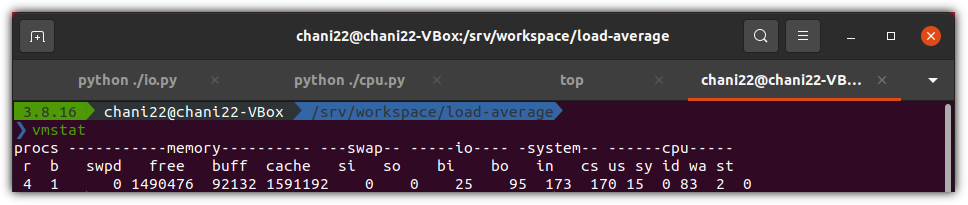
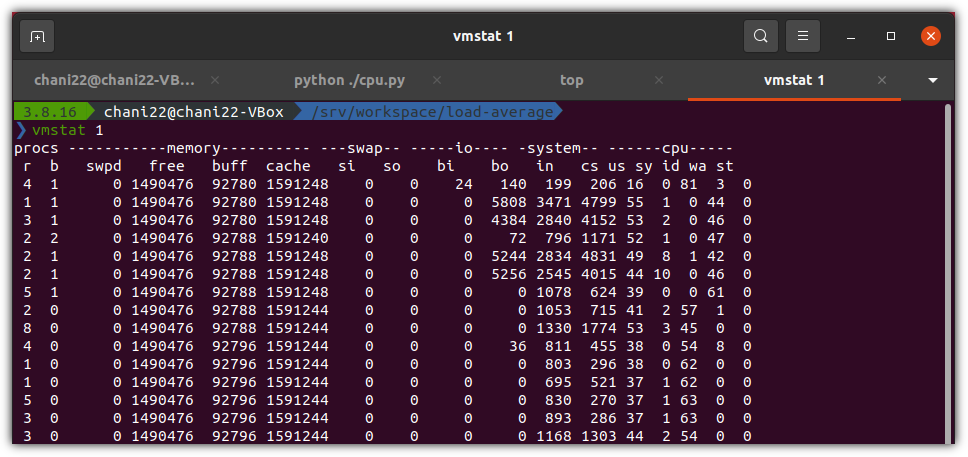
요즘 어떤 서비스의 아키텍처를 설계한다고 하면
당연히 "마이크로서비스 아키텍처(MSA)"를 떠올리게 될 정도로 MSA는 이제 거의 표준처럼 되어 버렸다.
그렇기에 당연히 우리는 "마이크로서비스 아키텍처(MSA)"를 공부해야 하고,
아마존에서 설계/아키텍처 부분 베스트셀러인 이 책을 살펴보는 것은 자연스러운 수순일 것이다 ^^

2017년도에 초판으로 출간된 책인데,
빠른 변화와 신기술의 등장에 발맞춰서 얼마전에 전면 개정판으로 새로운 책으로 거듭났다!

이 책의 저자는 특정 회사에 속하지 않고 프리랜서로 활동하시는 것 같고,
옮긴이는 포동 서비스를 언급하신 것으로 봐서 LG유플러스에서 근무하시는 것이 아닌가 싶다 ^^

책 제목에 "아키텍처"가 들어가있다보니
이 책의 대상독자로 제일 먼저 떠오르는 것이 "어?! 이 책은 Architect를 위한 책인가?"였다.
하지만, 뒤에 설명할 목차 등을 보면 알겠지만
이 책은 개발자부터 PL 및 C-level에게도 도움이 될 수 있는
"마이크로서비스 아키텍처(MSA)"에 대한 모든 것을 담고 있는 책이다.

이 책은 크게 "기초/구현/사람"이라는 3개의 부로 나뉘어져 있다.
응?
사람?

개인적으로는 2부 구현 부분에 가장 관심이 많이 간다.

정말 의외인 "3부 사람" ...
뭐 세상 모든 일은 다 사람하기 나름이니.... 가장 중요한 것이 사람인 것 맞지만.... 호오....!

