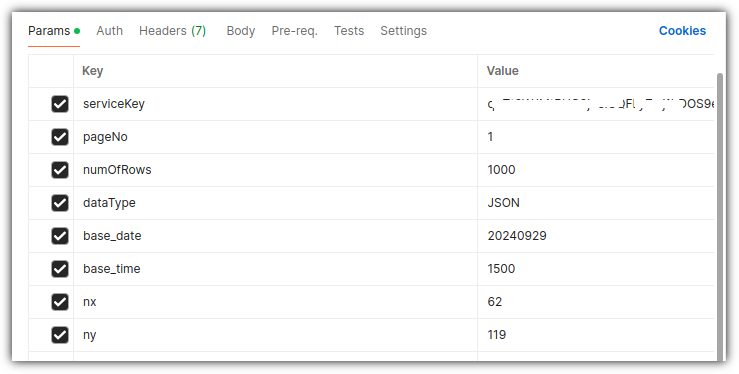
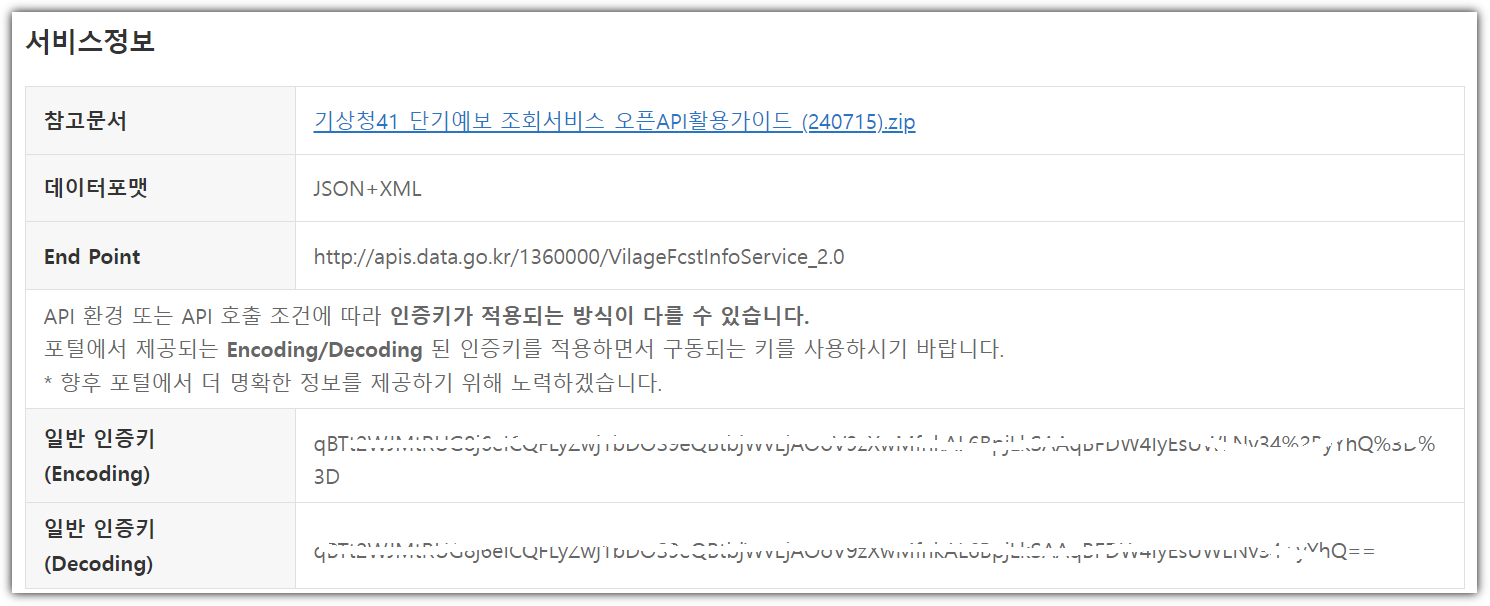
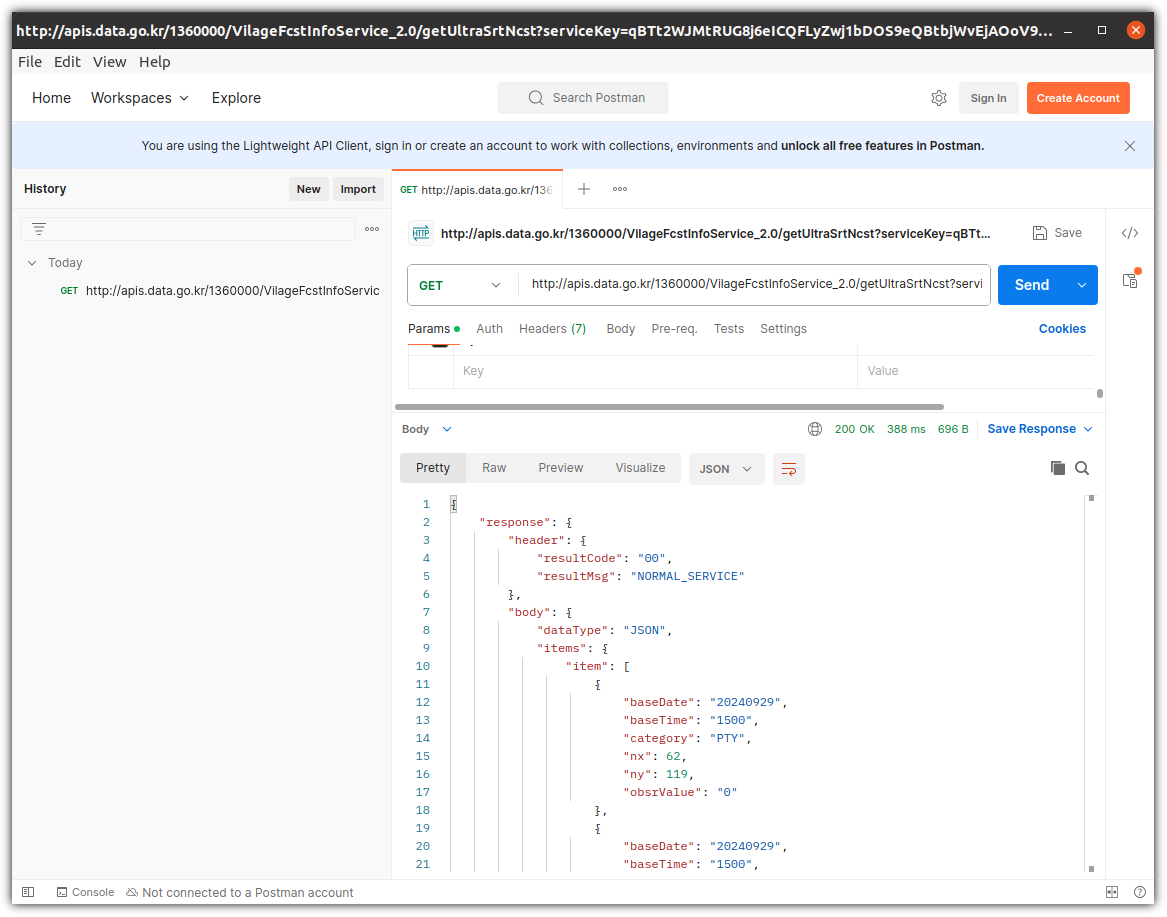
GitHub에서 여러 LLM 모델들을 가지고 놀 수 있는 서비스를 제공하고자 하고 있어서
이것을 소개해보려 한다.
