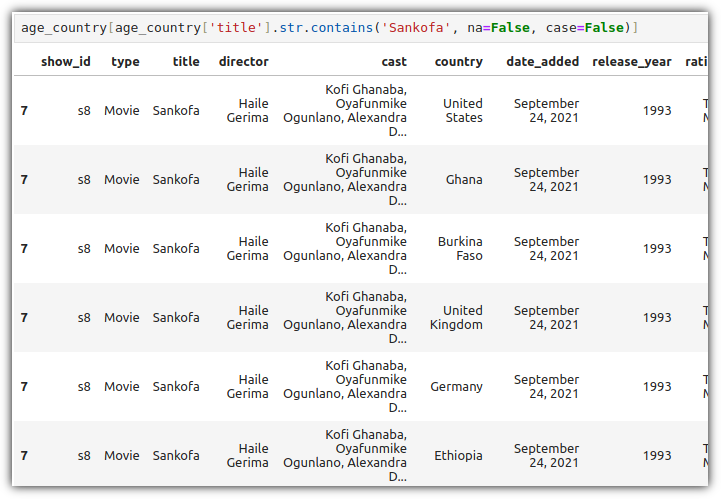
7번 index를 보면 row가 분리된 것을 확인할 수 있다.
더 자세히 살펴보자.
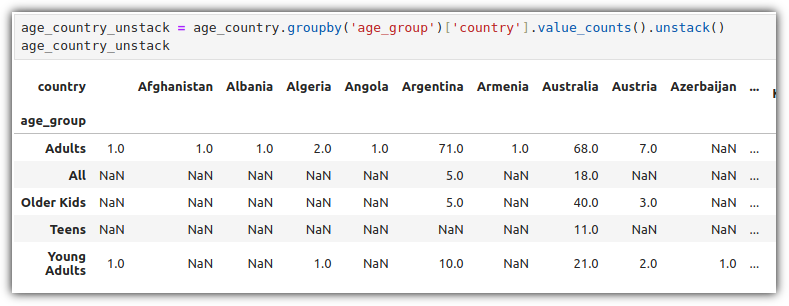
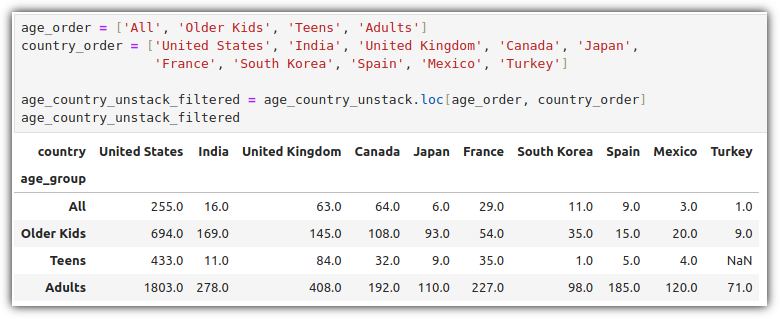
각 연령대별로 국가의 개수를 count하고 이를 표 형태로 살펴보자.
'.groupby('age_group')' 연령대로 그룹핑을 하고, '['country'].value_counts()' 국가의 개수를 센 뒤, '.unstack()'를 통해 세로로 정리된 데이터를 가로 형태로 변환을 했다.
우리가 사용할 항목들만 선별해서 정리해보자.
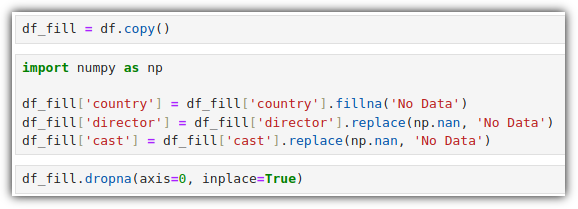
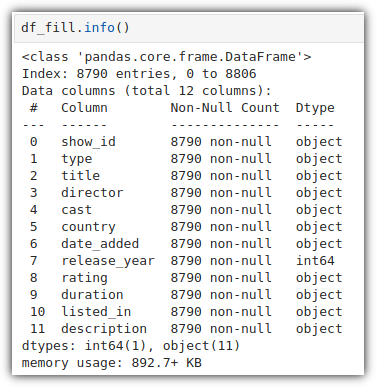
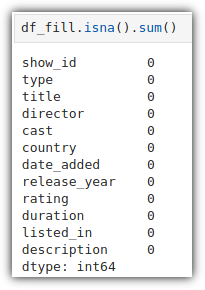
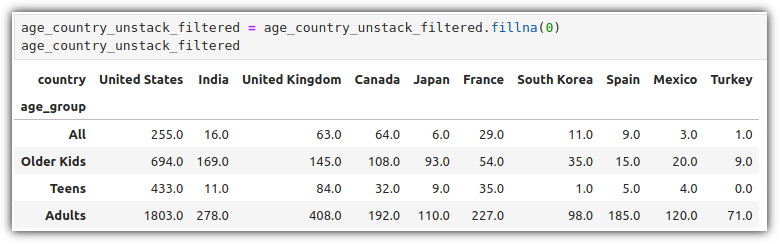
결측치 값이 보인다. 0으로 채우자.