회사를 다니고 있다면
처음부터 아무 것도 없는 상태에서 새롭게 설계하는 일 보다는
이미 모놀리스 아키텍처로 구성되어 있는 기존의 서비스를
마이크로 서비스 아키텍처로 마이그레이션하는 일이 더 많을 것이다.
그래서 "Chapter3. 모놀리스 분해" 부분에 관심이 많이 갔다.

아마존에서 괜히 베스트셀러가 된 것은 아니기에
책 구성과 내용은 정말 훌륭한 것 같다.
다만, 개인적인 취향으로 아쉬운 것은...... 풀컬러가 아니라는 점!?
ㅋㅋ 사실 책 주제 자체가 굳이 풀컬러일 필요가 전혀 없기에 이마저도 단점이 아닌 것 같다 ^^

책 내용이 훌륭하다는 예시를 들어보자면,
모놀리스의 유형 중 하나인 "모듈식 모놀리스"에 대한 설명을 한 번 살펴보자.
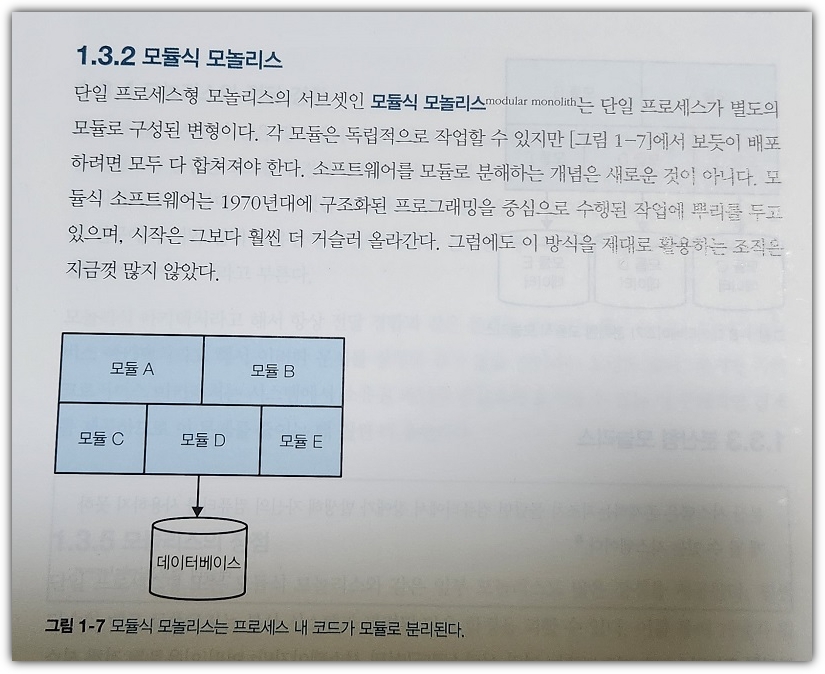
당연하게 보일 수도 있겠지만
개인적으로는 저렇게 모듈로 나눠서 구성하면
그것을 가지고 마치 마이크로 서비스인 것처럼 착각하는 경우가 종종 있다.
그런 부분에 대한 설명이 차분하게 잘 서술되어 있는 것을 보면 이 책의 내공이 정말 탄탄한 것 같다.
그리고 또, 개인적으로 애정하는 쿠버네티스...

마이크로서비스 아키텍처(MSA)하면 빼놓을 수 없는 짝꿍 쿠버네티스(Kubernetes) !!!
전반적으로 이 책은 정말 "마이크로서비스 아키텍처(MSA)"의 교과서라고 불리워도 무방할만큼
탄탄한 내공이 가득차 있는 정말 좋은 책이다.
쿠버네티스(Kubernetes)를 공부하는 분들도 필수 도서로 같이 공부하면 정말 많은 도움이 될 것이다!!!
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
'Books' 카테고리의 다른 글
| [디코딩] 챗GPT 개발자 핸드북 (0) | 2023.08.28 |
|---|---|
| [정보문화사] 파이썬과 엑셀로 시작하는 딥러닝 (0) | 2023.08.01 |
| [한빛미디어] 테라폼으로 시작하는 IaC (0) | 2023.06.25 |
| [한빛미디어] 직장인을 위한 챗GPT (0) | 2023.05.28 |
| [한빛미디어] 트랜스포머를 활용한 자연어 처리 (0) | 2023.03.26 |