아직은 정식 서비스를 하고 있지 않아서인지, 메뉴가 꼭 꼭 숨어있다.
아! 아직은 Preview 상태라서 해당 메뉴가 보이지 않는 분들이 계실 수도 있다.
그런 분들은 그냥 이런게 곧 나오겠구나~하고 구경 먼저 해보시길 ^^
일단 로그인을 하고...

왼쪽 위 메뉴 버튼을 눌러 펼친 다음에
"Marketplace"를 선택하자.

Marketplace 메뉴들을 보면 "Models"를 발견할 수 있다.
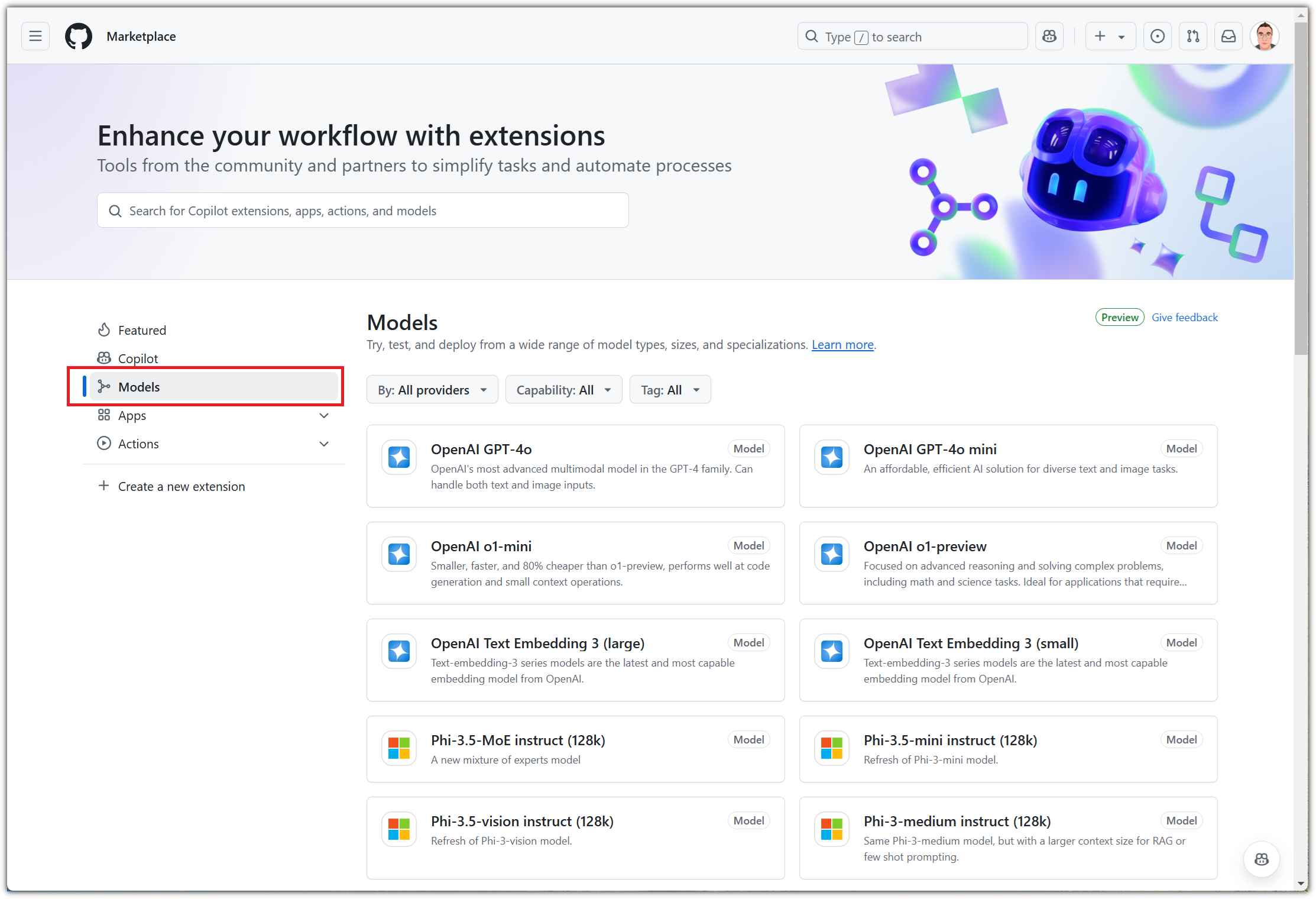
여러 LLM 모델들을 볼 수 있는데,
일단 친근한 GPT-4o를 선택해보자.