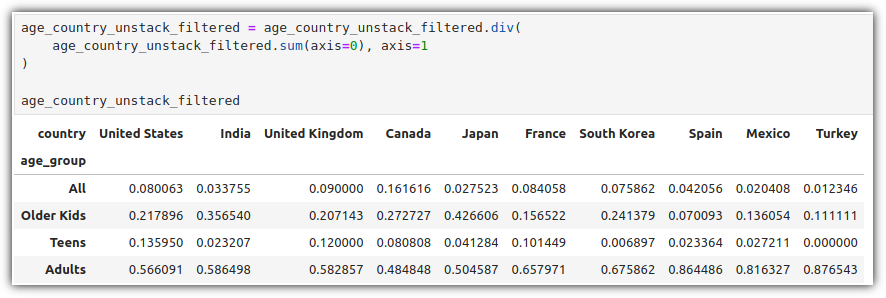
지금 보이는 값으로는 서로간의 값 비교를 하기가 쉽지 않다.
비율로 값들을 변경해보자.
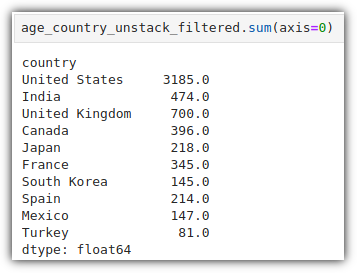
'.sum(axis=0)'을 통해 각 열의 합을 계산함 → 국가별 sum() 값을 구함
'.div(..., axis=1)'을 통해 각 연령대듸 값들을 국가(column)의 총합으로 나누어 비율을 계산
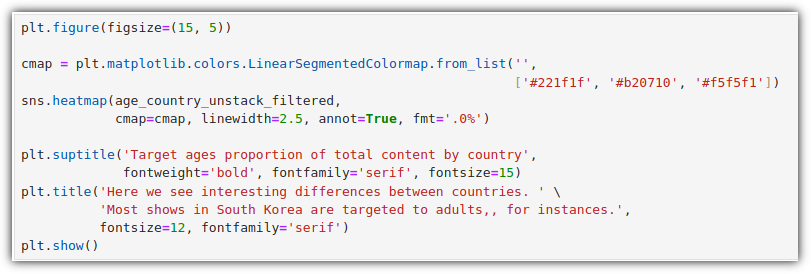
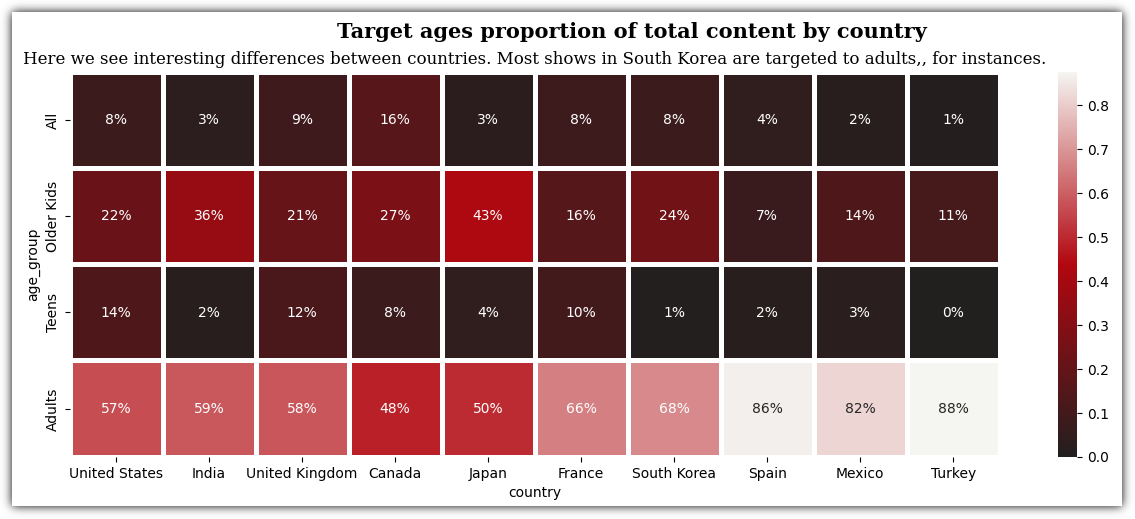
지금까지 진행한 내용을 가지고 히트맵을 그려보자.
위 그래프를 보고 얻을 수 있는 인사트는 다음과 같다고 한다.
"United States/Canada는 모든 나이 그룹에서 골고루 이용자를 가지고 있기에 넷플릭스가 다양한 연령층에 걸쳐 널리 사용되고 있음을 나타내고 있다. 그리고 모든 국가에서 성인 이용자가 가장 많은데, 이는 넷플릭스의 콘텐츠가 성인들의 관심사와 취향을 충족시키는 데 중점을 두고 있다는 것을 보여준다. 성인층의 높은 비율은 넷플릭스의 다양한 장르와 깊이 있는 콘텐츠가 성인 이용자들에게 특히 매력적임을 시사한다. 한편 India/Japan은 Older Kids의 비율이 꽤 높은데 이는 해당 국가들에서 넷플릭스가 어린이와 가족 단위의 콘텐츠를 많이 제공하고 있음을 나타낸다. 이러한 결과는 각국의 문화적 특성과 콘텐츠 선호도가 넷플릭스 이용 패턴에 영향을 미친다는 것을 시사한다. 이러한 분석을 통해 넷플릭스는 각 국가별로 이용자의 연령대에 맞춘 컨텐츠와 교육적인 프로그램을 강화할 수 있으며, 성인 비율이 높은 국가에서는 성인 대상의 드라마/영화/다큐멘터리 등을 더욱 강조할 수 있다."