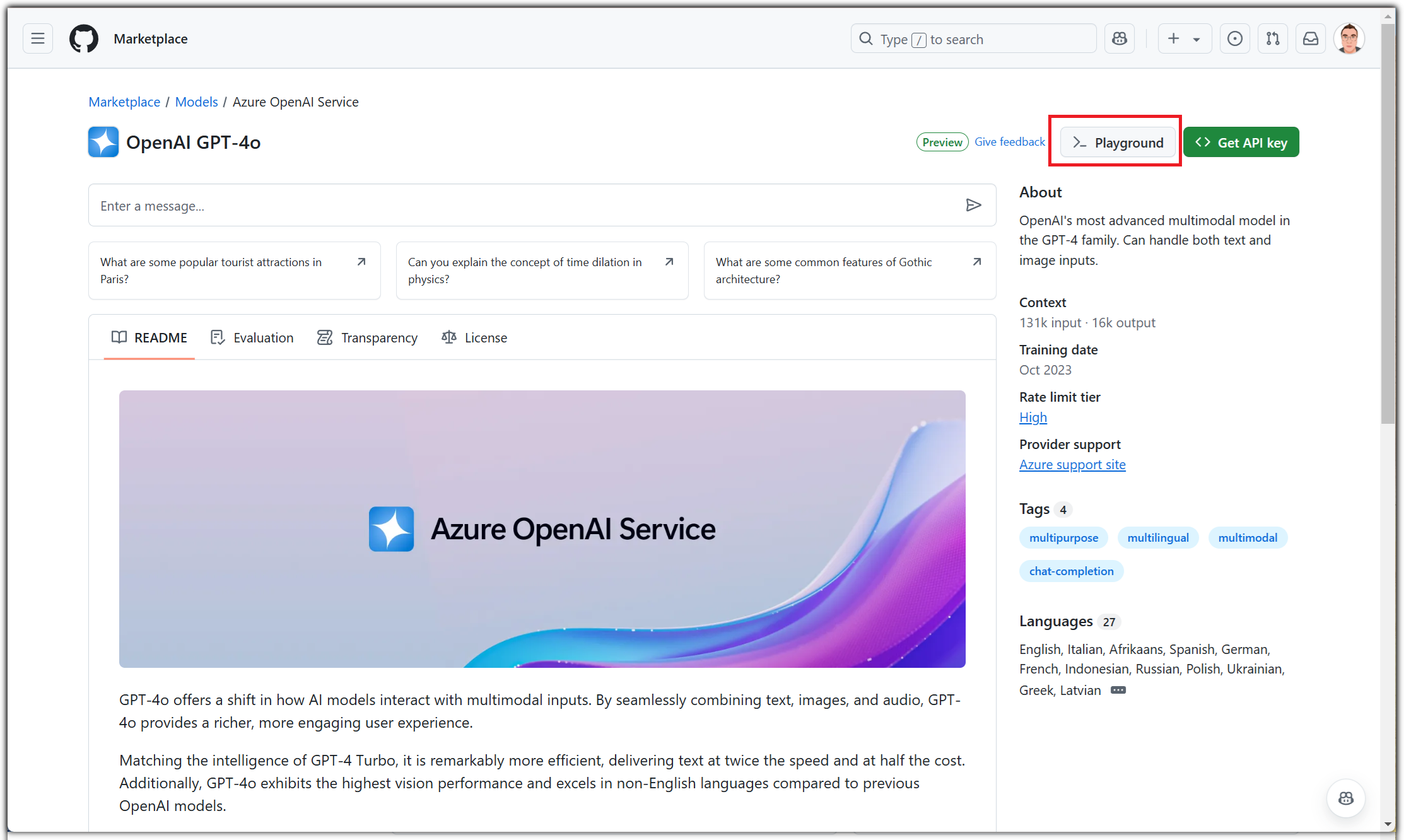
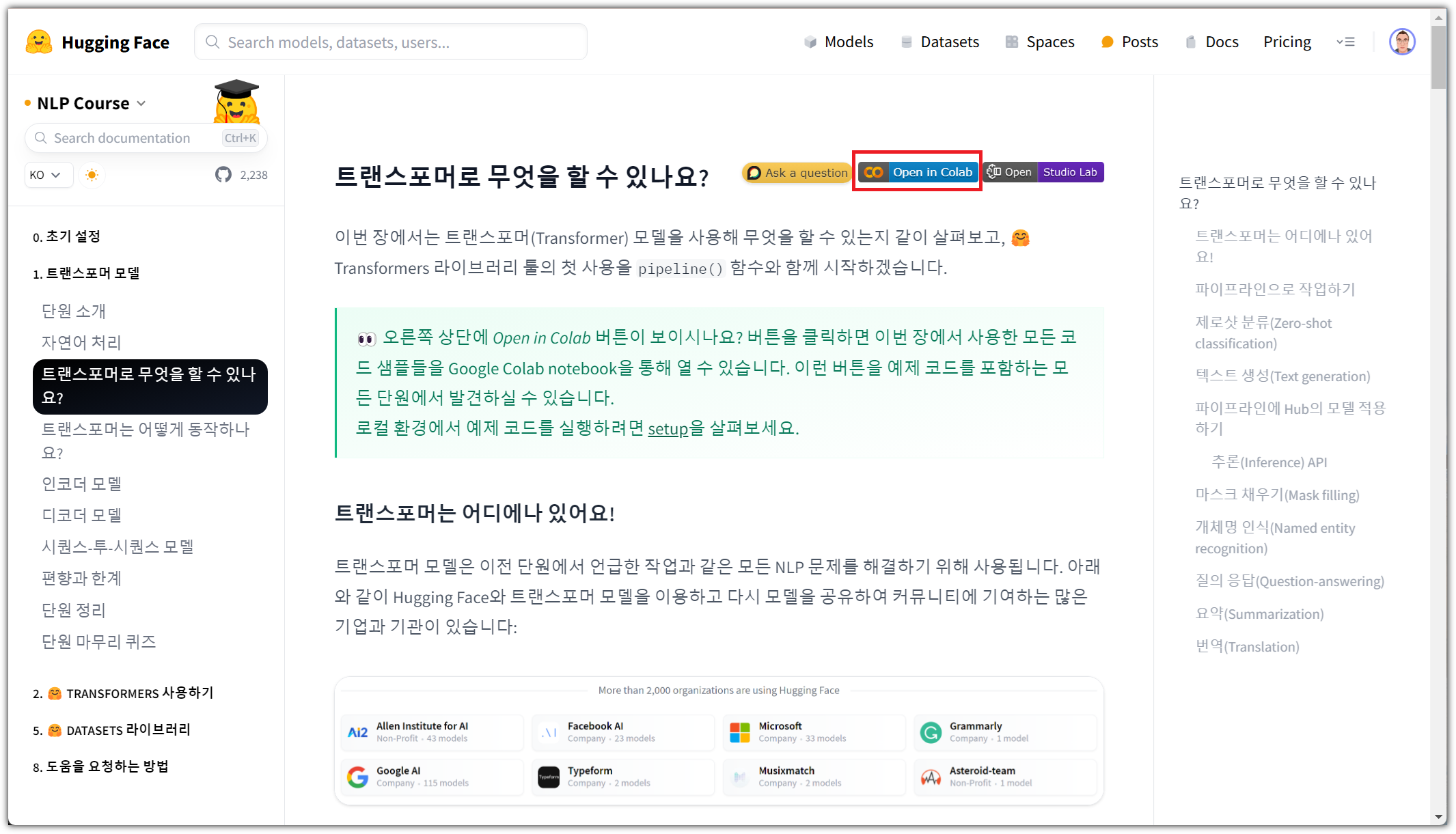
오른쪽 위의 "Playground" 버튼을 선택해보자.
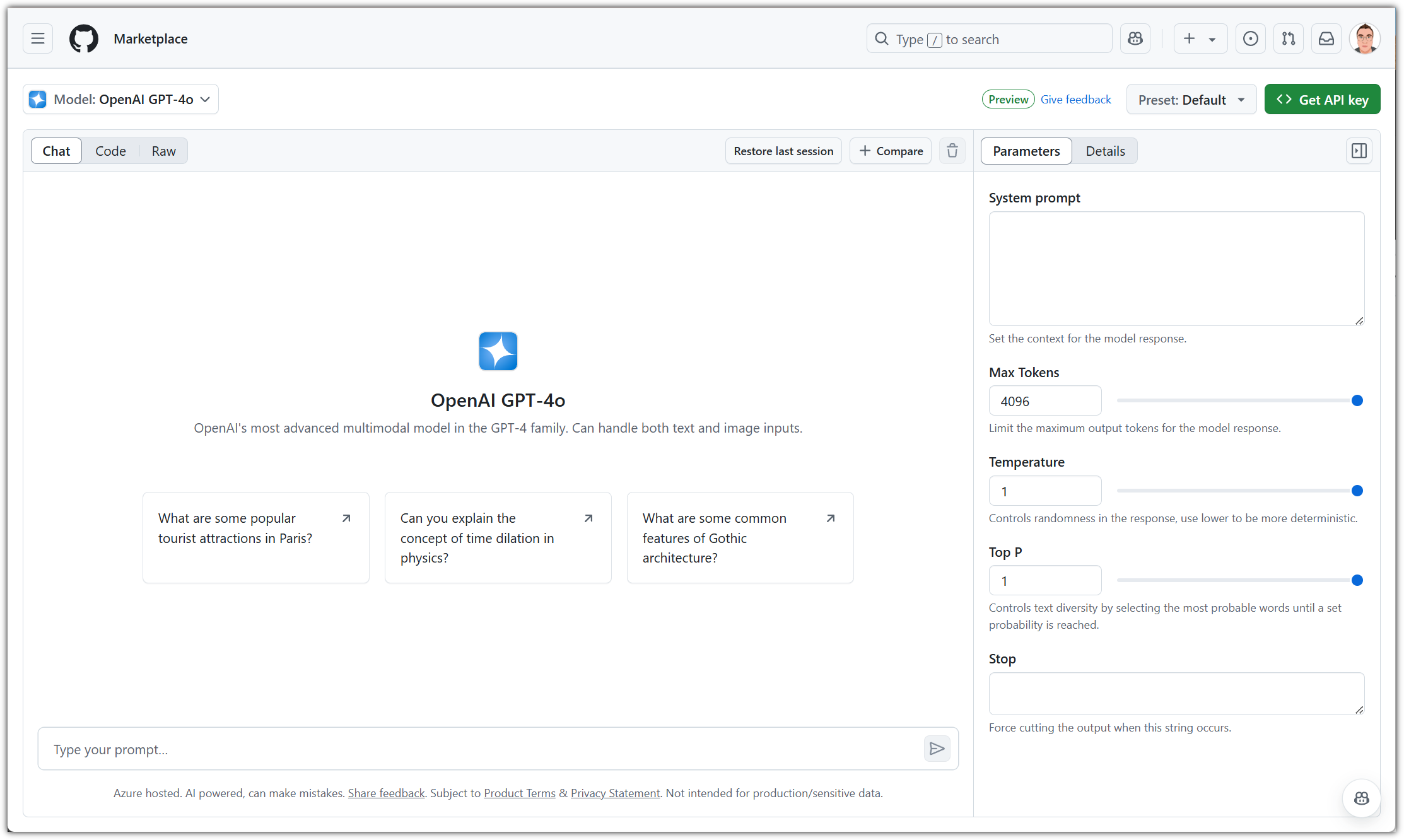
System prompt를 비롯해서 Max Tokens라던지, Temperature 등 여러 parameter들을 설정할 수도 있다.
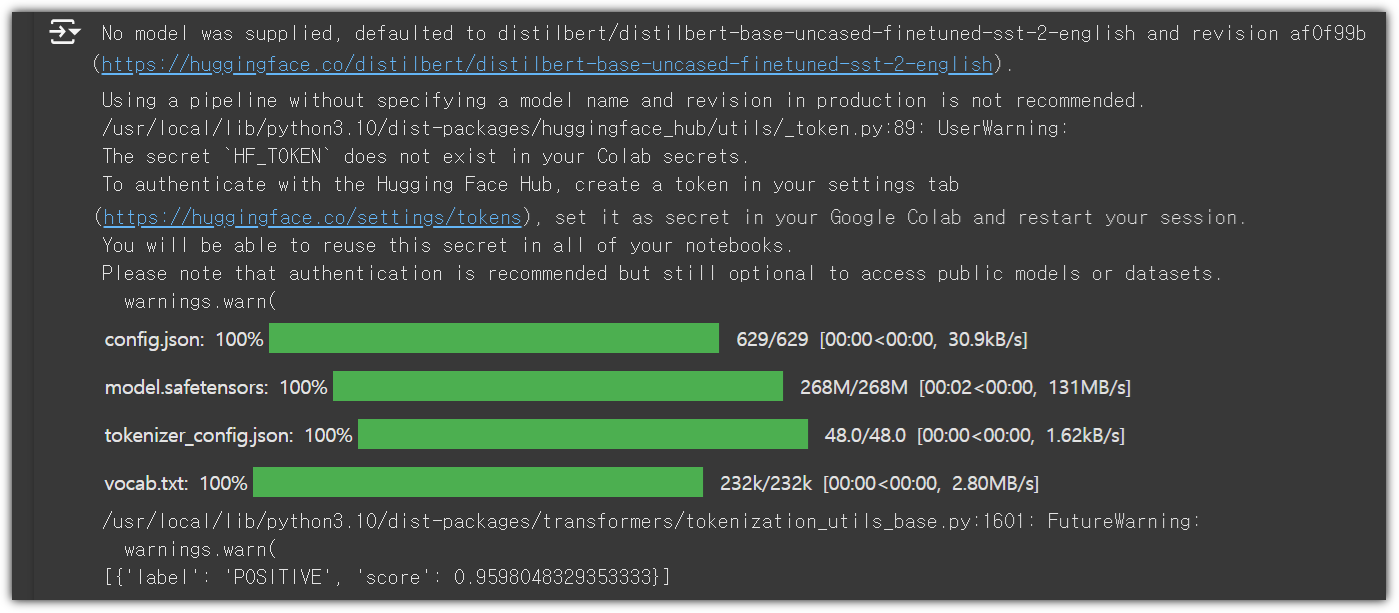
직접 프롬프트를 입력하면 대기시간 없이 즉시 응답을 해준다.
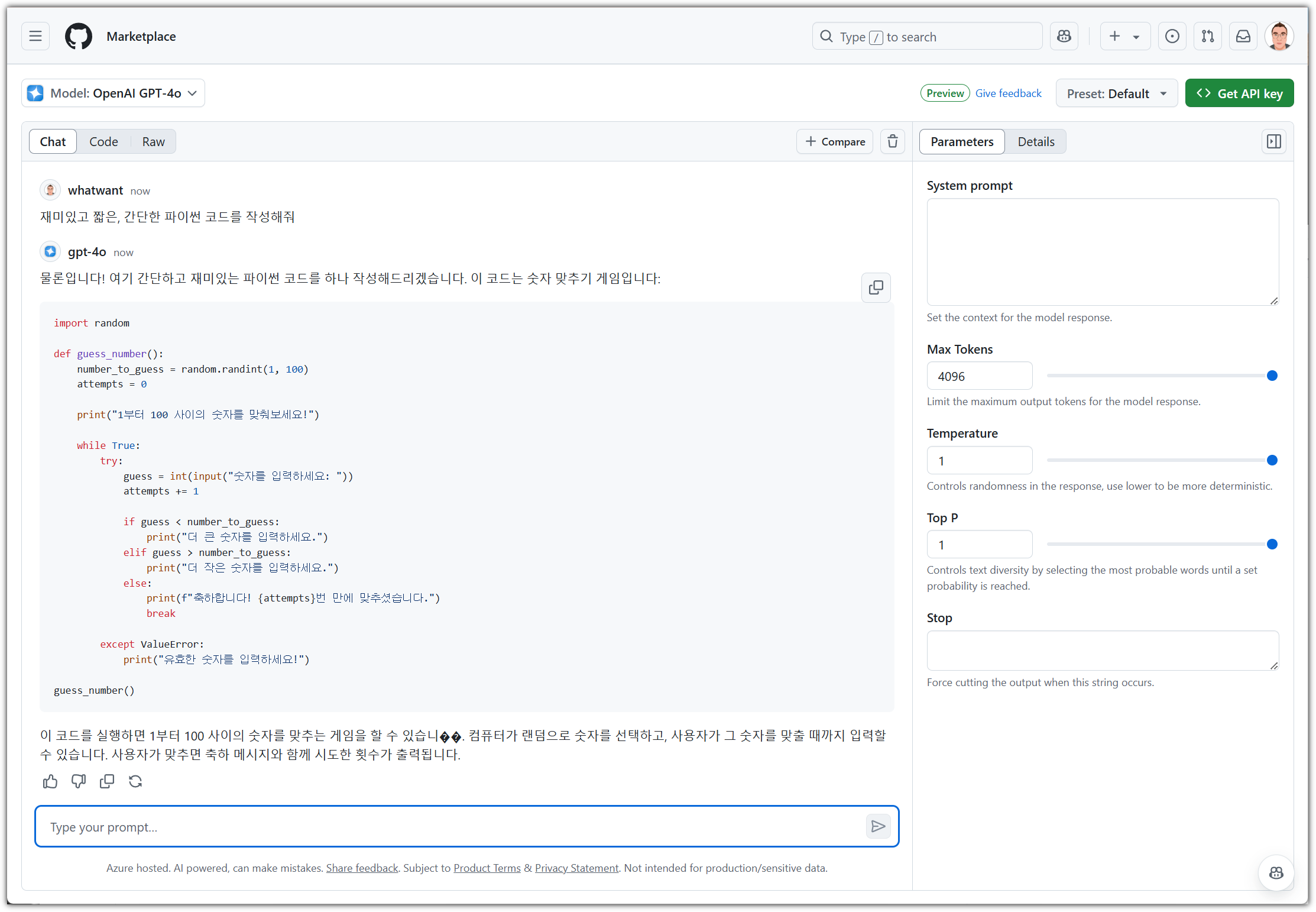
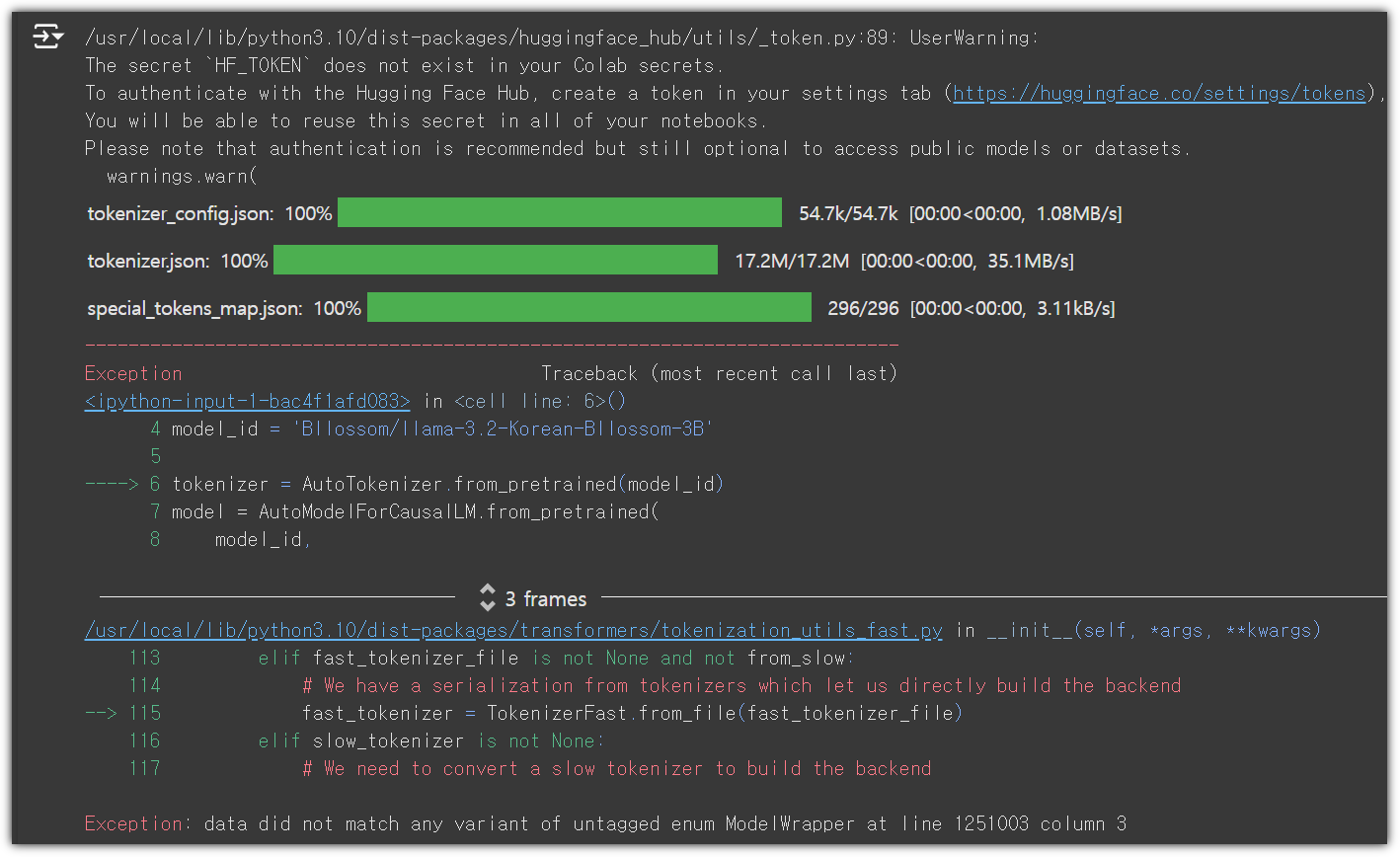
한글 출력이 깨지는 것이 있는데, model의 잘못인지 GitHub에서의 출력 문제인지는 불분명하다.
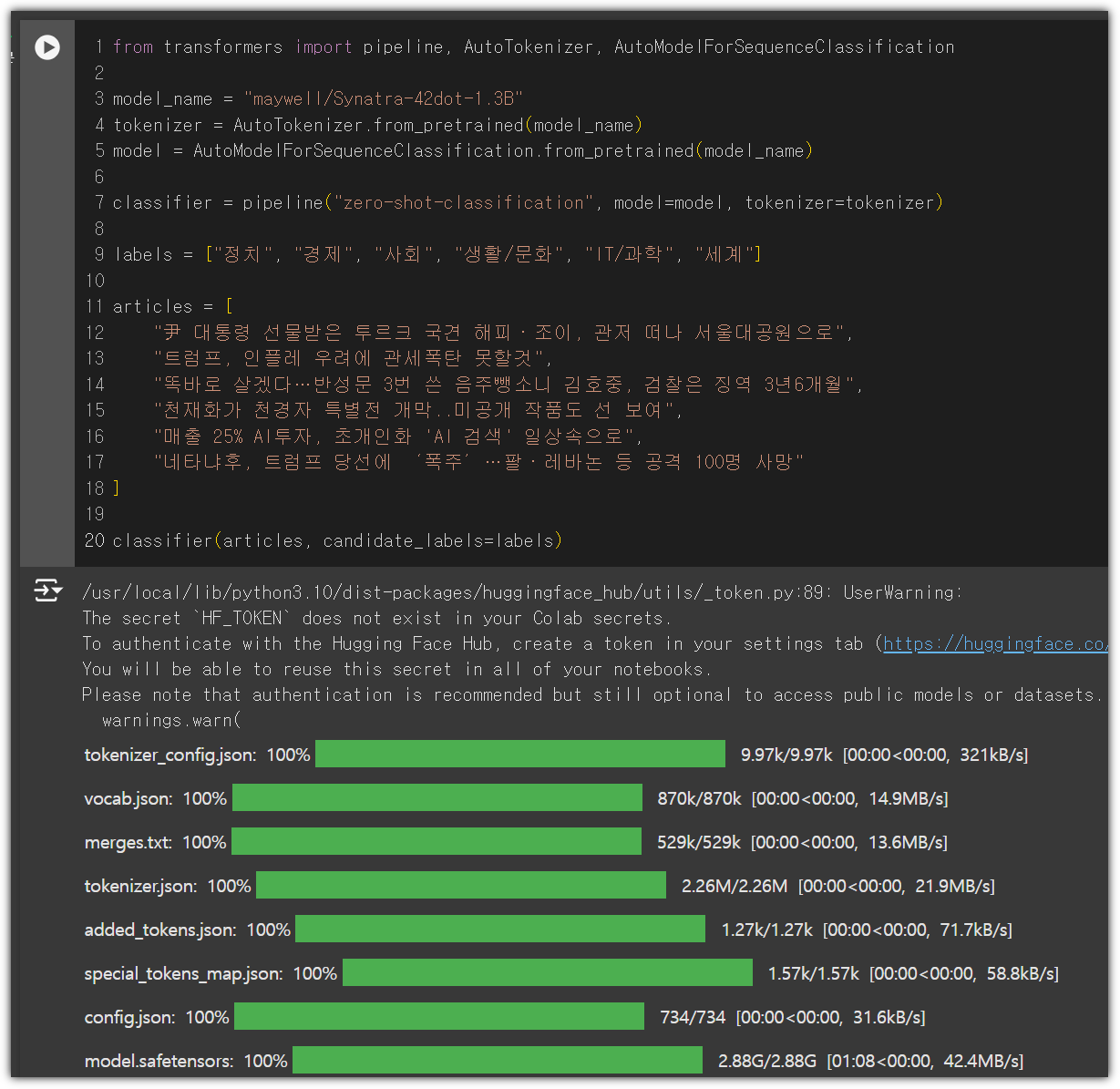
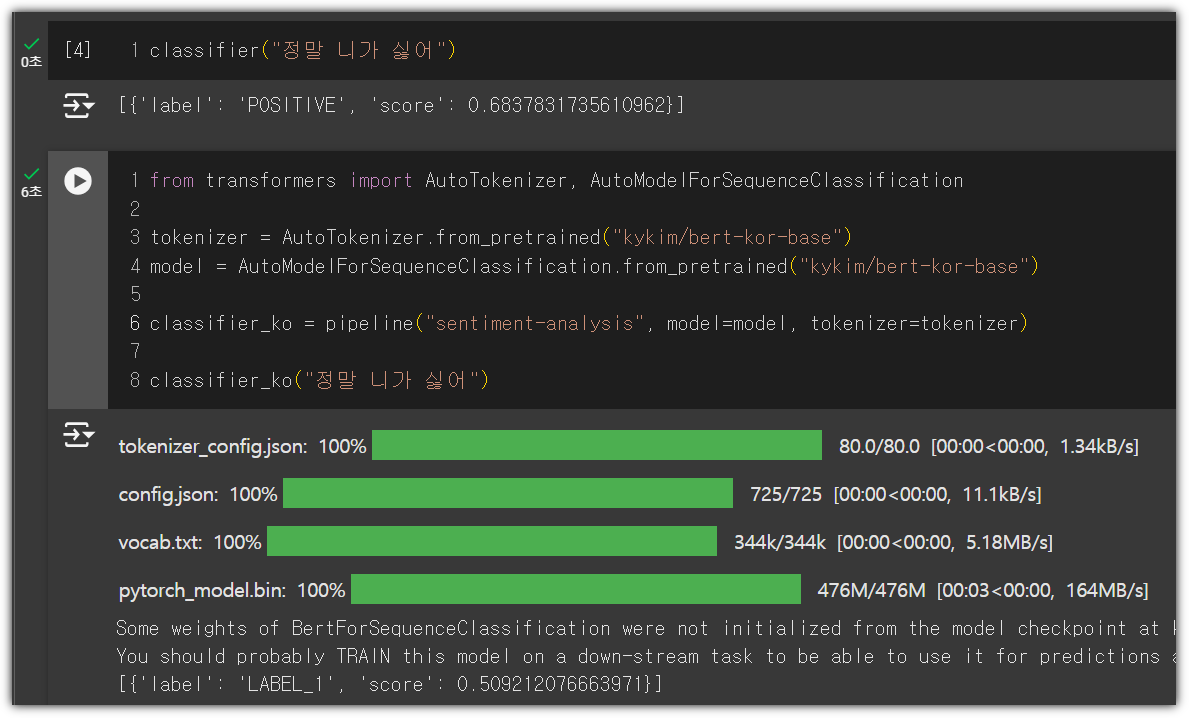
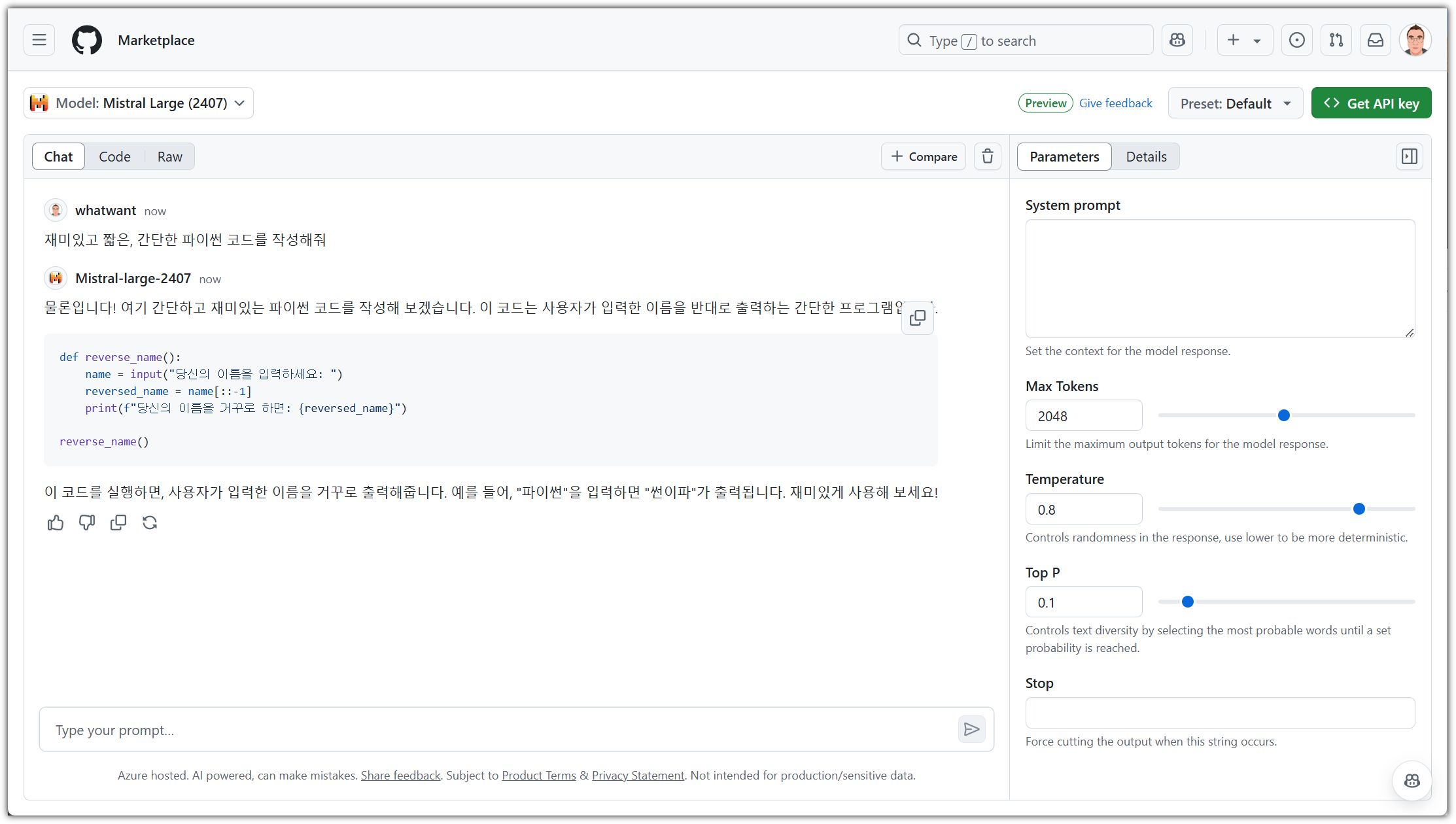
말만 들어봤던 Mistral 모델을 가지고도 한 번 해봤다.
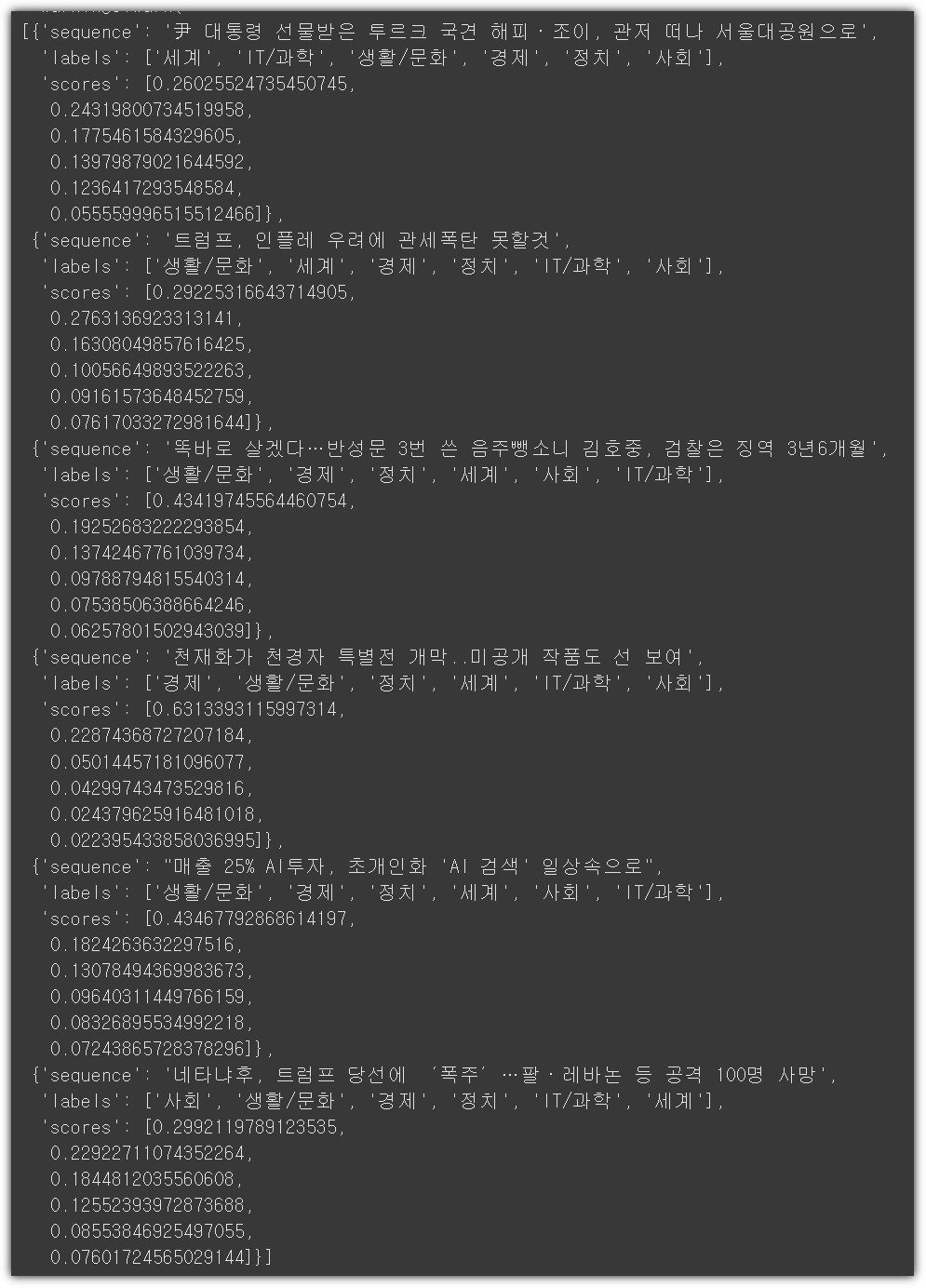
한글도 잘 알아듣고, 결과도 나름 괜찮네!?
현재 GitHub Models에서 사용해볼 수 있는 model들은 다음과 같다.
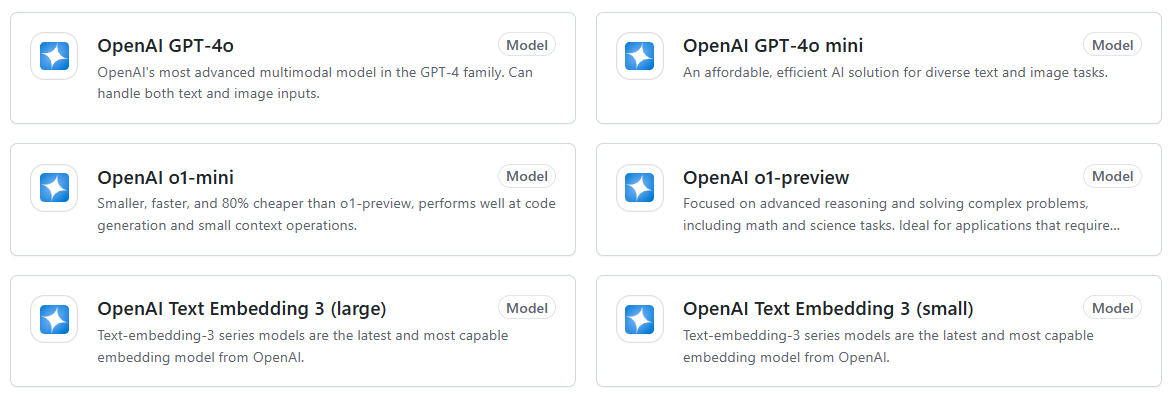
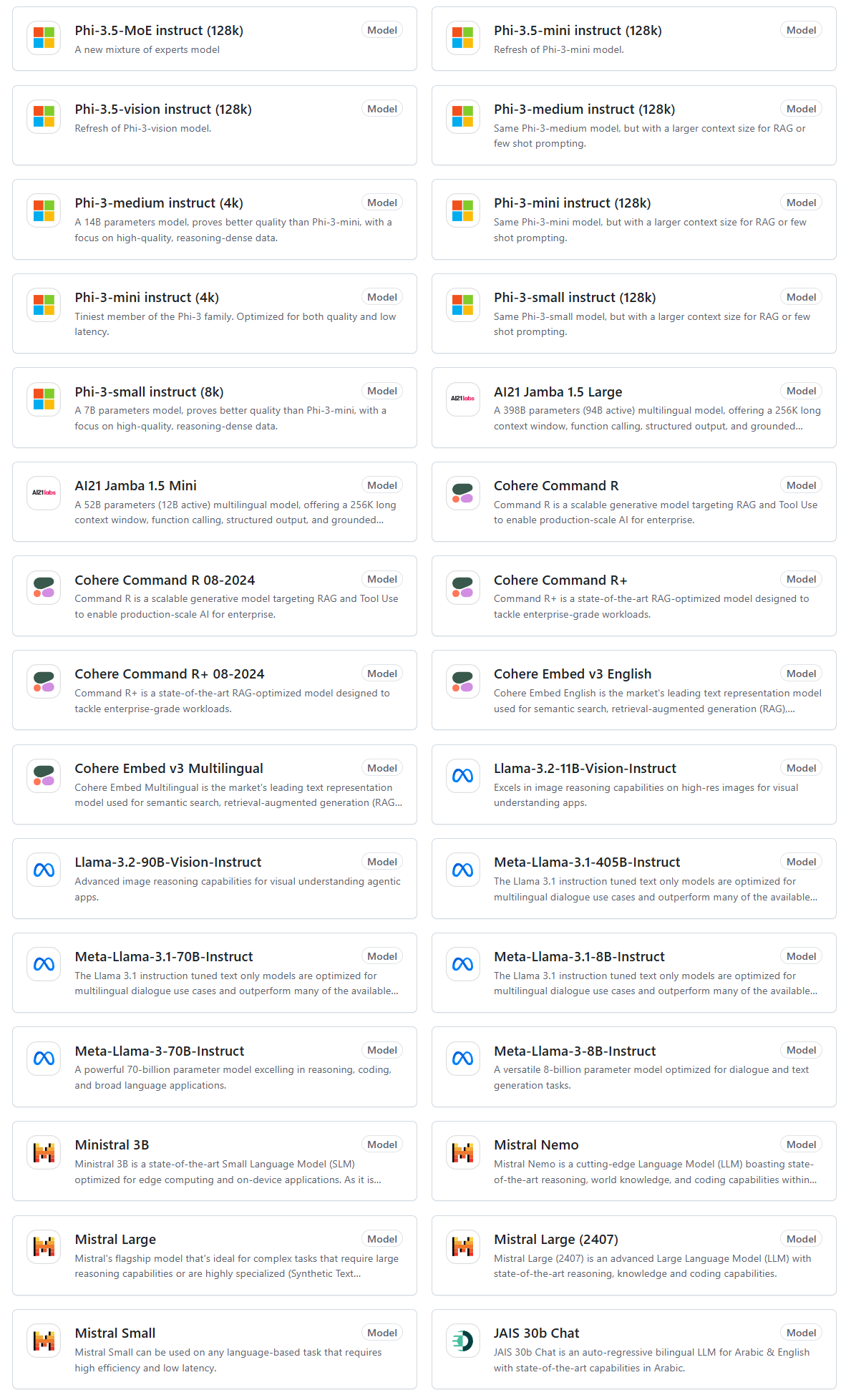
이걸 가지고 뭔가 재미난 것들을 해볼 수도 있을 것 같은데...
Preview 기간이 끝나면 당연하게도 유료 서비스가 될 것 같아서 ^^
'SCM > Git-GitHub' 카테고리의 다른 글
| Delta : git 결과 화면을 커맨드-라인에서도 예쁘게 만들기 (0) | 2024.11.24 |
|---|---|
| Git 최신 버전 설치하기 (Ubuntu 20.04) (1) | 2023.07.12 |
| git clone 용량 줄이기 & 필요한 파일만 작업하기 (1) | 2023.07.02 |
| Copilot Chat's Rules 유출(?) (0) | 2023.06.04 |
| GitHub Copilot X - Chat (0) | 2023.06.04 |